
引用
AHMAD B, TAN B, PEARCE H, et al. FLAG: finding line anomalies (in code) with generative AI [A]. 2023. arXiv: 2306.12643.
论文:https://arxiv.org/abs/2305.08360
仓库: https://zenodo.org/record/8012211.
摘要
代码中总是存在安全和功能性的缺陷。识别和定位这些缺陷很困难,往往依赖于人工。在本文中,我们提出了一种新的方法FLAG来协助调试。FLAG基于生成式AI的词汇能力,特别是大型语言模型(LLM)来完成。其输入一个代码文件,然后提取并重新生成文件中的每一行并进行自我比较。通过将原始代码与LLM生成的替代代码进行比较,我们可以标记出显著的差异作为需要进一步检查的部分,其中文本距离和LLM的置信度也有助于这一分类。与该领域的其他自动化方法不同,FLAG是语言无关的,可以处理不完整(甚至无法编译的)代码,并且不需要创建安全属性、功能测试或规则定义。在本文中,我们使用LLM进行此类分类,并评估了FLAG在已知缺陷上的性能。我们使用了121个跨C、Python和Verilog语言的基准测试;每个基准测试都包含一个已知的安全或功能缺陷。我们使用OpenAI的两种最先进的LLM,即code-davinci-002和gpt-3.5-turbo进行实验。FLAG能够识别出101个缺陷,并帮助源代码的搜索空间减少到12-17%。
1 引言
当开发者的意图与他们的代码实现之间存在差异时,代码中就会出现缺陷。这些缺陷可能引入安全漏洞或功能缺陷。发现它们是一项费力的事情,尽管存在辅助工具,但它们通常只会在程序全部完成(或至少可以编译)时才有效,并且只关注一小部分缺陷类别。因此,在开发过程中,开发者及其团队应定期检查他们的工作。代码必须根据在源代码和注释中捕获的开发者意图进行检查,这种意图有时会显式地在诸如测试、断言或规则中捕获,有时会隐式地在执行代码进行模糊测试时捕获。
考虑到与正确代码相比,错误代码相对较少,我们假设开发者的意图主要在源代码和注释中体现,且仅偶尔会有疏漏。想象一位想要手动审查代码的开发者;如果一个程序只包含几行代码和注释,这可能开始是可行的。随着项目的增长,由于规模的原因,会变得越来越具有挑战性。找到缩小代码潜在问题区域的方法可以帮助开发者解决此问题。源代码和注释的意图能否用来标记代码中的问题,从而缩小需要手动审查的范围?为了回答这个问题,我们研究了使用生成性AI,特别是大型语言模型(LLM),来标记代码中的异常。
像GPT-3和Codex这样的LLM在许多文字类任务,包括编写代码方面展示了强大的能力。它们根据输入的持续产生输出。这些输入可以是现有的代码和注释。这提供了一个有趣的可能性:如果(a)代码中的错误行较少,并且(b)大部分代码与作者的意图一致,是否可以使用LLM来衡量给定的代码行是不是异常的?如果其回答是,这可能表明该行代码有缺陷。
基于这种直觉,我们提出了一种新颖的方法,使用LLM根据现有的代码和注释生成替代的代码行;将这些替代代码行与开发者的代码进行比较,以识别潜在的差异。本文的工作提供了对LLM研究的补充,即关于LLM是否可以用来帮助识别安全漏洞和功能缺陷形式的错误。我们的贡献如下:
我们提出了FLAG,一个利用LLM在通过比较原始代码与LLM生成的代码来检测错误的新颖框架。我们探索了源代码的特征及LLM的信息,以分辨代码是否存在错误。通过在多种语言中对主要LLM的不同模式进行实验,分析了这些特征的有效性。该工具和结果开源。2 技术介绍
