
英文题目: Adaptive Event-Triggered Optimal Tracking Control for Wheeled Mobile Robots Considering Force-Velocity Hybrid Constraints
中文题目: 考虑力-速度混合约束的轮式移动机器人自适应事件触发最优跟踪控制
作者: Tao Ren,Shu Li,Yan-Jun Liu,Feng Wan,Lei Liu,Cong Sun
作者单位: 辽宁工业大学、澳门大学、东北大学
期刊: IEEE Transactions on Intelligent Transportation Systems(IF 8.4 中科院一区,JCR Q1)
发表时间:2025年4月25日
链接:https://ieeexplore.ieee.org/document/10977727
引文格式: Ren T, Li S, Liu Y J, Wan F, Liu L, Sun C. Adaptive event-triggered optimal tracking control for wheeled mobile robots considering force-velocity hybrid constraints[J]. IEEE Transactions on Intelligent Transportation Systems, 2025: 26(8): 11945-11956.
01 全文速览
轮式移动机器人在硬质地面上的轨迹跟踪已经比较成熟,但一旦进入软可变形地面,问题会立刻复杂很多。轮地相互作用会引入打滑、侧滑、速度损失和驱动力矩波动,速度状态和力矩输入不再各管各的,而是变成了彼此耦合、同时受限的混合约束系统。
这篇论文抓住的,正是这个常被简化处理的问题。作者先建立考虑打滑和侧滑的轮式机器人模型,再把复杂约束转成可处理的形式,接着把 PI-ADP、神经网络和动态事件触发机制接到一起,最终完成软地形下的最优跟踪控制设计。
核心亮点
✅ 把力和速度的耦合约束单独拎出来处理。
论文关注的不是普通状态约束,而是软地形下速度和驱动力矩共同受限、相互影响的问题。
✅ 设计了带约束信息的动态事件触发机制。
触发阈值随系统状态变化,并通过内部动态变量调节更新频率,同时避免了 Zeno 行为。
✅ 把 PI-ADP 放进事件触发框架里。
最优控制律和网络权值不再连续更新,而是在触发时刻更新,减少了计算和资源消耗。
✅ 结果不只说明能跟踪,还说明约束守住了。
轨迹、速度、误差、输入和约束结果都给得比较完整,事件触发机制节省了约 70% 的系统资源。
