想把PDF或图像转为Markdown文件?或许可以试试这个!
Nanonets-OCR-s是一款轻量的VLM模型,能够将PDF和图像转换为干净、结构化的Markdown,并且还是中文友好!
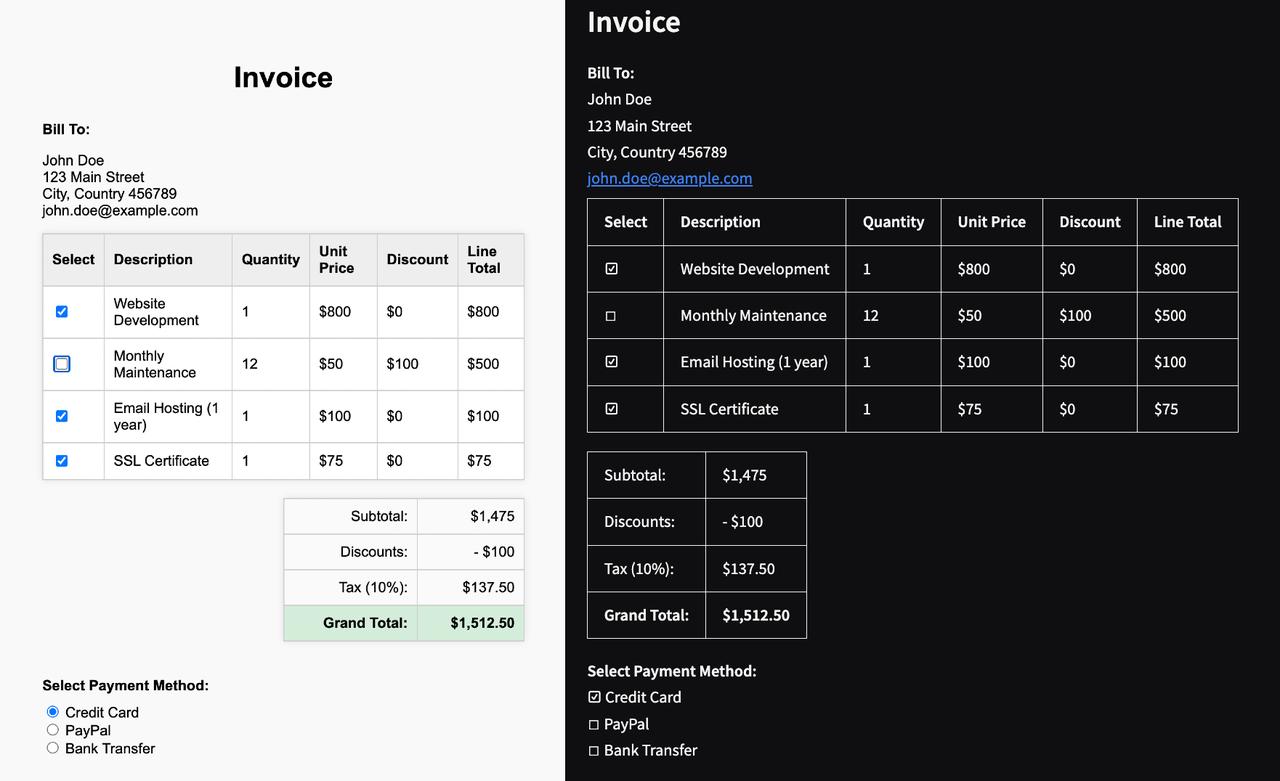
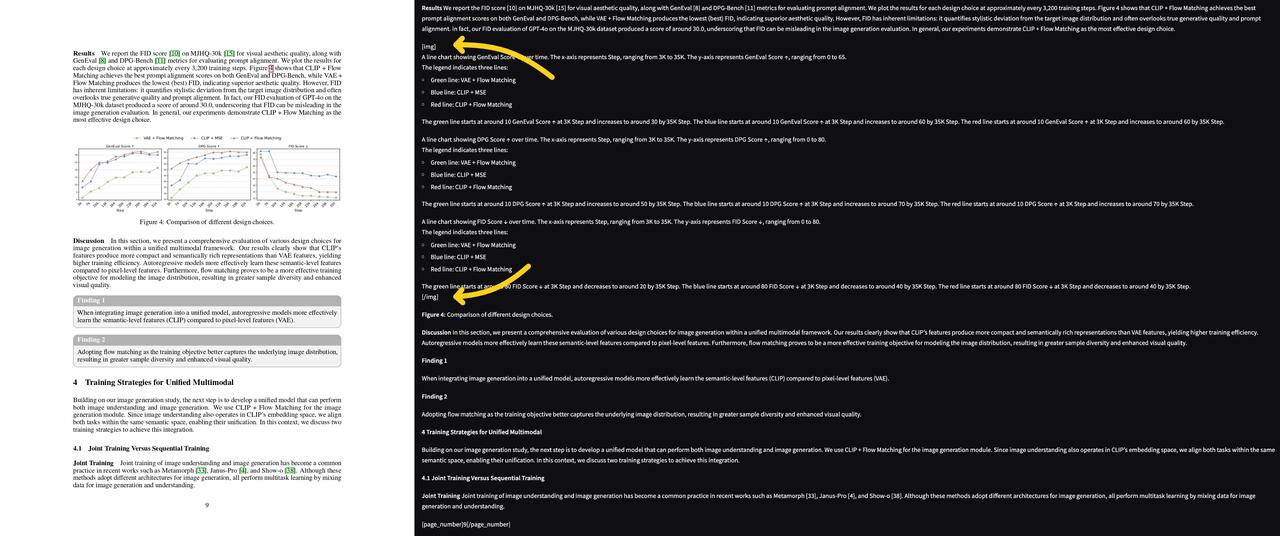
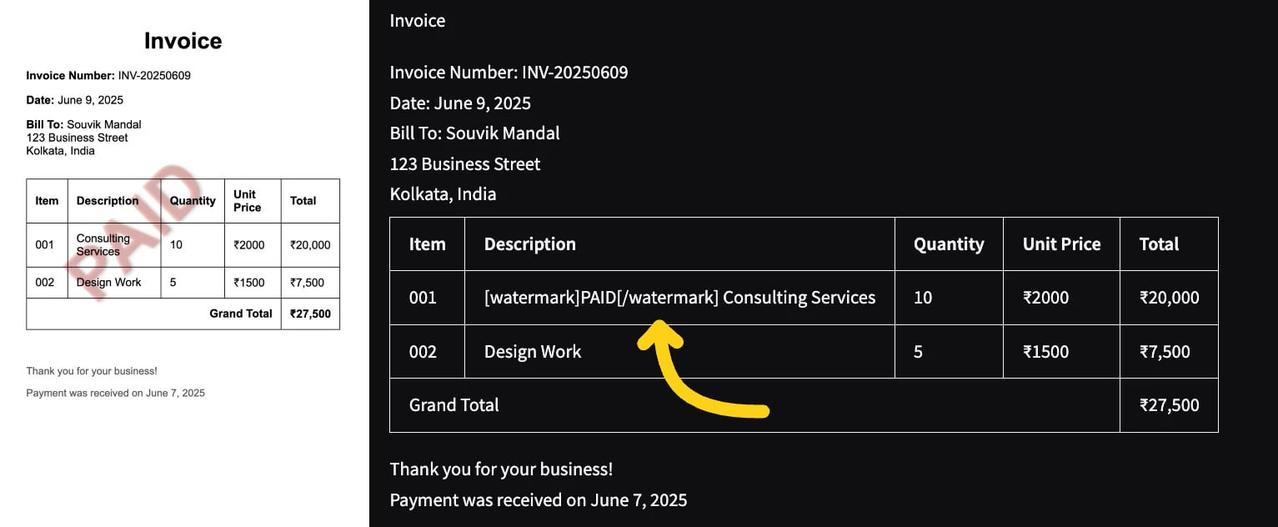
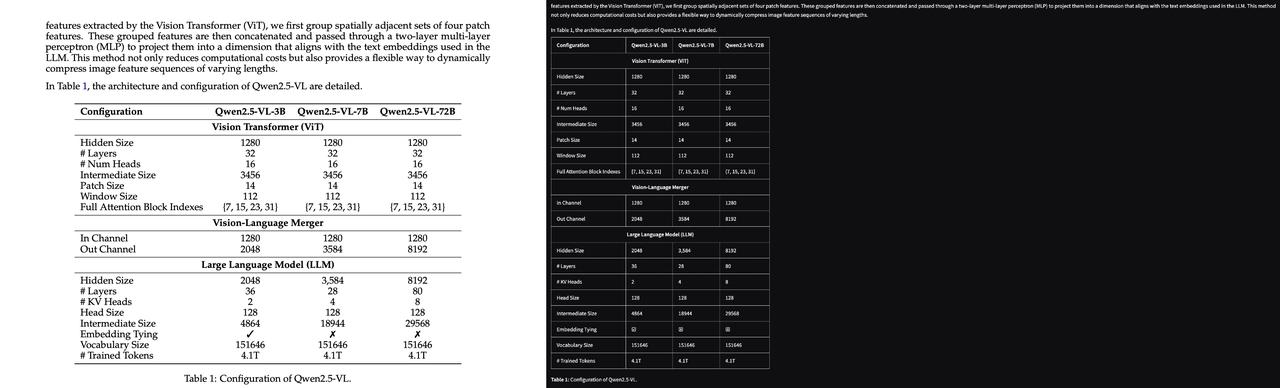
模型经过专门训练,能够准确理解文档结构和内容上下文,包括表格、公式、图像、图表、水印、复选框等元素。
具体来说,它能够实现以下功能:
LaTeX公式识别:自动将数学方程和公式转换为正确格式的LaTeX语法。能够区分行内公式( $...$ )和显示公式( $$...$$)。
智能图像描述:使用结构化标签描述文档中的图像,使其适合LLM处理。可以描述各种图像类型,包括徽标、图表、图形等,详细说明其内容、样式和上下文。
签名检测与隔离:识别并将签名与其他文本隔离,输出在标签内。
水印提取:检测并提取文档中的水印文本,将其放置在标签内。
智能复选框处理:将表单复选框和单选按钮转换为标准化的Unicode符号(☐、☑、☒),以实现一致可靠的处理。
复杂表格提取:准确从文档中提取复杂表格,并将其转换为markdown和HTML表格格式。
需要注意的是,目前这个模型还尚未针对手写文本进行训练,对手写文本的识别可能不到位,除此之外,模型可能会出现幻觉。
感兴趣的朋友,可以点击下方的链接进行尝试⬇️
代码仓库:
Huggingface地址:-OCR-s