
英文题目:Reinforcement Learning Control for Manipulation of Flexible Payloads by Multiagent Robot Systems With Event Triggering Mechanism
中文题目: 具有事件触发机制的多智能体机器人系统柔性负载操纵强化学习控制
作者:Shuyang Liu,Bing Qiao,Zhijie Liu,Zhijia Zhao,Wei He
作者单位: 长春工业大学、北京科技大学、广州大学、北京信息科技大学等
期刊:IEEE Transactions on Systems, Man, and Cybernetics: Systems(IF 8.7中科院一区,JCR Q1)
发表时间:2026年2月19日
链接:https://ieeexplore.ieee.org/document/11400715
引文格式:Liu S Y, Qiao B, Liu Z J, et al. Reinforcement learning control for manipulation of flexible payloads by multiagent robot systems with event triggering mechanism[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2026: 1-13.
01 全文速览
多机器人协同搬运,表面看是在做一致跟踪,真正难的却往往藏在负载里。
一旦负载是柔性的,问题立刻变味。机械臂不仅要跟着目标走,还得压住柔性振动;不仅要多个智能体之间动作一致,还得考虑网络通信别太频繁。跟踪、抑振、协同、通信,这四件事放在一起,控制难度一下子就上来了。
这篇论文做的,就是把这几件事放进同一个控制框架里。作者研究的是由多个机器人智能体组成的系统,每个智能体都由三连杆刚性机械臂和一个柔性负载组成,柔性负载被建模为 Euler-Bernoulli 梁。控制目标很明确:让所有机器人实现一致跟踪,同时压制负载振动,并通过事件触发机制减少通信更新频率。
更值得注意的是,这篇文章不是简单套一个强化学习标签。它给出的,是一套比较完整的控制链条:
先把刚柔耦合系统从无限维 PDE 模型降成有限维模型
再用 actor-critic 强化学习处理不确定项和优化控制输入
最后叠加事件触发机制,减少多智能体之间的通信负担
🔥 核心亮点
✅ 问题设定更接近真实协同操作。
论文研究的不是单个机械臂搬柔性负载,而是多智能体机器人系统协同操纵柔性负载,这比传统单机器人模型更贴近实际应用。
✅ 把一致跟踪和振动抑制放进了同一个目标里。
