Kimi似乎节奏和DeepSeek同步起来了,上次发kimi1.5时间和deepseek撞车,而在昨天DeepSeek发布提升提升长文本处理的效率的NSA技术后,Kimi在几小时后也发布了类似的技术MOBA。而且同时公布了训练、推理用的代码。
github.com/MoonshotAI/MoBA
两者的相同点:
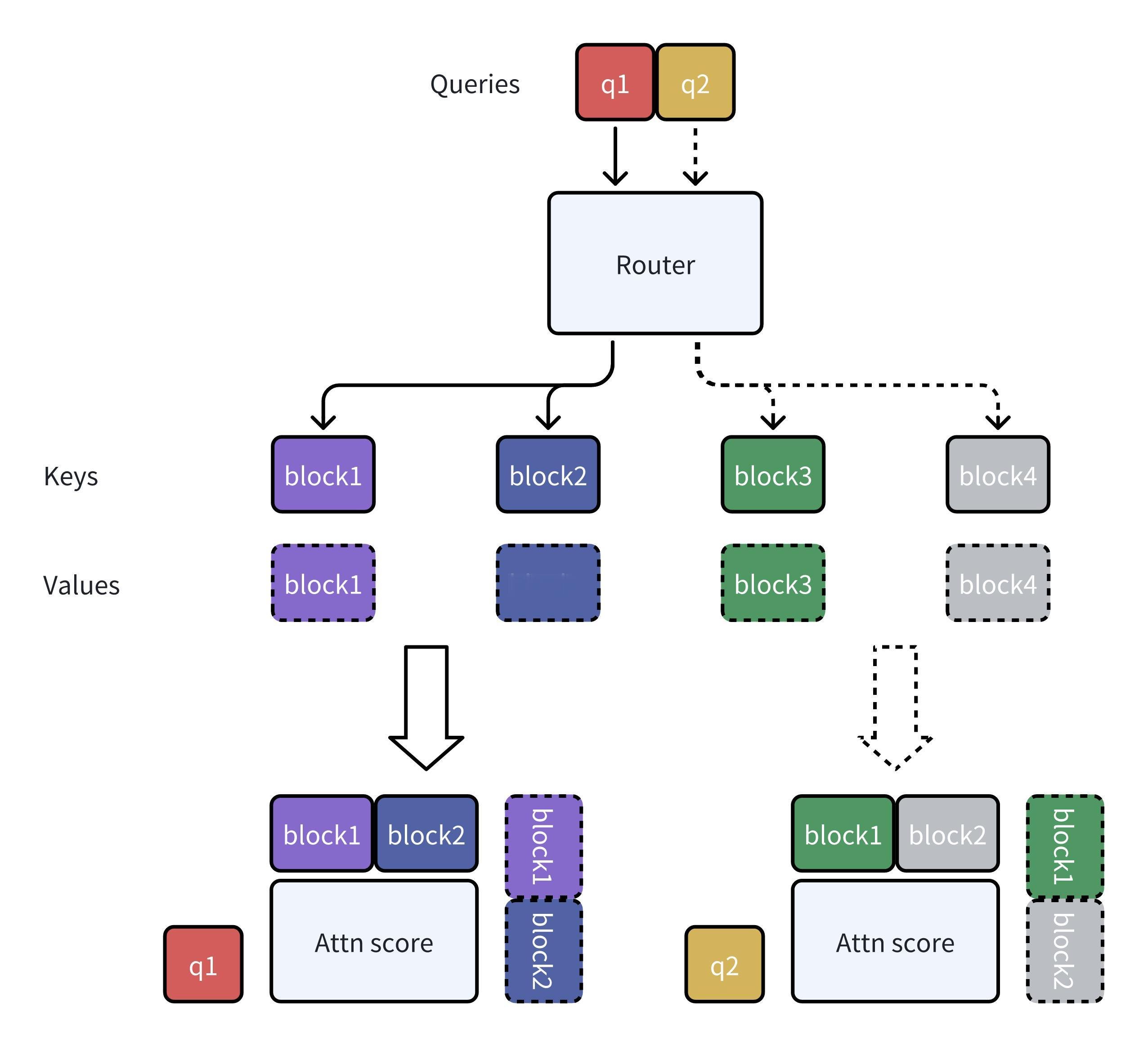
