让两个大模型化身贪吃蛇,在一个场地里battle 结果会怎样?
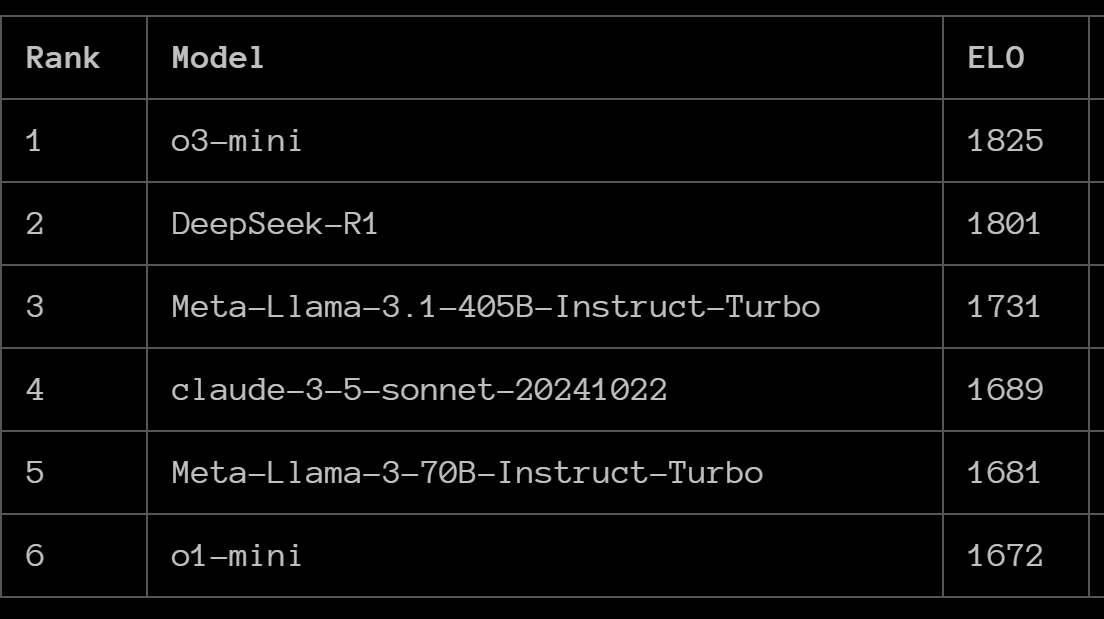
ARC Prize搞了这个新的贪吃蛇大模型能力测试。结果基本上是 o3-mini 和 DeepSeek-R1 断档领先。
搞这个的起因是因为Andrej Karpathy的一条推文(图2)“我非常喜欢用游戏来让不同的大型语言模型(LLMs)相互较量、而非使用固定评估标准的思路。” 这种真实对抗也比较难作弊。
规则很简单,当一条蛇撞到墙、撞到自己或撞到另一条蛇时,游戏结束。
研究者发现大量的模型通过完善的prompt也无法理解规则,但GPT-4水平以上的就能玩起来了。同时推理模型明显占优势
详细介绍: snakebench.com/