不是只让末端位置跟上,也不是只顾着压振,而是两件事一起做。
✅ 用 actor-critic 强化学习替代传统固定模型依赖。
面对柔性负载变化带来的模型不确定性,作者没有继续走纯模型或传统 RBFNN 路线,而是引入 RL 来同时估计不确定项并优化控制。
✅ 把事件触发机制真正嵌进控制律。
不是事后讨论通信节省,而是从控制设计阶段就引入相对阈值触发规则,减少控制更新频率和网络负担。
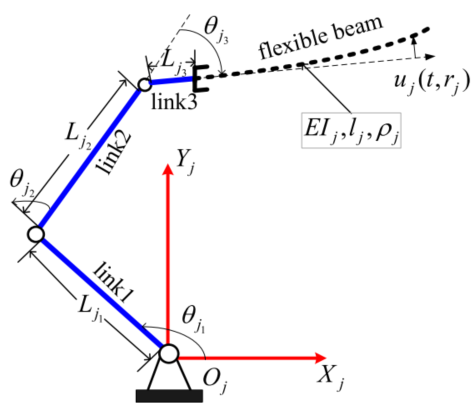
图1:处理柔性有效载荷的机械手的代理系统图。
如图1所示,论文研究对象是一个典型的刚柔耦合机器人智能体:三连杆刚性机械臂末端连接柔性负载,系统本身就同时带有多体动力学和柔性振动特征。
02 研究内容
🎯 2.1 先别急着谈控制,真正的难点在系统本身就很复杂
这类系统首先难在建模。
机械臂是刚体系统,柔性负载却是分布参数系统。两者耦合在一起后,系统天然带有 ODE-PDE 混合特征。直接基于 PDE 去做控制分析很难,尤其是当系统还要做多机器人一致协同时,难度会继续上升。
论文这里采用了一个很经典但依然有效的思路:
用假设模态法把柔性负载的无限维模型近似成有限维模型。
柔性负载形变被写成前 N 阶模态的叠加:
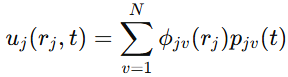
这里,
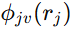
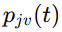
进一步,作者定义系统状态为
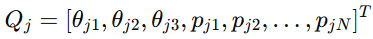
最终得到第 j 个机器人智能体的有限维动力学模型
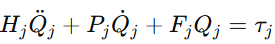
这个式子很关键。它说明控制对象不再只是机械臂三个关节角,而是已经把柔性模态一并纳入状态中。也就是说,后面的控制器从一开始就是冲着刚柔协同去的。
🧠 2.2 这篇论文的核心,不只是强化学习,而是 actor-critic 怎么嵌进控制闭环
论文采用的是 actor-critic 结构。
其中,critic 网络负责逼近代价函数,actor 网络负责逼近系统中的未知模型项,并生成控制输入。作者这里的处理,不是把 RL 当成一个黑箱策略搜索器,而是让它和 Lyapunov 控制框架结合起来。这个味道其实更像控制领域熟悉的自适应智能控制,而不是纯数据驱动 RL。
为描述多智能体一致跟踪误差,论文先构造了辅助变量
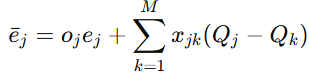
它的物理意义很清楚:
既包含机器人自身对期望信号的误差,也包含与其他智能体之间的一致性误差。
然后,作者定义长期代价函数
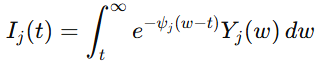
其中瞬时代价函数为
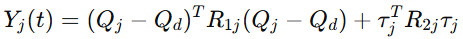
这个代价函数很有代表性。它不是只惩罚跟踪误差,也把控制输入一并纳入优化目标。往控制语言里翻,就是既要跟得准,也要控得稳。
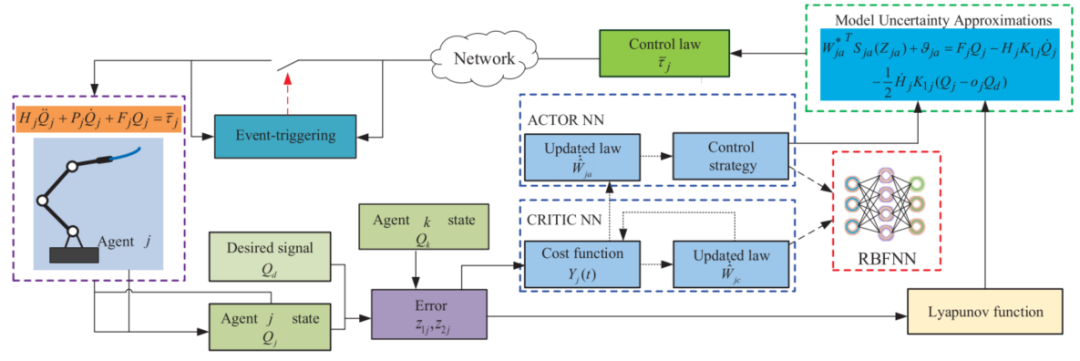
图2:基于actor-critic 神经网络的强化学习控制结构图。
如图2所示,整套方法的核心结构非常清楚:误差经过 critic 网络评估代价,actor 网络输出控制策略,同时结合 RBFNN 近似不确定项,形成一个带学习能力的闭环控制框架。
⚙️ 2.3 控制律真正精彩的地方,在于把未知项估计、抑振和一致跟踪揉到了一起
在控制器设计里,论文先定义了两层误差变量:
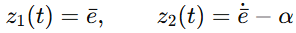
其中虚拟控制项取为
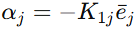
这一步其实很熟悉,就是典型的递阶设计思路:
先让第一层误差收敛,再把第二层误差和真实控制输入联系起来。
接着,作者把系统中的未知动力学项统一写成神经网络逼近形式:
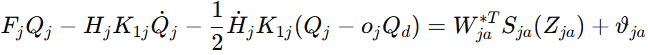
有了这个表达后,actor 网络就能在线逼近不确定项,最终得到事件触发下的控制律。论文给出的关节控制输入形式为
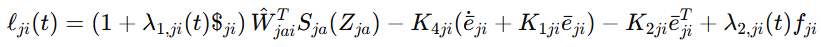
虽然公式看起来长,但核心逻辑并不绕:
学习网络去补未知项
反馈项去压误差
结构设计里天然包含一致跟踪和振动抑制目标
最外层再叠加事件触发机制控制更新频率
这也是这篇文章最像控制论文,它的强化学习,不是漂在外面,而是扎进了动力学和稳定性分析里。
📡 2.4 事件触发不是配角,它直接决定这套方法能不能用于多机器人
多智能体系统一旦上通信网络,事件触发就不再是锦上添花,而是必须认真处理的问题。
论文这里采用了基于相对阈值的事件触发策略。控制输入在触发时刻之间保持常值:
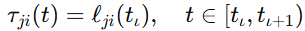
下一次触发时刻满足
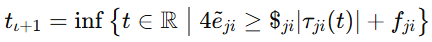
这个规则背后表达得很直接:
只有当当前误差相对控制量偏差达到阈值时,才更新控制输入。否则,就不必频繁发消息。
从工程上看,这件事很重要。因为多机器人系统真正落地时,通信资源从来不是无限的。控制器算得再好,如果更新频率太高,最终还是会卡在网络和执行层。