FLAG一致性检查器依赖于LLM编写代码的独特能力。它的方法如图1所示。对于源代码中的每一行,FLAG生成一个相应的提示,该提示包括该行之前的代码(前缀),以及该代码行之后的代码(后缀,可选)。由代码和注释组成的提示输入到LLM,LLM输出单行代码或注释。将生成的行与原始行进行比较,产生用于分类原始行是否有缺陷的特征。这些特征提供两行之间差异的定量估计或LLM生成的行的置信度。被分类为可能有缺陷的行会被标记。对于给定的一行,FLAG流程有四个步骤:提示生成、行生成、特征提取和分类。
要对文件进行一致性检查,我们必须给FLAG一个开始检查的行。这样做是为了给LLM足够的上下文开始生成相关的代码和注释。通常,我们在代码头、初始注释以及模块和内部声明之后给出起始行号。此外,文件会被预处理以跳过空行,并识别开始检查的行之前是否存在注释。

2.1 提示设计
提示生成将源代码和待分类的行作为输入,并产生提示作为输出。这个提示被发送到LLM进行后续行生成,如图2a所示。这个过程对文件中的每一行重复进行。随着FLAG检查器前行,前缀增加而后缀减少。
我们将前缀和后缀的长度限制为最多50行,以保持在LLM的令牌限制之内。提示被调整以从LLM获得更好的响应,例如,如果LLM在应该生成代码时生成了注释,我们会将原始代码行的前几个字符附加到前缀上。这个过程可能会重复多次,直到获得有效的生成。后缀仅在模型支持插入模式时使用。

2.2 行生成
行生成以提示作为输入,并输出LLM生成的一行代码或注释。例如,在图2a中的提示生成的行显示在图2b中。在这个例子中,LLM的响应与原始代码行不同。它被标记为检查对象,揭示原始代码行包含了安全缺陷CWE-125,即越界读取。本例中使用的LLM是gpt-3.5-turbo。
LLM需要被引导产生合理的输出,因为有时LLM可能返回一个空行或返回一个注释而非代码。这个过程在算法1中描述。orig_lines是原始文件中行的列表。假设列表的索引从1开始。loc是我们希望LLM生成的行号。num_lines是原始文件中的总行数(经过预处理后)。我们将前缀和后缀初始化为空字符串,并使用max_pre_len和max_suf_len作为它们大小的限制。这样做是为了保持提示的令牌大小合理。在我们的实验中,我们将限制设置为50。为了克服偶尔的不可用输出,我们提示LLM再次产生响应,最多max_attempts次。这在第15-19行的Try和Catch块中体现。在第一次尝试中,提示LLM用给定的前缀和后缀产生一个响应。在第二和第三次尝试中,我们将LLM尝试生成的行的前5个字符附加到前缀来以引出非空响应。如果try块中有任何错误,错误将在第14行记录,然后返回到第10行。如果没有错误且第16和18行的条件不成立,则执行第20行。这表明一行已成功生成,并退出while循环。我们使用温度为0,max_token限制为150,top_p值为1,并且结束行字符作为停止令牌。

2.3 特征提取
特征提取接受原始和有缺陷的代码行,并输出特征。它们用于将原始行分类为有缺陷与否的定量值。它们代表两行之间的差异或生成代码的置信度。
特征
Levenshtein 距离(ld)是两个字符串之间的编辑距离。它考虑三种操作:添加、删除和替换。将一个字符串转换为另一个字符串所需的操作数量之和是莱文斯坦距离。完全匹配的结果是0。我们使用ld来比较代码行。由于目标是标记代码中的缺陷,我们将ld作为识别缺陷的主要标准。
BLEU是用来评估候选句子与参考句子的一个指标。完全匹配的结果是1,而完全不匹配的结果是0。我们使用它来比较注释,因为它们类似于自然语言。我们收集了BLEU-1到BLEU-4得分,但发现只有BLEU-1产生了有意义的数字。BLEU-2、BLEU-3和BLEU-4的质量微乎其微。在本文的其余部分,BLEU指的是BLEU-1。