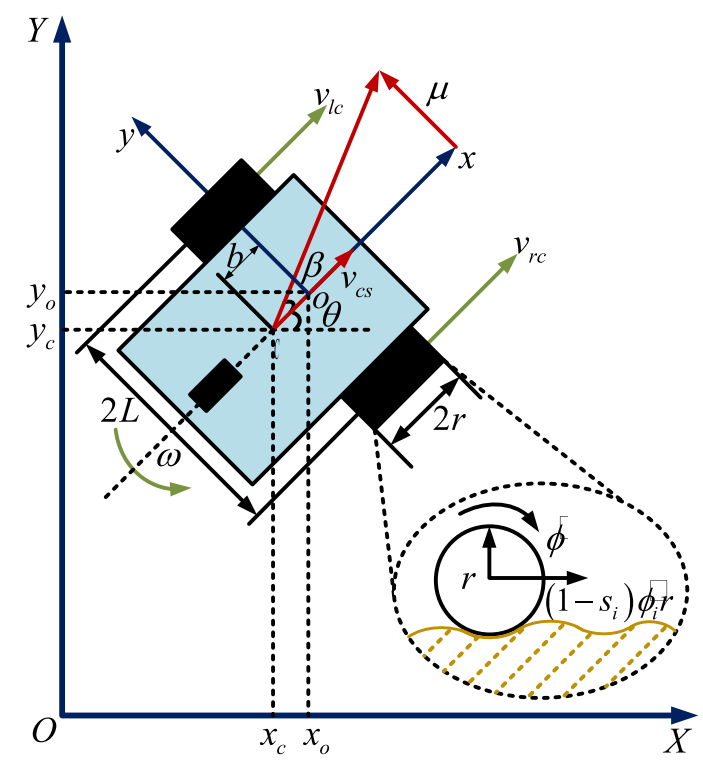
图1:考虑打滑和侧滑的轮式移动机器人模型。图中给出了侧偏角、滑移率、理论速度与实际速度之间的关系。
如图1所示,论文从一开始就没有假设机器人处在理想纯滚动状态,而是把打滑、侧滑和滑移损失都显式纳入了运动学描述。
02 研究内容
🚜 2.1 先把软地形里的非理想运动写进模型
在不考虑打滑和侧滑时,机器人满足标准非完整约束,并有轮速到车体速度的关系
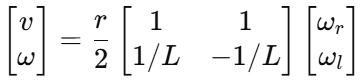
进一步得到左右轮的理论速度

但软地形下,轮速不再等于真实车体速度。论文引入滑移率和侧滑速度后,将系统改写为
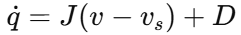
其中 v_s是由滑移带来的速度损失项,D 是由打滑、侧滑和约束破坏共同形成的不匹配扰动。也就是说,后续控制器面对的,不是理想轮式机器人,而是一个速度会掉、方向会偏的系统。
🧠 2.2 动力学模型把力-速度耦合真正写清楚了
在动力学部分,论文通过拉格朗日方法得到控制导向形式
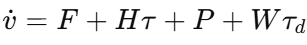
这里,
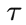
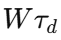
这一步最关键的意义在于,论文明确指出软地形中的速度变化和驱动力矩不是独立变化的。速度剧烈波动会导致驱动力矩大幅变化,而驱动力矩又反过来影响系统速度状态,这就是文中所说的力-速度混合约束。
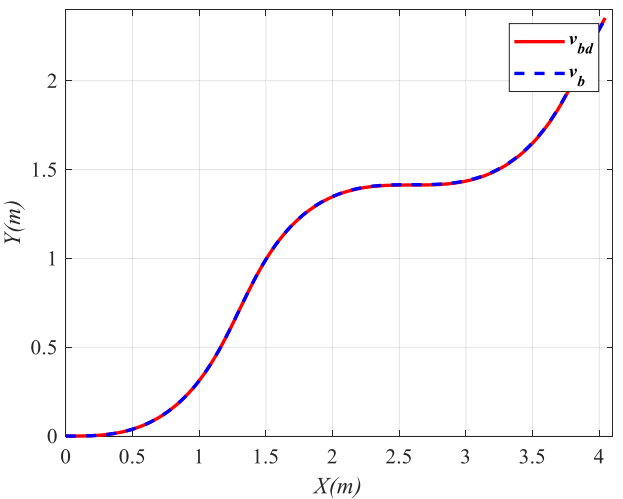
图2: 轮式机器人对参考轨迹的跟踪效果。
在后续仿真中,图2给出了机器人对参考轨迹的整体跟踪结果,实际轨迹与期望轨迹基本重合,说明控制器在软地形复杂扰动下仍能完成路径跟踪任务。
🎯 2.3 复杂约束没有直接塞给控制器,而是先转成增广状态
论文考虑的一般不等式约束为
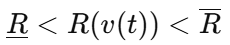
随后通过引入松弛因子,把不等式改写为等式形式
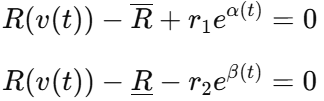
这样,
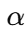

可得到误差系统
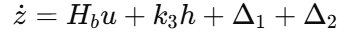
到这一步,原本复杂的软地形约束问题,被整理成了适合控制设计的误差系统。
⚙️ 2.4 控制器分两层,先补偿,再优化
论文没有让最优控制器直接面对全部不确定性,而是先引入神经网络去逼近未知项:
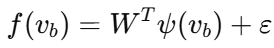
然后把控制输入拆成
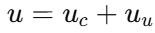
其中 u_c 是前馈补偿控制,用于处理未知动力学和辅助系统项;u_u 才是后续通过 ADP 设计的最优控制项。经过前馈补偿后,系统进一步被压缩成
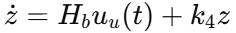
这种结构很值得注意。它不是把所有困难都甩给最优控制,而是先用基础控制层处理未知项和补偿问题,再让最优控制层专注于性能提升。
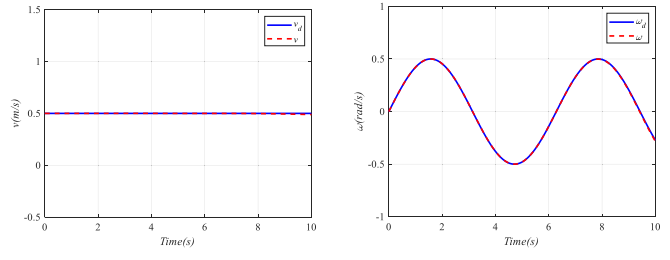
图3: 线速度与角速度的跟踪结果。
图3进一步给出了速度和角速度的跟踪表现,可以看到两者都能较好贴近期望信号,这说明前馈补偿与最优控制结合后,不只是轨迹层面跟得上,速度层面也能保持稳定。
📉 2.5 事件触发最优控制,重点不在少发指令,而在只在必要时更新
论文定义的性能指标为
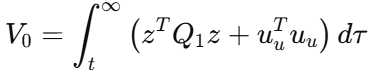
对应 HJB 方程
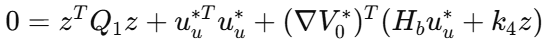
最优控制律写成
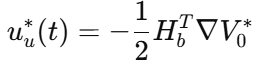
由于 HJB 直接求解困难,论文采用策略迭代 PI。与此同时,引入事件触发误差
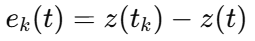
并设计动态阈值
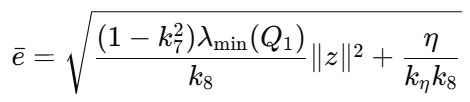
对应触发条件
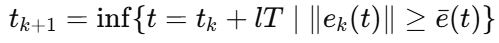
这意味着控制器和网络权值不是连续更新,而是在满足触发条件时才更新。对复杂约束场景来说,这种做法兼顾了性能和资源节约。
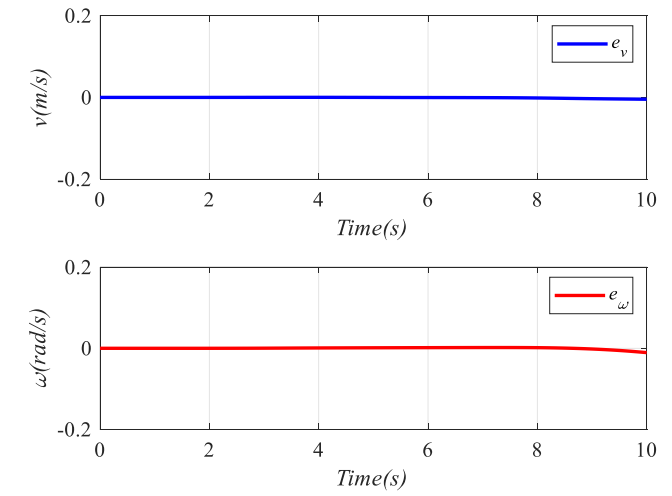
图4: 系统状态跟踪误差变化。
图4展示了状态跟踪误差的演化结果,可以看到误差逐步减小并保持有界,这从误差层面支撑了控制器的稳定性。
🧩 2.6 critical网络和执行网络分别做什么
论文中,评论家网络用来逼近性能函数:
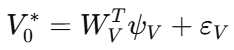
执行网络则用于逼近最优控制律:
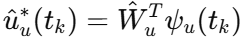
前者负责学代价函数,后者负责学控制策略,两者的权值都只在事件触发时更新。这样,ADP、神经网络和事件触发机制被真正接到了同一个闭环框架里。
