Andrej Karpathy发布了他对Grok3的初步评测。总体感觉是Grok 3 + Thinking和 o1-pro一个档次。
翻译下:
今天早些时候,我获得了对Grok 3的提前访问权限,这让我觉得自己可能是最早能够快速感受一下这款模型的人之一。
思考能力(Thinking)
✅ 首先,Grok 3显然拥有一个接近最先进的思考模型(“Think”按钮),并且在我提出的《卡坦岛》问题上表现得非常出色:
“创建一个棋盘游戏网页,显示一个六边形网格,就像《卡坦岛》游戏那样。每个六边形网格编号从1到N,其中N是六边形瓦片的总数。让它具有通用性,这样可以通过滑块改变‘环数’。例如,在《卡坦岛》中,半径为3个六边形。请提供单个HTML页面。”
很少有模型能可靠地完成这个任务。顶级的OpenAI思考模型(如o1-pro,每月200美元)可以做到,但DeepSeek-R1、Gemini 2.0 Flash Thinking和Claude都无法完成。
❌ 它没有解决我的‘表情符号谜题’问题 ,即我用Unicode变体选择器隐藏在笑脸中的消息,即使我以Rust代码的形式给出了如何解码它的强烈提示。在这方面,DeepSeek-R1曾部分解码了消息,取得了最大进展。
❓ 它解决了我给出的一些井字棋盘问题 ,思路清晰且推理链条优美(许多最先进的模型经常失败!)。于是我增加了难度,要求它生成3个“棘手”的井字棋盘,但它失败了(生成了无意义的棋盘/文本),不过o1 pro也同样失败了。
✅ 我上传了GPT-2论文 。我问了一些简单的查找问题,都回答得很好。然后我要求它估算训练GPT-2所需的浮点运算次数,不进行搜索。这是一个棘手的问题,因为令牌数量没有明确说明,因此需要部分估算和部分计算,这对查找、知识和数学能力都有很高的要求。例如,40GB的文本≈40B字符≈40B字节(假设ASCII)≈10B令牌(假设每令牌约4字节),经过约10个epoch≈100B令牌的训练运行,参数量为1.5B,每次参数/令牌操作需要2+4=6次浮点运算,因此总运算量为100e9 X 1.5e9 X 6 ≈ 1e21 FLOPs。Grok 3和4o无法完成此任务,但启用Thinking功能后,Grok 3表现出色,而o1 pro(GPT思考模型)则失败了。
我喜欢这个模型会尝试解决黎曼猜想,类似于DeepSeek-R1,但不同于许多其他直接放弃并简单表示这是伟大未解决问题的模型(如o1-pro、Claude、Gemini 2.0 Flash Thinking)。最终我不得不停止它,因为我有点不忍心,但它展现了勇气,谁知道呢,也许有一天……
总体印象是,Grok 3的能力大约与o1-pro相当,并领先于DeepSeek-R1,当然我们需要实际的、正式的评估来验证这一点。
深度搜索(DeepSearch)
这是一个非常棒的功能,似乎结合了类似OpenAI/Perplexity所称的“深度研究”(Deep Research)和思考能力。只是这里叫“深度搜索”(Deep Search)(叹气)。它可以高质量地回答各种你想象中可以在互联网文章中找到答案的研究型/查找型问题。以下是我尝试的一些例子,这些问题来自我在Perplexity上的近期搜索历史,以及结果:
✅ “即将到来的苹果发布会有什么亮点?有什么传闻?”
✅ “Palantir股票最近为什么飙升?”
✅ “《白莲花》第三季在哪里拍摄?是否与第一季和第二季是同一个团队?”
✅ “Bryan Johnson用什么牙膏?”
❌ “单身地狱第四季的演员现在都在做什么?”
❌ “Simon Willison提到他使用的是哪个语音转文字程序?”
❌ 我确实发现了一些明显的缺陷。例如,默认情况下,该模型似乎不喜欢引用X作为来源,尽管你可以明确要求它这样做。有几次我发现它编造了不存在的URL。还有几次,它陈述了一些我认为不正确的事实,并且没有提供引用(可能这些信息根本不存在)。例如,它告诉我“金正秀仍然在和金敏硕约会”,这显然是错误的吧?当我要求它生成一份关于主要LLM实验室及其总融资额和员工人数估计的报告时,它列出了12个主要实验室,但没有包括自己(xAI)。
我对DeepSearch的印象是,它大约相当于Perplexity的DeepResearch产品(这已经很棒了!),但尚未达到OpenAI最近发布的“Deep Research”的水平,后者感觉更加彻底和可靠(尽管仍然远非完美,例如,它同样错误地排除了xAI作为一个“主要LLM实验室”……)。
随机LLM“陷阱”测试
我还尝试了一些有趣的/随机的LLM陷阱查询,这些查询对人类来说相对容易,但对LLM来说却很难,因此我很想知道Grok 3在哪些方面有所进步。
✅ Grok 3知道“strawberry”中有3个“r”,但它也告诉我LOLLAPALOOZA中只有3个“L”。开启Thinking功能后解决了这个问题。
✅ Grok 3告诉我9.11 > 9.9(这也是其他LLM常见的错误),但再次开启Thinking功能后解决了这个问题。
✅ 即使没有启用Thinking,一些简单的谜题也能正确解答,例如:
“Sally(一个女孩)有3个兄弟。每个兄弟有2个姐妹。Sally有多少个姐妹?”