注释距离(dfc)表示一行代码与其之前最近的注释的距离。如果该行也包含注释,则dfc的值为0。如果该行之前没有注释,则dfc没有值。我们只考虑代码之前的注释,因为这通常是代码的主流编写方式。
在LLM生成代码的上下文中,logprob是生成的令牌概率的对数。如果一个令牌更有可能被生成,它将具有更高的logprob,其最大可能值为0。如果一个令牌生成的可能性较小,它将具有更低的logprob,即负值且幅度更大。LLM倾向于“选择”有更高概率的令牌。对于生成的一行,我们取生成的令牌的logprobs的平均值,并称之为logprob。logprob接近0表示生成更有置信度,而更负的值表示置信度较低。
提取
为了获得这些特征值,原始行和生成的行被去除空白。如果行是代码和注释的组合,则代码和注释被分开进行比较。原始行的代码与生成的行的代码进行比较以计算ld。原始行的注释与生成的行的注释进行比较以生成BLEU指标。此外,如果原始行是一个注释,则最近的前一个注释的位置更新为当前行,并计算dfc。通过公共API无法获得gpt-3.5-turbo的logprob值, logprob值可用于code-davinci-002的实验。
2.4 分类
对于给定的文件,分类以特征作为输入并根据一些条件选择要标记的行。这些条件被称为标准,被标记的行被称为reported_lines。条件可以是包含性的或排除性的。包含性条件旨在将行纳入reported_lines集合。排除性条件用于从reported_lines中排除行。包含性条件在我们的FLAG框架中使用两个阈值,即Levenshtein距离上限(ld_limit)和注释距离上限(dfc_limit)。选择这些阈值的原因将在下文详细说明。ld_limit和dfc_limit共同作用以产生不同的标准。
使用ld_limit的原因:ld表示两段代码之间的差异。如果ld为0,那么两段代码是相同的。这意味着LLM没有其他建议,因此没有理由标记此代码。如果ld大于0,代码段是不同的,表明LLM指示与原始代码行的另一种可能性。这可能值得标记。但如果ld是一个非常高的数字,它可能表明LLM生成的是完全不同的东西。基于错误版本的代码通常与修正版本非常相似,我们使用ld的上限来针对那些不同但又不过于不同的生成代码。
使用dfc_limit的原因:dfc表示一行代码与它之前最近的注释的距离。如果代码附近有注释,即dfc值低,我们假设LLM会生成相关信息的代码,从而置信度更高。如果dfc大于dfc_limit,注释可能与代码行不相关,我们将其丢弃。使用dfc放宽了我们选择要标记的行的标准,因为具有大于ld_limit的ld值的代码行,如果其dfc小于dfc_limit,仍然可能被标记。
这种检测缺陷的副作用是reported_lines中有大量误报。我们通过采取一些措施来解决这个问题。我们检查reported_lines以移除可能是误报的被标记行。第一个措施是在生成和原始行中移除空白后重新计算ld。这消除了ld计算空白的误报。第二个是检查原始行是否只包含一个关键字。如果是这种情况,该行因为简单的关键字不能是错误的而从reported_lines中移除。第三个是使用logprob值作为排除的阈值。如果LLM对生成的行有大的负logprob值,它将从reported_lines中移除。我们在code-davinci-002的实验中使用阈值< -0.5来移除行。
3 实验和结果
