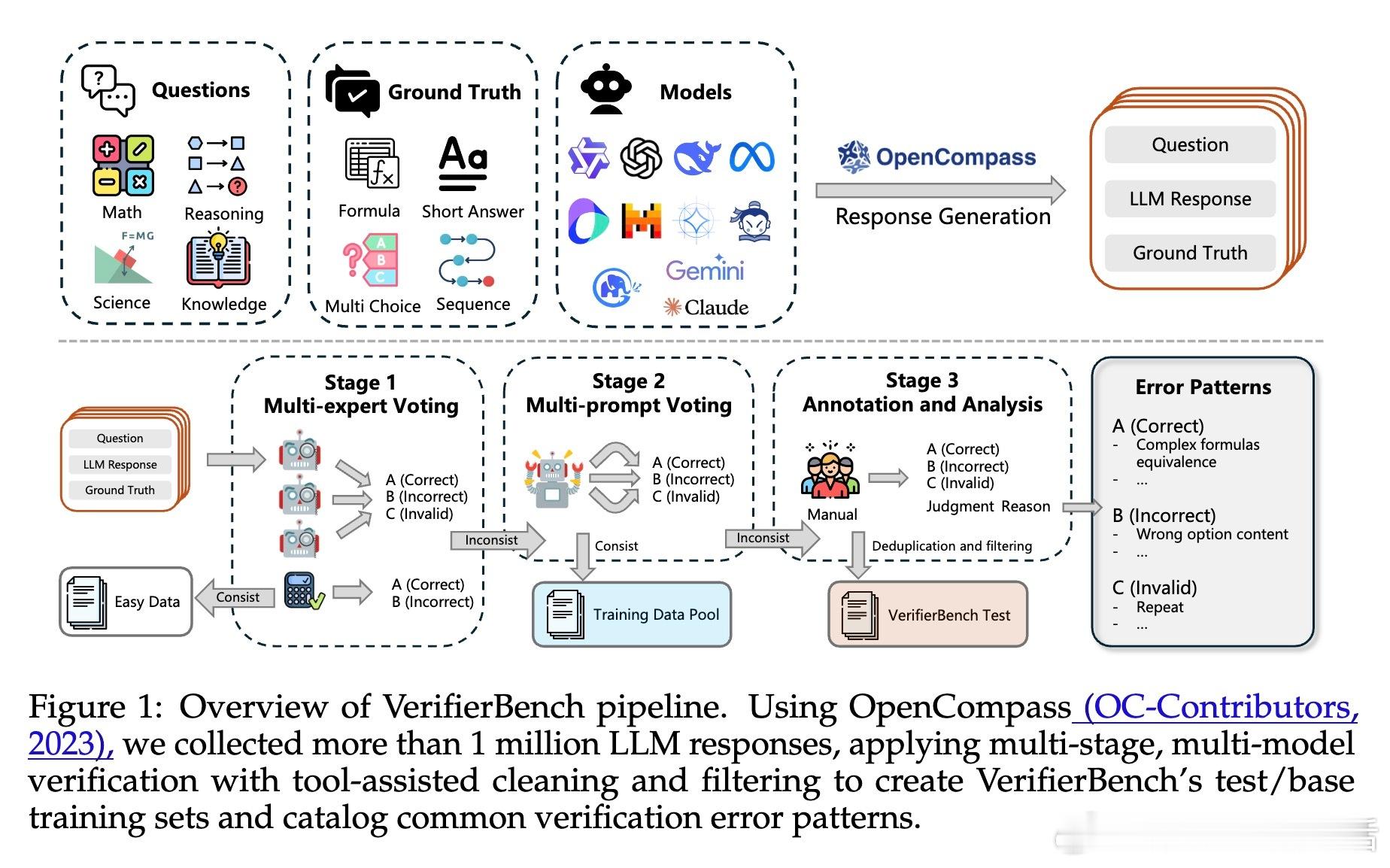
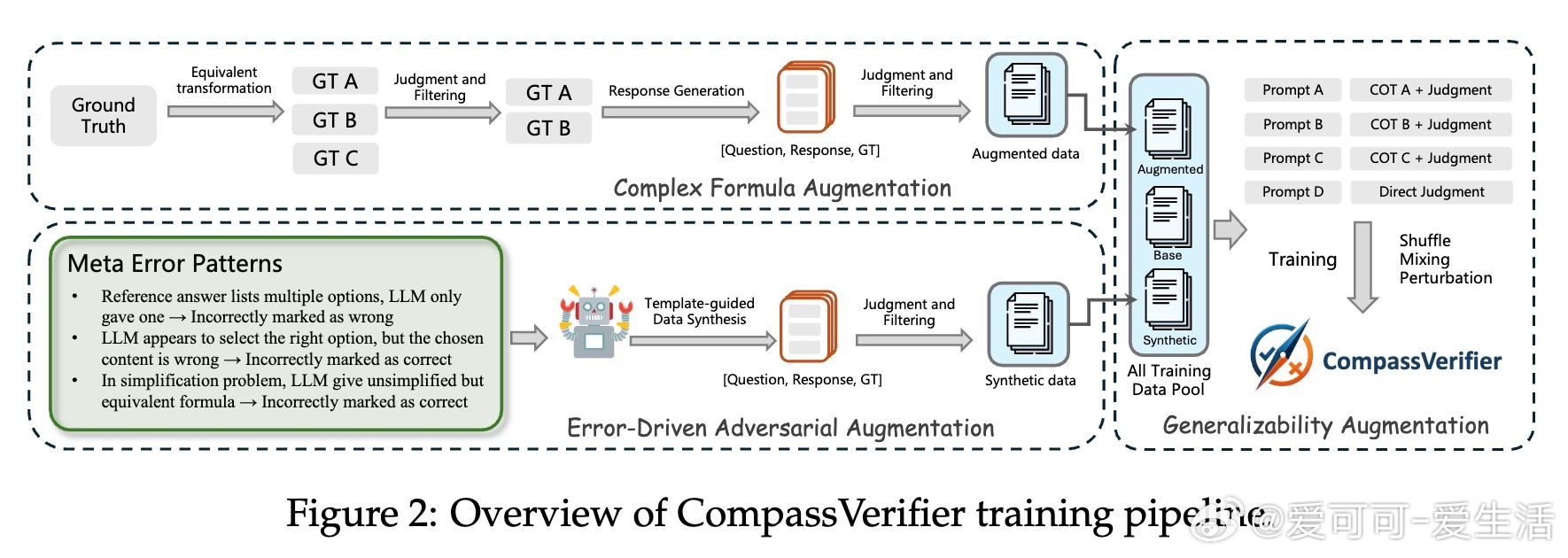
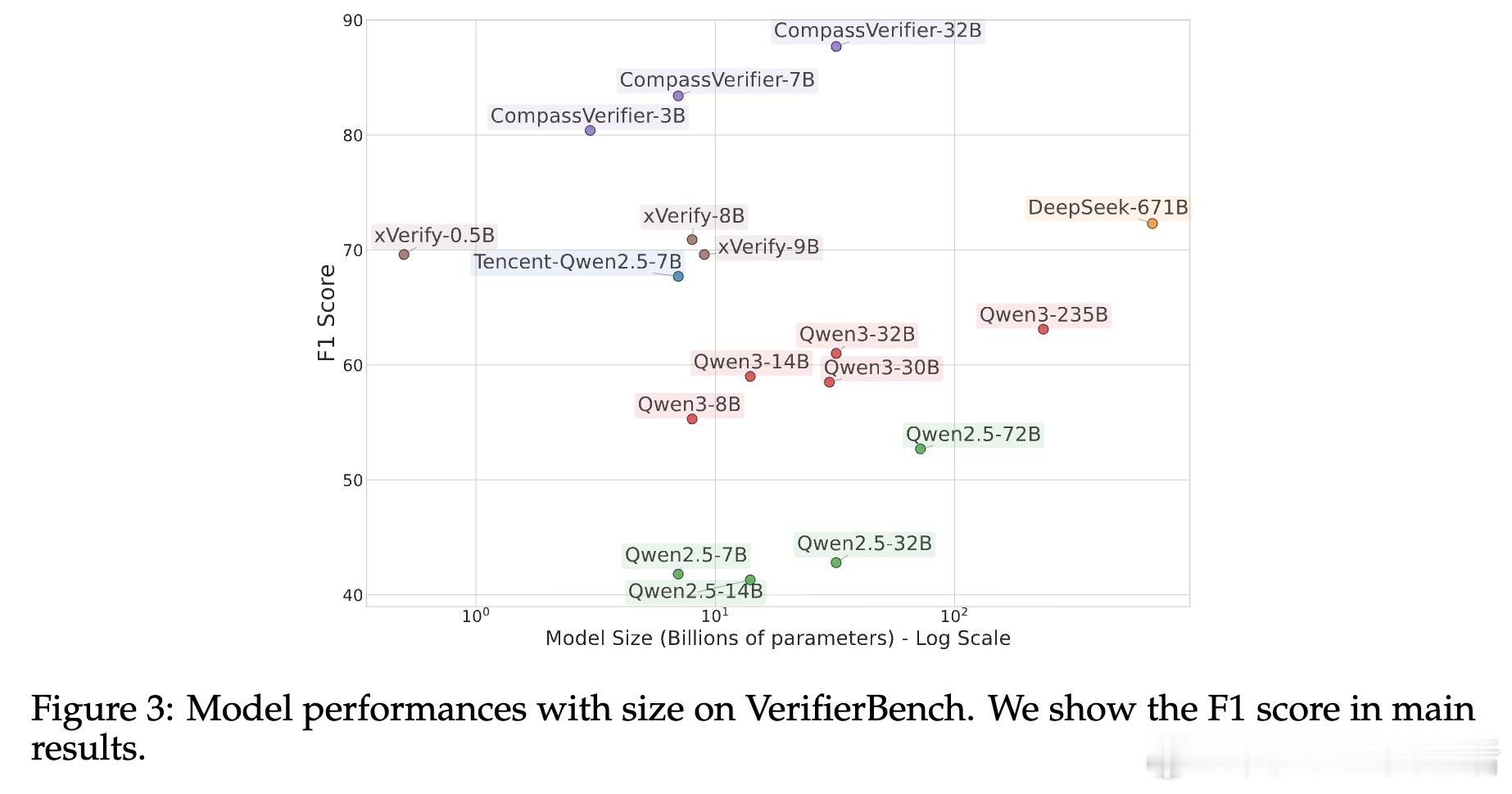
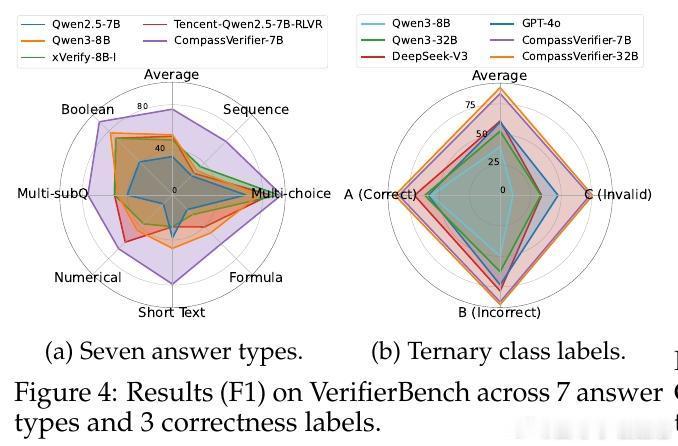
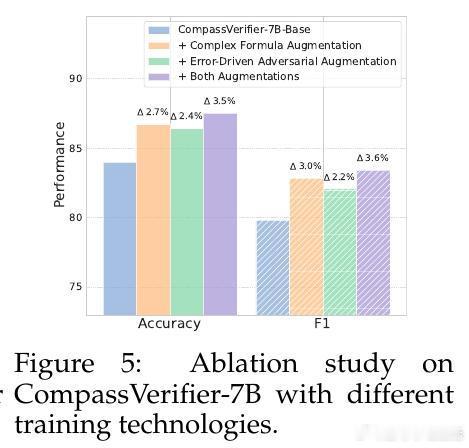