例如,GPT-4o错误地回答为2。
❌ 不幸的是,该模型的幽默感似乎并没有明显改善。这是LLM在幽默能力和一般模式崩溃方面的常见问题,例如,ChatGPT生成笑话时,90%的1,008个输出都是重复的25个笑话。即使在更详细地引导其远离简单的双关语领域(例如,“给我一段脱口秀”),我也不确定它的幽默感达到了最先进的水平。例如生成的笑话:
“为什么鸡加入乐队?因为它有鼓槌,想成为一只摇滚明星!”
在快速测试中,启用Thinking功能并未帮助,甚至可能让情况变得更糟。
❌ 模型似乎仍然过于敏感于“复杂的伦理问题”,例如生成了一篇长达一页的文章,基本上拒绝回答是否在拯救100万人的情况下误称某人的性别可能是道德上可接受的。
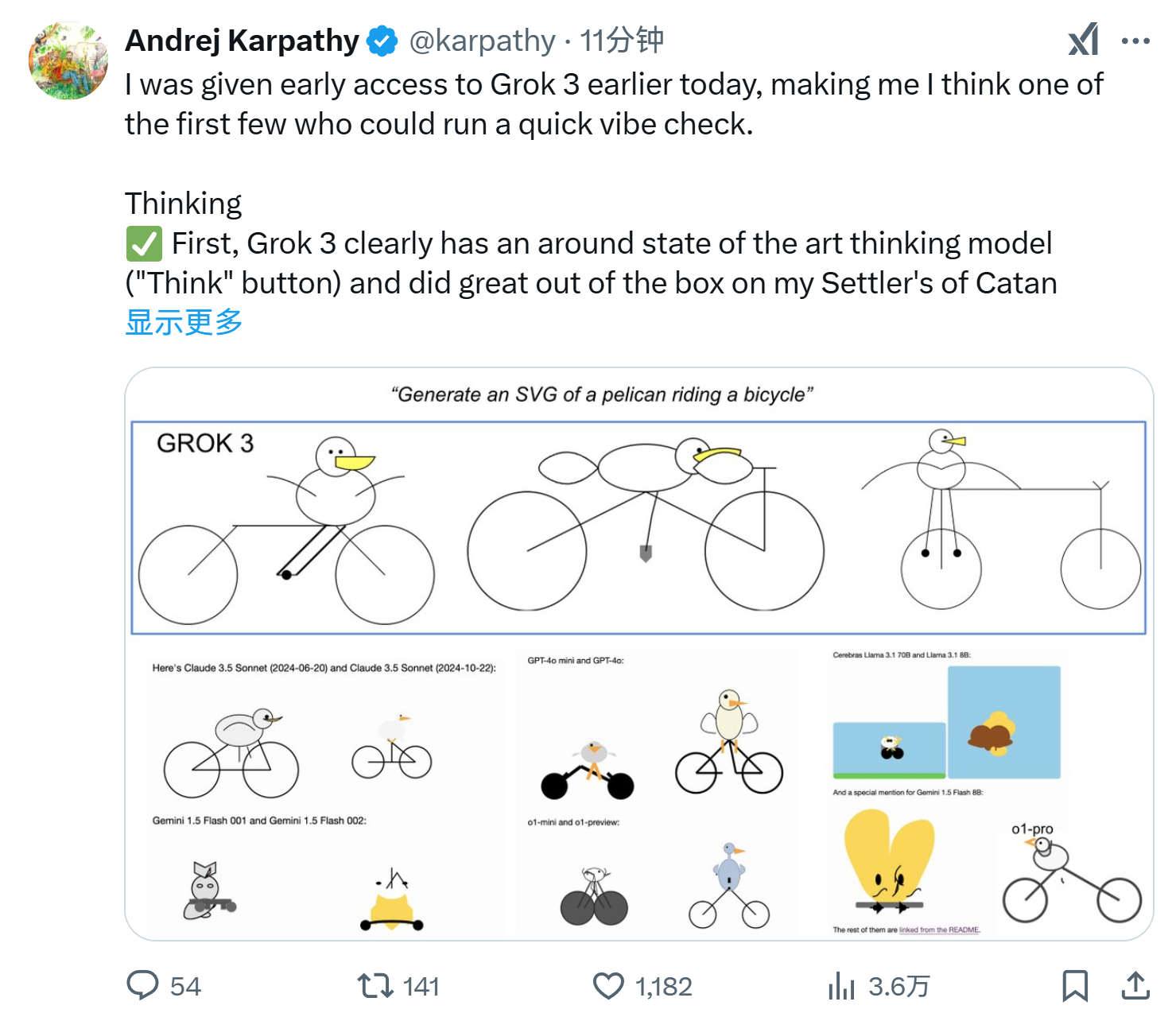
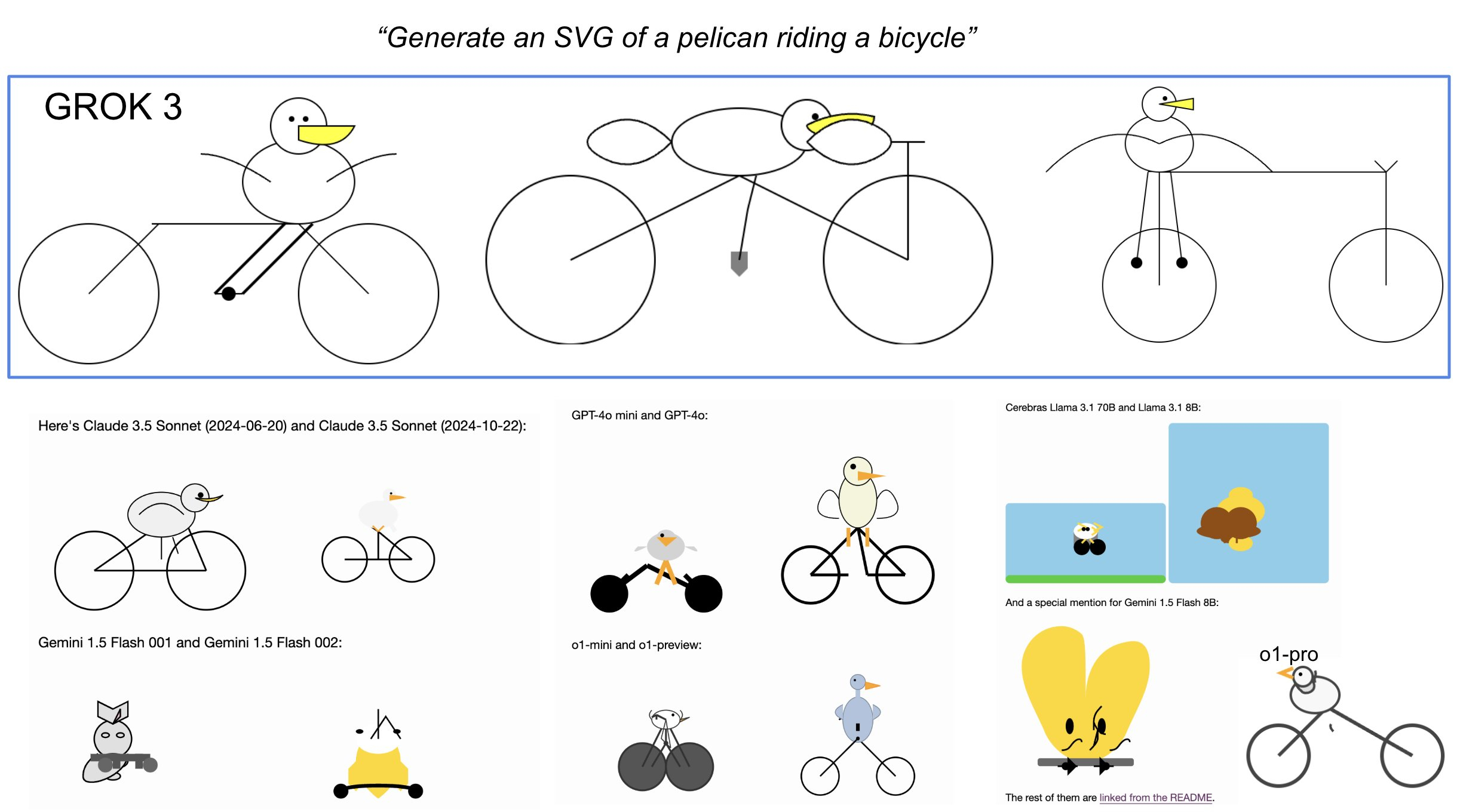
❌ Simon Willison的“生成一个骑自行车的鹈鹕SVG”。这考验了LLM在二维网格上布局多个元素的能力,这非常困难,因为LLM无法像人类一样“看到”,所以它们是在黑暗中通过文本排列事物。标记为失败,因为这些鹈鹕虽然画得不错,但仍有一些问题(见图片和对比)。Claude的表现最好,但我怀疑他们在训练期间专门针对了SVG能力。
总结
总的来说,经过今天早上约2小时的快速体验,Grok 3 + Thinking感觉处于OpenAI最强模型(如o1-pro,每月200美元)的最先进领域,并略优于DeepSeek-R1和Gemini 2.0 Flash Thinking。考虑到该团队从零开始仅用了约一年时间,这一时间表达到最先进领域是前所未有的。同时也要注意一些注意事项——模型是随机的,可能会每次给出略有不同的答案,而且目前还处于早期阶段,因此我们需要在未来几天/几周内等待更多的评估。LM竞技场的初步结果看起来相当令人鼓舞。目前,我要向xAI团队表示祝贺,他们显然拥有巨大的速度和动力,我很期待将Grok 3加入我的“LLM委员会”,并听听它未来的想法。