为了评估FLAG一致性检查方法,我们使用两个OpenAI LLM设计了实验。第一个LLM是code-davinci-002,它针对代码完成任务进行了优化。对于code-davinci-002,没有系统提示,但如果除了前缀外还给出后缀。我们使用code-davinci-002进行了两个实验,分别是自动完成(无后缀)和插入(有后缀)模式。第二个LLM是gpt-3.5-turbo。它在GPT-3的基础上进行了改进,能够理解和生成自然语言或代码。在本文稿编写时,它是“最能力强大的GPT-3.5模型”。它是一个指导性模型,其角色是根据给定的系统提示来确定的。给出系统提示后,模型然后接收指定任务的消息。我们对gpt-3.5-turbo进行了两次实验。第一次实验没有使用任何系统提示,我们将这种模式称为自动完成。第二次给出了如下系统提示:“你是一位熟练的AI编程助手。完成下一行代码。”这种模式称为指导完成。
一个实验涉及选择一套特定的LLM和模式,例如,code-davinci-002在插入模式下,使用它对所有121个基准测试执行我们的一致性检查方法。我们总计为2个LLM及其2种完成模式的可能组合运行了4次实验。为了评估一个实验,我们关注3个指标。第一个是检测到的缺陷数量(DD)。对于给定的一组输入,DD是正确识别的缺陷总和。它实际上是真正的正例(TP),最大可能值为121,即所有来源的总缺陷。第二个是误报率(FPR)。对于给定的一组输入,FPR是错误高亮的行数与总行数的比例。第三个是召回率,即真正例与总正例数的比率。
3.1 结果
结果在表4中展示。我们根据来源和标准细分每个实验的结果。对于C语言,我们将C1细分为C1-CVEs和C1-CWEs。通过展示不同标准的结果,我们说明了数据如何基于标准复杂性而变化。我们提出了标准2,因为它平衡了TPR和FPR,并使用了3.3.1节中的包含性和排除性特征。
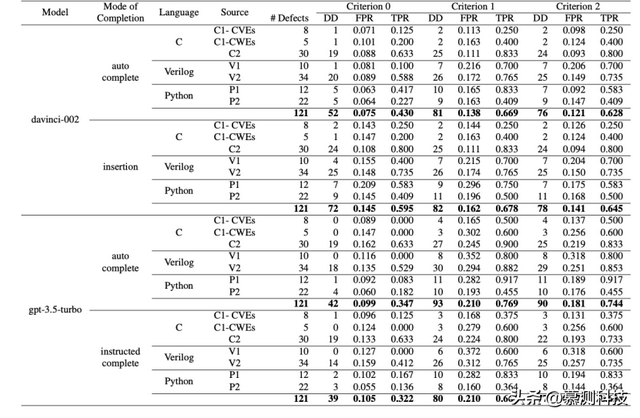
gpt-3.5-turbo在检测缺陷方面有更大的能力,但code-davinci-002的误报较少。对于标准2,gpt-3.5-turbo在TPR方面比code-davinci-002表现得更好。它能够在自动完成模式下检测到90个缺陷,在指导插入模式下检测到77个,而code-davinci-002在自动完成模式下检测到76个,在插入模式下检测到78个。code-davinci-002在FPR方面表现得更好。与gpt-3.5-turbo在指导完成和自动完成模式下的0.172和0.181相比,它在自动完成模式下的FPR为0.121,在插入模式下为0.141。
3.2 对安全漏洞的深入探究
由于我们对FLAG的安全应用感兴趣,我们在图3中对安全漏洞的检测进行了详细分析。35个安全漏洞中有16个被两个LLM在两种模式下检测到,29个被至少一个LLM在一种模式下检测到。在自动完成模式下,gpt-3.5-turbo表现最好,检测到了26个,而在指导完成模式下为22个,在自动完成模式下的code-davinci-002为19个,在插入模式下的code-davinci-002为19个。Python安全漏洞是LLM检测得最好的。所有Python的缺陷都被发现了。其次是Verilog和C。进一步的检查让我们对这种情况产生了一些想法。首先,与其他来源相比,P1源文件的大小较小。它的平均文件大小为17行,而C1和V1分别为1426和249行。此外,较小的文件大小允许LLM将在漏洞之前的整个源代码作为提示的一部分,为其提供了文件预期功能的完整上下文。其次,P1中的基准门设计用于安全评估,而V1和C1中的基准是专门为安全设计的基准和真实代码的结合。V1中的6个基准来自SoC实现的真实代码,而C1中的8个基准来自真实代码。这也解释了为什么FLAG在C1-CVEs上的表现不佳。