1. 两者都采用了稀疏注意力机制,即并非所有 tokens 都需要互相 attention,而是有选择地关注部分 tokens,以减少计算量。
2. 两者都基于 块 (block) 的概念 进行操作,将长文本分成多个块,并以块为单位进行稀疏选择或计算。
3. 两者都 兼容 Transformer 架构,可以作为标准注意力机制的替代品,嵌入到现有的 Transformer 模型中。
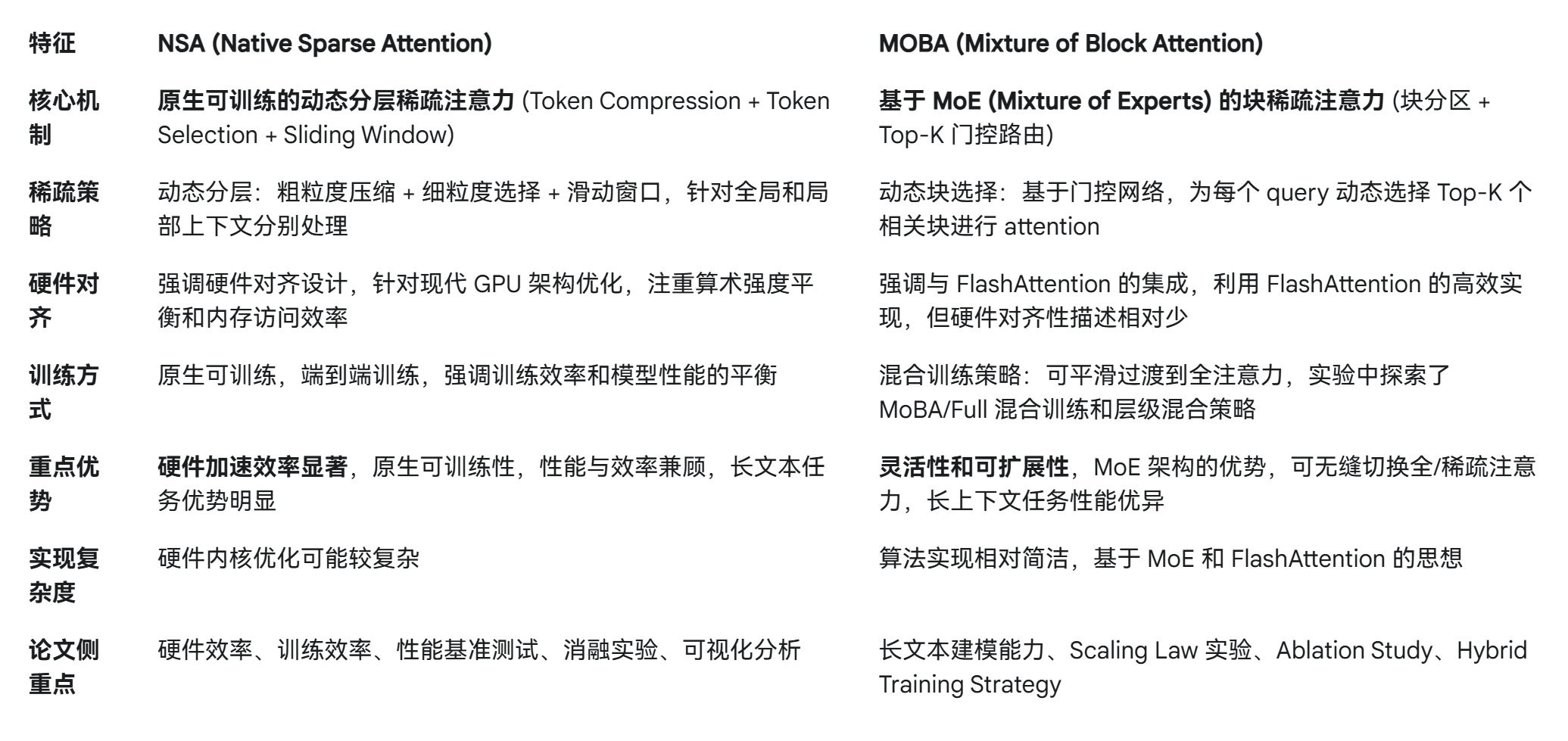
不同点如图3.