🛡️ 2.5 这篇论文没有止步于方法提出,而是把稳定性也补全了
很多读者看到强化学习控制,会下意识担心两个问题:
学出来的策略稳不稳
多智能体刚柔耦合系统会不会很难证明
这篇论文对这两个问题都正面回应了。作者构造了 Lyapunov 函数,把误差项、actor 网络权值误差和 critic 网络权值误差统一纳入分析,最终证明闭环系统满足 SGUUB,也就是半全局一致最终有界。
论文的关键结论可以概括为:
在合适参数条件下,
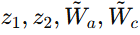
对控制领域读者来说,这一点很关键。因为它意味着这项工作并不是只给出一个仿真上能跑的 RL 控制器,而是把稳定性分析补到了可以接受的程度。
03 创新点
🌟 3.1 从单机器人搬柔性负载,走向多机器人协同操纵柔性负载
这篇论文最直接的贡献,是把研究对象从独立的机器人-负载系统,推进到了多智能体刚柔耦合机器人系统。问题难度不是简单叠加,而是明显上了一个台阶。
🌟 3.2 强化学习不是装饰,而是实实在在用来处理模型不确定性和最优控制
相比传统 RBFNN 或固定模型控制,这篇文章把 actor-critic 强化学习直接用于未知项逼近和性能优化。它解决的不是单一跟踪问题,而是把跟踪误差、振动抑制和控制输入代价统一纳入了优化目标。
🌟 3.3 把事件触发机制和 RL 控制统一起来,更符合多机器人实际部署需求
这一点很值得控制人重视。论文不是在方法跑完之后再说一句通信更省,而是在控制结构里原生引入事件触发策略,直接针对多机器人带宽约束问题给出解决方案。
04 总结与展望
这篇论文真正有价值的地方,不只是把强化学习、多机器人、柔性负载和事件触发几个热门词拼到一起,而是它确实把这些问题接到了同一个控制闭环里。
它讨论的是一个典型但又不好做的问题:
多机械臂协同操纵柔性对象时,如何同时做到一致跟踪、振动抑制、通信节省和稳定性保证。
从结果来看,论文给出的答案是有说服力的。与 PD 控制相比,所提方法在跟踪误差、一致性误差和柔性负载振动抑制上都表现更好;与时间触发相比,事件触发明显减少了通信更新。
如果从机器人与控制的发展脉络来看,这篇文章还有一个更值得留意的信号:
未来的机器人控制,很可能不再只是追求单体更精确,而是要在协同、柔顺、通信和智能决策之间同时做平衡。
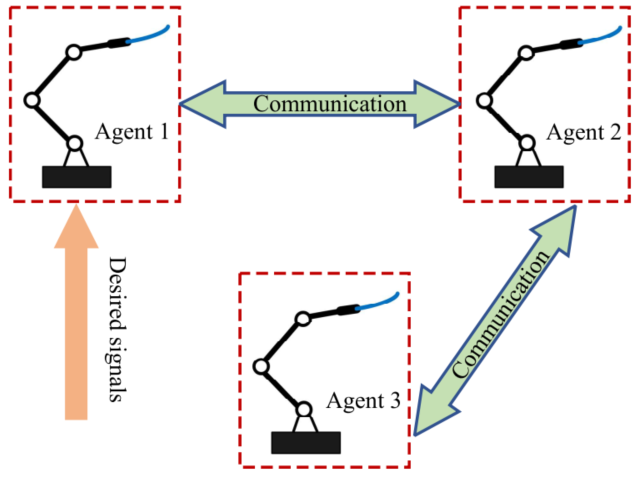
图3 在仿真中使用三个代理的MARSs。
如图3所示,作者搭建了一个由三个智能体组成的多机器人系统仿真场景,通过无向图拓扑实现双向通信协同。
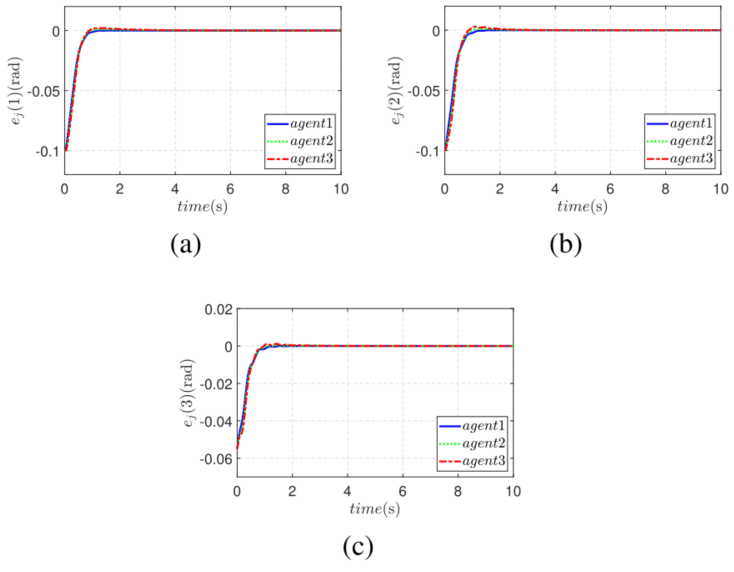