我们对比了FLAG在功能和安全漏洞之间的性能。根据图4中的数据,可以推断FLAG检测功能性漏洞的效果比安全漏洞更好。功能性漏洞的平均TPR为0.689,而安全漏洞为0.676。它们的平均FPR较安全漏洞为低,分别为0.176和0.271。进一步观察发现,Python是一个例外,P1的TPR比P2高。对于gpt-3.5-turbo,P1的TPR是P2的两倍,表明gpt-3.5-turbo在检测Python中的安全漏洞方面表现良好。我们将C1-CVEs的数据排除在分析之外,因为这些基准的行数是其他基准的许多倍,会使平均值偏向C1-CVEs。

3.3 详细分析
从C0到C2标准如何影响DD和AFPR?从C0到C1,DD和FPR都增加了。这是因为ld_limit从10放宽到20,且使用dfc_limit包含可能超过ld_limit的行。平均而言,DD从51增加到84,而FPR从0.106增加到0.18。从C1到C2,DD和FPR都减少了。这是因为从reported_lines中移除了被高亮的行,一些误报被移除,但一些真正的正例也被移除了。平均而言,DD从85减少到80,而FPR从0.18减少到0.154。虽然DD减少了4.76%,但FPR减少了14.6%。这表明此操作在提高一致性检查性能中的重要性。
不同完成模式如何影响DD和AFPR?我们本能地会认为插入模式应该比自动完成模式做得更好,因为LLM除了前缀外还可以访问更多形式的后缀信息。此外,gpt-3.5-turbo在指导完成模式下产生“下一行代码”应该比自动完成模式表现得更好,因为生成代码而不是代码解释的可能性应该更高。图6比较了在C2(20,10)下不同完成模式的表现。对于code-davinci,插入模式确实让我们检测到了2个额外的缺陷,但代价是FPR增加了16.5%。这可能不是一个有价值的权衡。对于gpt-3.5-turbo,指导完成模式比它的自动完成模式做得明显更差。它检测到的缺陷少了13个,而FPR只减少了4.97%。
ld_limit和dfc_limit如何影响DD和AFPR?在我们的检查方法中突出显示行的两个主要决定因素是ld_limit和dfc_limit。由于它们可以取任何连续值,除了考虑C0到C2标准中讨论的特定值外,还需要进行更深入的分析。我们对code-davinci-002模型在自动完成模式下对这两个限制进行扫描,以了解它们对DD和FPR的影响。图7a和图7b分别展示了在ld_limit从0到30和dfc_limit从0到50的范围内,不同ld_limit和dfc_limit组合下DD和FPR的变化。我们观察到,ld_upper_limit在影响DD和FPR方面更为显著。ld_upper_limit的变化比dfc_limit的等量变化引起的DD和FPR的变化更大。在增加ld_limit时,DD和FPR也更早地饱和。当ld_limit为30时,DD大致饱和,因为在该值下改变dfc_limit的影响有限。类似地,当ld_limit为20时,FPR大致饱和。将它们扩展到ld_limit=50,DD和FPR的最大可能值分别为90和0.14。我们还观察到,在较小的ld_limit和dfc_limit值时,DD和FPR更为敏感。在ld_limit为15和dfc_limit为10时,我们可以达到DD最大值的80%,即72。同样,在ld_limit为15和dfc_limit为25时,我们可以达到FPR最大值的80%,即0.11。这种分析有助于估计在设计类似工具时应该考虑的范围。

通过放大dfc_limit的较小值,并将ld_limit的值扩展到100,如图8所示,可以进一步探索此问题。对于特定的dfc_limit,随着ld_limit的增加,DD和FPR都会增加。虽然两者增加的速率都在减小,但有一个点,超过这个点,DD的增加率显著低于FPR的增加率。这是因为超过该点后,获取更多缺陷的好处会被增加误报的成本所压倒。相反,过小的ld_limit值找不到足够的缺陷。图8中的高亮区域表明一致性检查方法提供“还可以”的结果的值范围。类似地,保持ld_limit不变并扫描dfc_limit也提供了相似的结果。然而,对于不同的ld_limit值,DD和FPR的值没有足够的区分度。