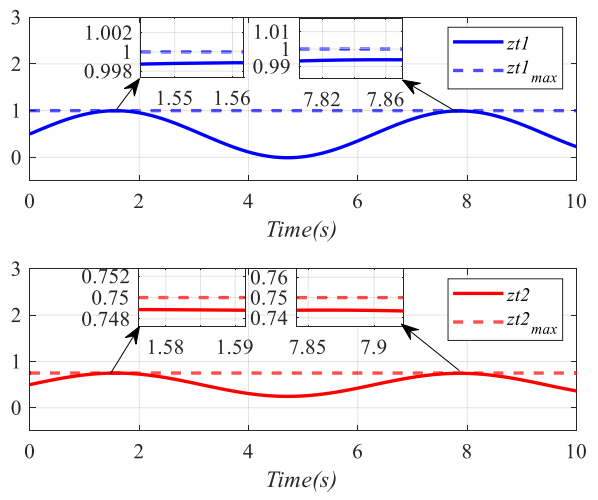
图5: 复杂约束的保持结果。
图5非常关键,它直接给出了复杂状态变量在控制过程中的演化结果。可以看到,系统状态始终保持在约束边界之内,这也是整篇论文最核心的结果之一。
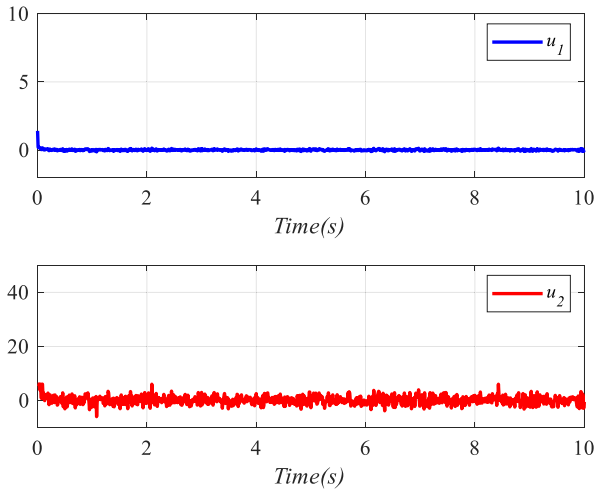
图6: 控制输入更新结果。
图6给出了控制输入的变化过程,对应前馈补偿和最优控制共同作用下的实际输入演化。
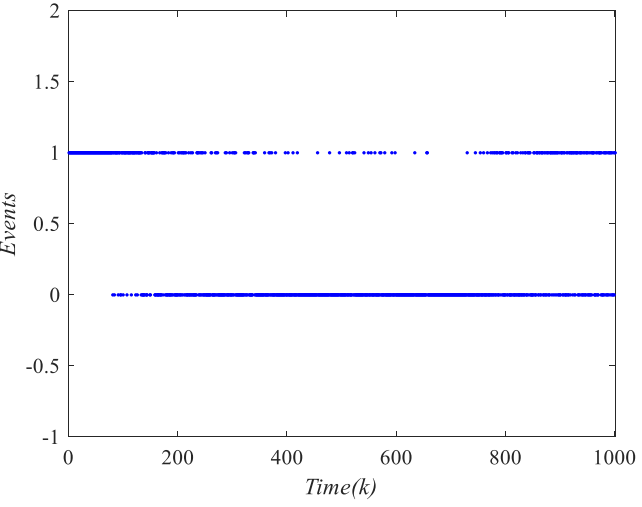
图7: 事件触发结果。
图7展示了事件触发行为本身,更新是离散发生的而不是连续发生的,这也是系统能够节约资源的重要原因。
03 创新点
✅ 3.1 软地形中的力-速度混合约束被作为核心问题单独处理
这篇论文没有只停留在普通状态约束或输入约束,而是正面处理软地形中速度与力矩耦合变化的问题。
✅ 3.2 设计了包含约束信息的动态事件触发机制
触发阈值随着系统误差和内部动态变量变化,而不是固定常数,更适合复杂环境下的控制需求。
✅ 3.3 将 PI-ADP 与事件触发结合起来
最优控制与网络学习都只在触发时刻进行更新,缓解了连续优化带来的计算压力。
✅ 3.4 从建模到验证的证据链较完整
轨迹、速度、误差、输入、约束和触发行为都给出了结果,逻辑是闭合的。
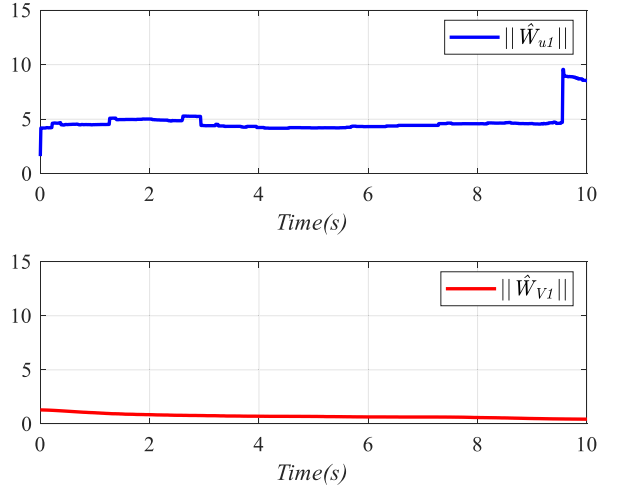
图8: 评论家网络与执行网络权值更新结果。
图8给出了评论家网络与执行网络权值的更新过程,说明网络参数在学习过程中保持有界,这为闭环稳定性提供了进一步支撑。
04 总结与展望
这篇论文最值得注意的地方,不在于又提出了一个新的控制器名字,而在于它把问题抓得比较准。软地形中的轮式机器人,真正难的不是单纯轨迹跟踪,而是打滑、侧滑、速度状态和驱动力矩会一起变化。论文围绕这一点,把建模、约束重构、前馈补偿、PI-ADP 最优控制和动态事件触发接成了一条完整链路。仿真结果表明,机器人能够较好跟踪参考轨迹,速度与角速度保持稳定,复杂约束始终未被突破,同时事件触发机制节省了约 70% 的系统资源。
未来研究将聚焦于以下几个方向:
其一,是从数值仿真走向真实软地形平台实验,在真实软土、沙地和松散路面中验证控制器有效性。
其二,是进一步研究事件触发参数整定,让性能与资源节约之间的平衡更可控。
其三,是把方法推广到更复杂扰动、更强不确定性和更复杂轮地作用环境中。
软地形轮式机器人的难点是事件触发最优控制效率,还是复杂环境下的约束自适应处理?欢迎在留言区聊聊你的判断。
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