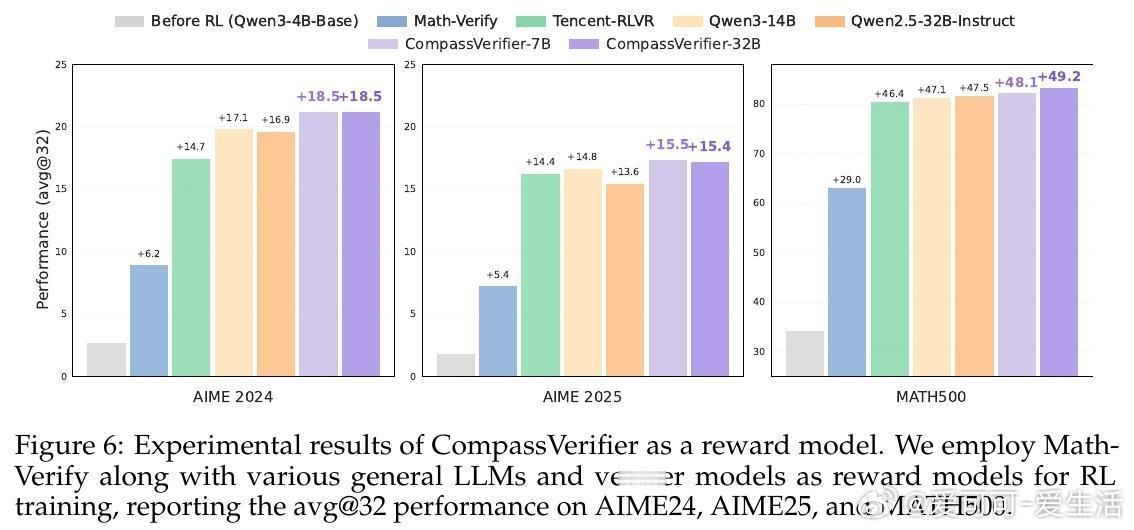
[CL]《CompassVerifier: A Unified and Robust Verifier for LLMs Evaluation and Outcome Reward》S Liu, H Liu, J Liu, L Xiao... [Shanghai AI Laboratory] (2025)
CompassVerifier:统一且稳健的大型语言模型(LLM)评估与结果奖励验证器
• 旨在解决当前 LLM 评估中多样性与鲁棒性不足的难题。
• 统一框架设计,兼容多种任务类型(推理、对话、数学等),支持不同模型和评分标准的灵活接入。
• 采用多步验证机制,结合自动化判分与人工校验,提高评测结果的准确性和可信度。
• 引入结果奖励机制,推动模型在评估中持续优化表现,实现评估与训练闭环的深度融合。
• 支持多领域、多语言、多模态场景,面向未来更复杂的智能系统评估需求。
• 实验表明,CompassVerifier 在多项公开基准测试中显著提升判定准确率,优于现有主流评估工具。
• 助力研究者和企业构建更公正、透明且高效的 LLM 评估体系,推动大型模型能力的真实可信释放。
深入了解👉 arxiv.org/abs/2508.03686
大型语言模型模型评估人工智能机器学习自然语言处理