自然地,人们可能会问什么是ld_limit和dfc_limit的最佳组合?开发者愿意接受多少误报以换取检测到更多缺陷的好处是主观的问题。我们在热图中展示了TPR和FPR之间的权衡。决定使用哪些限制的一种方法可能是首先取决于能够承受的误报数量。例如,如果愿意在检测到每个缺陷的情况下查看100行中的7行,即FPR为0.07,可能会选择(ld_limit,dfc_limit)为(5,10),如图7b所示。在这些限制下,将能够定位到我们基准中覆盖的121个缺陷中的58个。
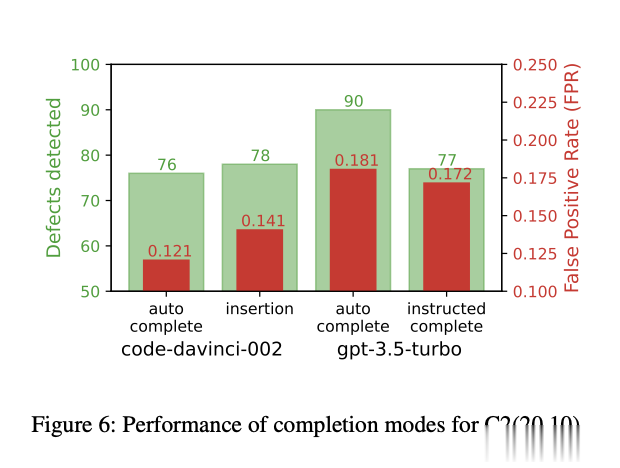
LLM相对于随机预测表现得怎么样?我们以不同的ld_limit阈值形式,在接收者操作特征(ROC)曲线上表示真正率(TPR)和误报率(FPR)。我们用code-davinci-002的自动完成模式来实现这个目的。在我们的实验中,我们为ld设置了0的硬性下限。这意味着,一些ld为零的行永远不会被计为真正的正例或误报,导致ROC曲线不完整。这种情况在图9a中显示。然而,ROC曲线位于TPR==FPR线之上,显示我们的分类方法优于猜测。为了完整性,如果我们使用-1的下限和1000的上限,我们可以获得TPR和FPR为1,因为所有行都会被高亮显示为包含缺陷。这在图9b中表示。
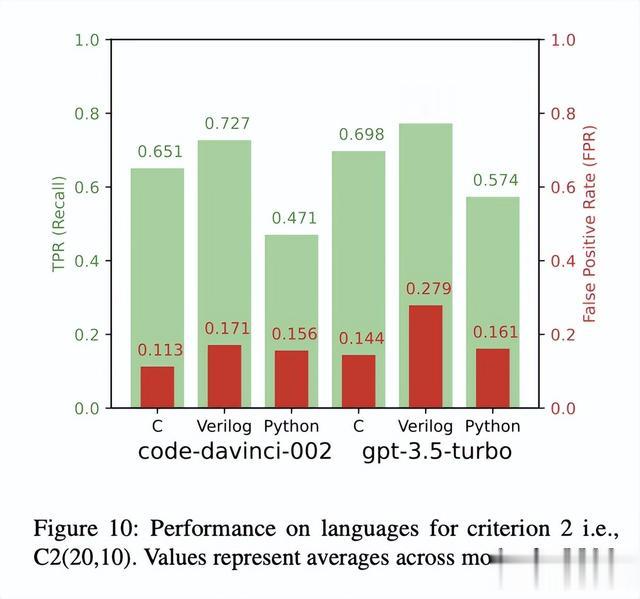
某种语言的缺陷是否比其他语言更容易检测?根据图10中的数据,我们可以得出结论,FLAG一致性检查器在C语言上表现最好,在Python上表现最差。尽管C的TPR略低于Verilog的两个LLM,但它的FPR显著较低。虽然它的TPR低10.5%,但它的FPR比Verilog低48.4%。Python的TPR最低,仅次于FPR为第二低的两个LLM。这是令人惊讶的,因为我们预期训练数据中大量的开源Python代码会转化为比在Verilog上的更好表现。这可能是因为Python的22个基准是真实代码,而Verilog只有6个。
注释有多大帮助?我们通过分析真正例和误报的dfc和BLEU分数来表明注释的作用。dfc表示一行代码与注释的接近程度,而BLEU分数表示LLM产生的注释的质量。图11显示了真正例和误报之间dfc的不同。这里的数据不包括dfc不可用的例子,即在有关行之前没有注释的情况。在两种情况下,大部分数据都位于dfc的最小值范围内。这是因为我们研究的数据集中经常编写注释。真正例的dfc平均值为18.4,相比之下,误报的平均值为327.9。当有关行更接近注释时,LLM在分类上做得更好。真正例的dfc标准偏差要小得多,为47.7,而误报的为632.1。因此,误报覆盖了更广泛的范围。

平均dfc或平均bleu分数是否与检查器的成功相关?图12展示了上一个注释的BLEU分数在真正例和误报之间的差异。数据不包括在行之前没有注释或LLM未能产生注释的行。对于正在分析的代码行,FLAG跟踪它之前的最近一条注释。FLAG将LLM在这一行产生的注释与原始注释进行比较,以计算上一个注释的BLEU分数。高值表明LLM正按照编码者的意图正确进行。真正例的上一个注释的BLEU分数平均值为0.407,与误报的0.473相比较。这表明上一个注释的BLEU分数在分类中并不起决定性作用。真正例的上一个注释的BLEU分数的标准偏差为0.193,与误报的0.236相似。

转述:李昕