DeepSeek刚发新论文了!(和北大合作的论文,应该是有 老师团队的成果[中国赞]。还有梁文锋是论文合著者)
arxiv.org/pdf/2502.11089
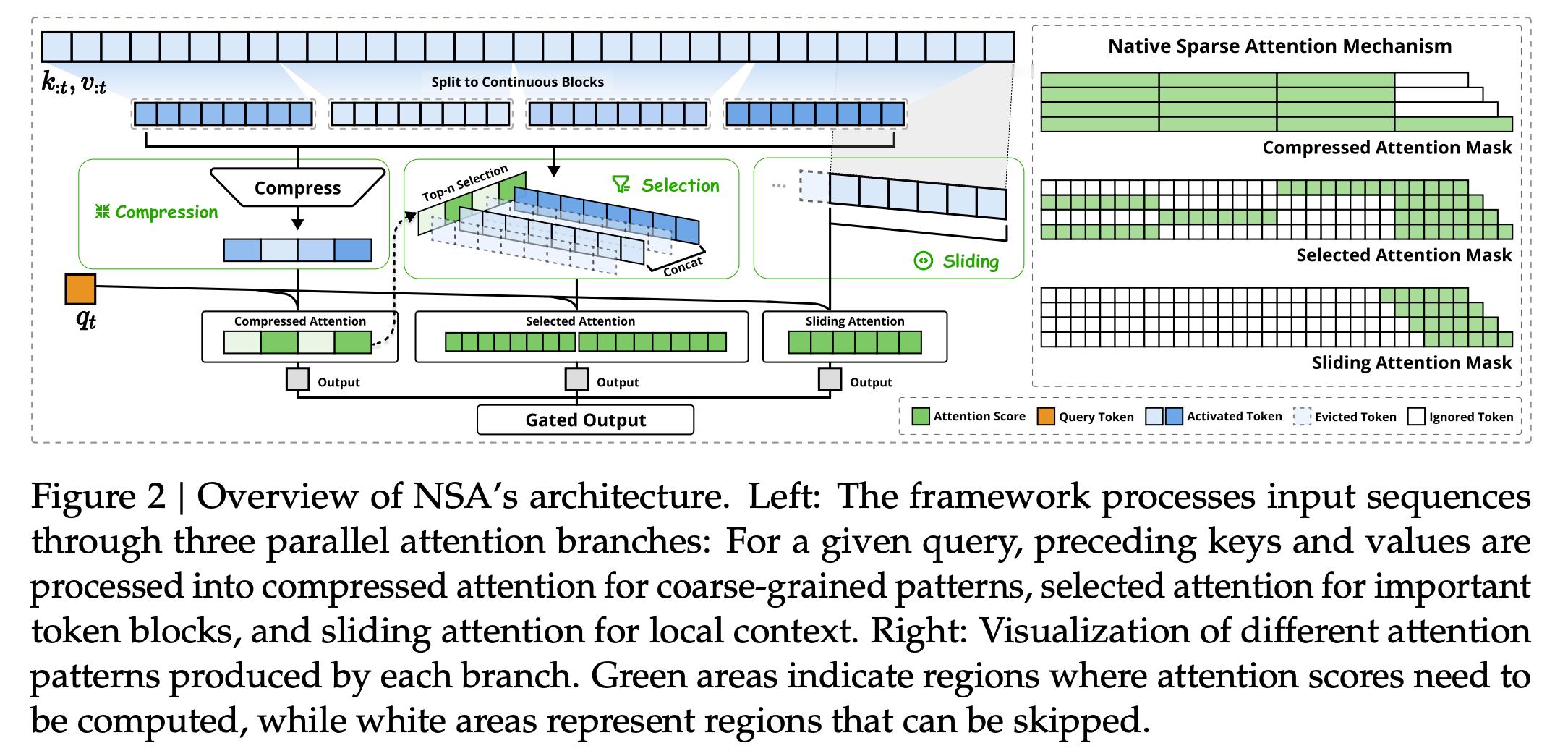
这篇论文“Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention” 介绍了原生稀疏注意力(Native Sparse Attention, NSA)技术。NSA 技术让模型在计算注意力时, 不再需要关注所有信息,而是只关注最重要的部分。 这样就大大减少了计算量,加速了注意力计算的速度。(还是缺卡的无奈啊~~~~~)
NSA 技术在性能上实现了 效率与精度的双重提升。 在效率方面,针对 64k 长文本序列,NSA 在解码速度上实现了 高达 11.6 倍的加速,前向传播和反向传播也分别加速了 9.0 倍和 6.0 倍,且加速倍数随着序列长度增加而更加显著。 在精度方面,NSA 预训练模型在通用基准测试中 性能与全注意力模型持平甚至略有超出,并在长文本任务和推理能力评估中 显著优于全注意力模型以及其他稀疏注意力方法,例如在 LongBench 综合评估中平均分 超出全注意力模型 0.032,在需要复杂推理的多跳问答任务中 性能提升更加明显。 这意味着 NSA 在大幅提升计算效率的同时, 保证了模型优秀的性能表现,甚至在特定任务上有所增强。