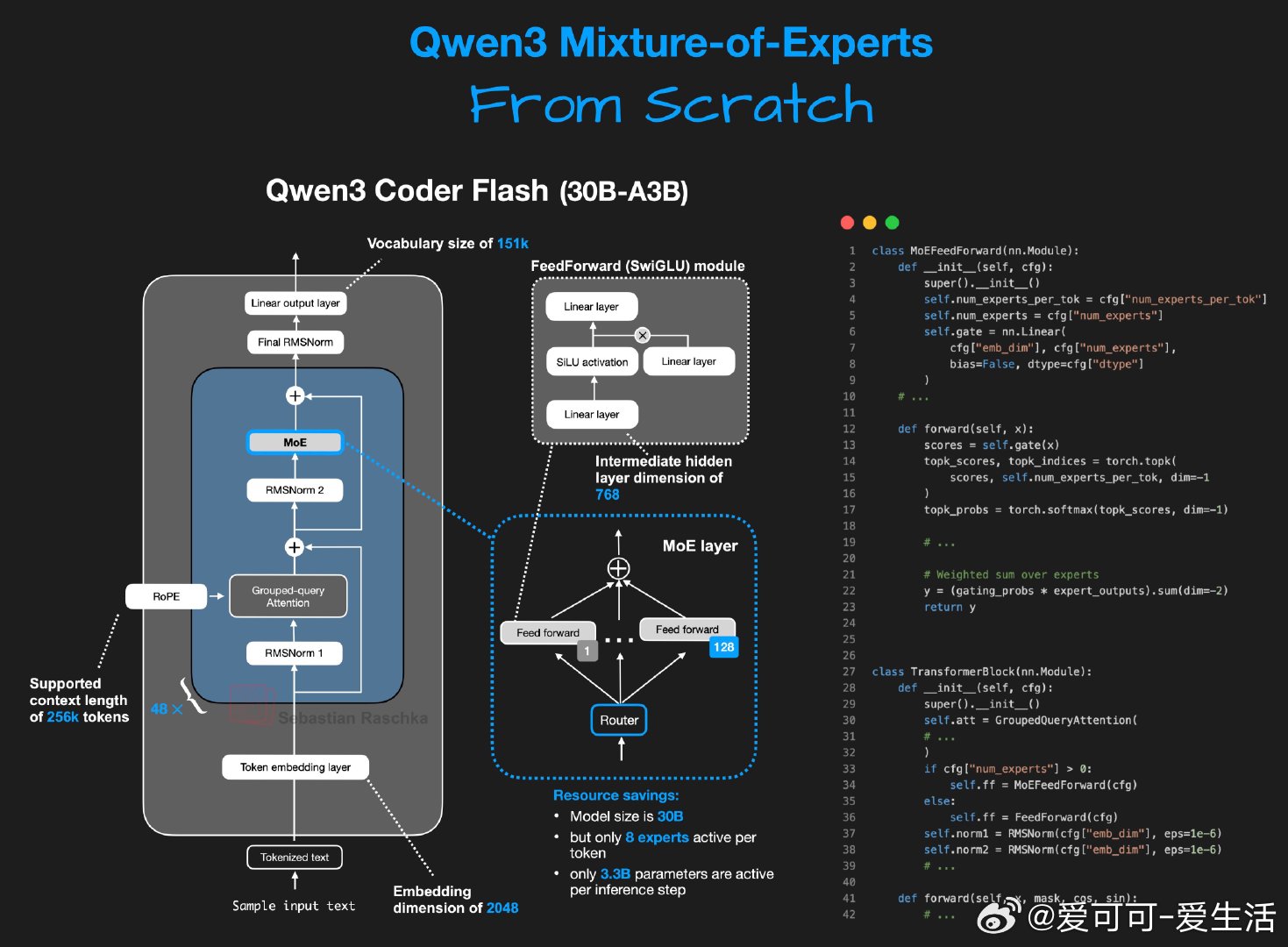
Sebastian Raschka发布了一个纯PyTorch从头实现的Qwen3 Mixture-of-Experts(MoE)模型,核心亮点如下:
• 模型规模30B参数,采用MoE架构,包含128个专家,每个token激活8个专家,实现专家动态路由。
• 代码高度优化,注重人类可读性,完整封装于单个Jupyter Notebook中,便于学习和复现。
• 运行环境仅需单张NVIDIA A100显卡,且通过offloading技术克服显存限制,适合教育和原型开发。
• 目前推理速度约1 token/秒,远低于Cerebras Wafer Scale Engine的Qwen3 Coder(2000 token/秒),体现了纯软件实现与定制硬件的性能差异。
• 另有带KV缓存的变体notebook,提升推理效率,适合进一步探索Transformer优化策略。
此项目展现了在有限硬件资源上探索大型MoE模型的实践路径,强调“可读即可用”的方法论,适合研究者理解MoE机制及模型调优。对比Cerebras等前沿硬件平台,凸显硬件与软件协同优化的未来趋势。
详情笔记本👉 github.com/rasbt/LLMs-from-scratch/blob/main/ch05/11_qwen3/standalone-qwen3-moe.ipynb
KV缓存版本👉 github.com/rasbt/LLMs-from-scratch/blob/main/ch05/11_qwen3/standalone-qwen3-moe-plus-kvcache.ipynb
人工智能 大模型 MixtureOfExperts PyTorch 深度学习 教育开源