图4:基于该控制的MARSs关节角位置跟踪误差。
如图4所示,在所提控制方法下,三个智能体的关节位置跟踪误差能够较快收敛,且超调明显减小。
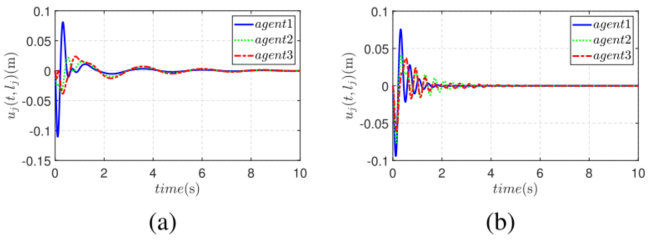
图5:端点挠度
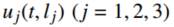
如图5所示,相比 PD 控制,所提方法对柔性负载末端振动的抑制更快、更彻底。
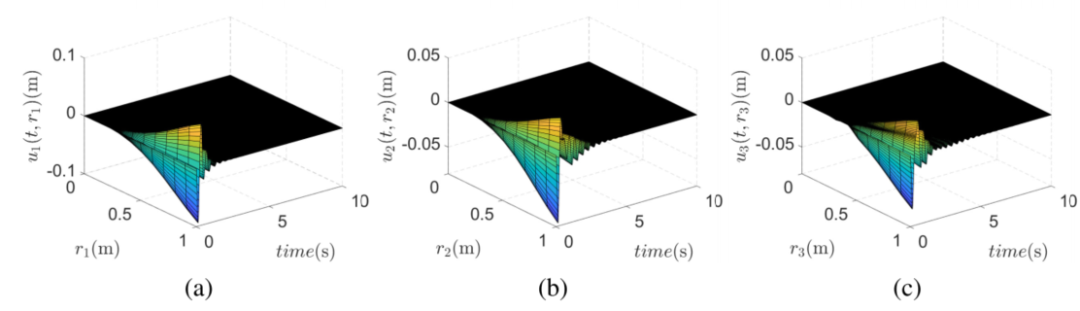
图6:具有建议控制的柔性有效载荷的三维偏转。
如图6所示,柔性负载三维挠度在所提方法下衰减更快,说明振动压制效果更明显。
图7:联合
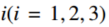
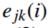
如图7所示,多智能体之间的关节一致跟踪误差能够在较短时间内收敛,说明协同跟踪目标被有效实现。
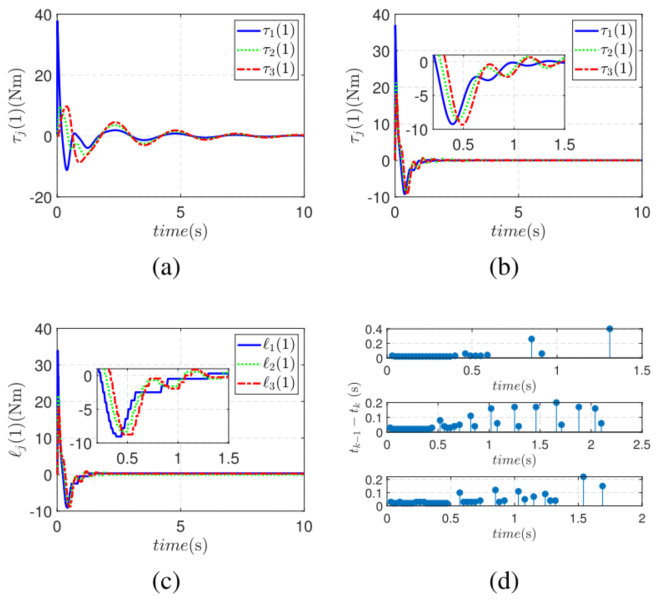
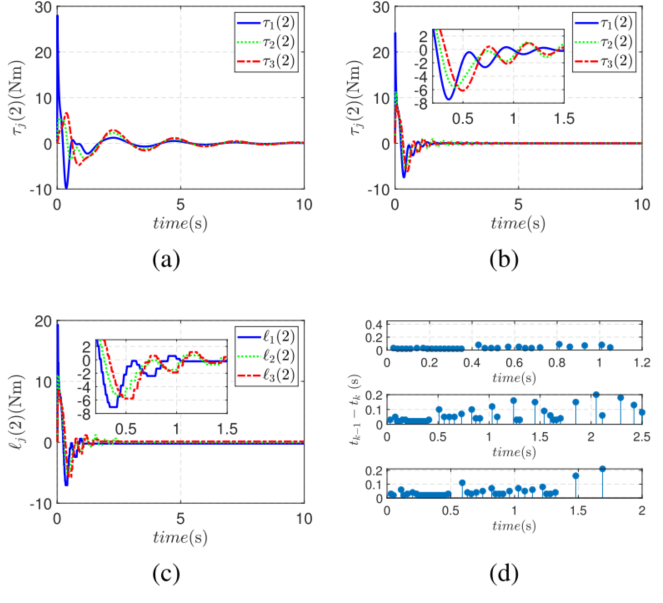
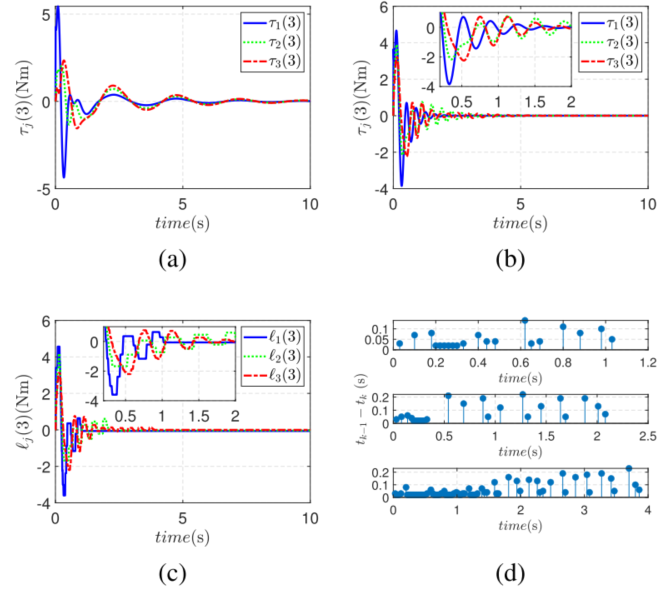
图8 :关节角度1、2、3控制力矩和触发间隔。
如图8所示,事件触发控制相比时间触发明显减少了控制更新频率,从而降低了通信负担。
未来研究将聚焦于以下几个方向:
🔭 更强不确定性下的柔性协同操纵
当前方法已经考虑了负载变化引起的模型不确定性,但面对更复杂环境扰动、更强参数时变和更复杂柔性结构时,控制器还可以继续增强。
📈 从三连杆系统走向更多自由度、更复杂机械臂系统
论文结论里明确提到,这种方法可推广到多连杆、多自由度机械臂系统。真正走向复杂工业机器人和空间操作系统,会是下一步很自然的方向。
🔄 从当前 actor-critic 走向更广义的强化学习框架
作者在结尾明确提到,未来将进一步研究基于 broad RL method 的多智能体机器人系统最优控制问题。
🌍 面向真实网络约束与实际部署的进一步验证
事件触发机制已经证明能减少更新频率,但在存在时延、丢包、异步通信甚至执行器故障的真实网络环境下,仍有很大拓展空间。这个方向对工程落地尤其重要。这里最后一点是基于论文已聚焦通信带宽和事件触发价值做出的合理延伸判断。
如果把一致跟踪、柔性抑振和通信节省三件事放在同一个多机器人系统里,下一步最难突破的瓶颈,会是控制算法本身,还是网络约束下的真实部署问题?欢迎在留言区聊聊你的看法。
声明:本文仅供学术交流,版权归原作者所有。如有错误或侵权,请联系更正或删除,欢迎留言探讨。