[CL]《A comprehensive taxonomy of hallucinations in Large Language Models》M Cossio [Universitat de Barcelona] (2025)
大规模语言模型(LLMs)幻觉现象的全面分类与应对策略解析:
• 幻觉定义:LLM在生成“看似合理但事实错误或捏造内容”时即发生幻觉,且理论证明此现象对所有可计算LLM均不可避免,无法通过模型自身完全消除,需依赖外部辅助和人类监督。
• 核心分类:
- 内在幻觉:生成内容与输入上下文直接矛盾,表现为逻辑不一致或错误解读输入。
- 外在幻觉:输出与训练数据或现实事实不符,包含虚构实体或信息。
- 事实性幻觉:与客观真实世界知识冲突。
- 真实性幻觉:偏离输入指令或上下文但可能内部连贯。
• 具体表现多样:包括事实错误(如错误历史事件)、上下文矛盾、逻辑错误、时间错乱、伦理违规(如诽谤、金融误导、法律错误)、任务特定幻觉(对话、摘要、问答、代码生成、多模态应用等)。
• 根源多维:
- 数据因素:训练数据质量、偏差、时效性及摘要与源文档不一致。
- 模型因素:自回归生成机制、架构限制、训练偏差、解码策略的随机性、过度自信、推理能力不足等。
- 提示因素:对抗性攻击、过度确认偏见及提示设计不当。
• 用户认知影响:
- 用户倾向于信任流畅且自信的输出,幻觉往往不易被察觉。
- 认知偏误如自动化偏见、确认偏见和解释深度错觉加剧幻觉风险。
- 即使警示存在,用户仍可能忽视潜在错误。
• 评估方法:
- 公开基准数据集(TruthfulQA、HalluLens、FActScore等)及领域专用基准(医学、代码、多模态等)。
- 量化指标涵盖忠实度评估(ROUGE、FactCC、SummaC)与事实性评估(KILT、RAE)。
- 人工评估仍具不可替代性,涵盖正确性、忠实性、连贯性及有害性检测。
- 现存评测面临标准化不足、任务依赖强、细微幻觉难判别、缺乏解释性等挑战。
• 幻觉缓解策略:
- 架构层面:工具调用(Toolformer)、检索增强生成(RAG)、基于合成或对抗性数据微调。
- 系统层面:规则守护(逻辑验证、事实过滤、回退机制)、符号推理融合。
- 混合系统:结合多种方法,动态适配不同应用场景,特别是高风险领域优先保证准确性与可追溯性。
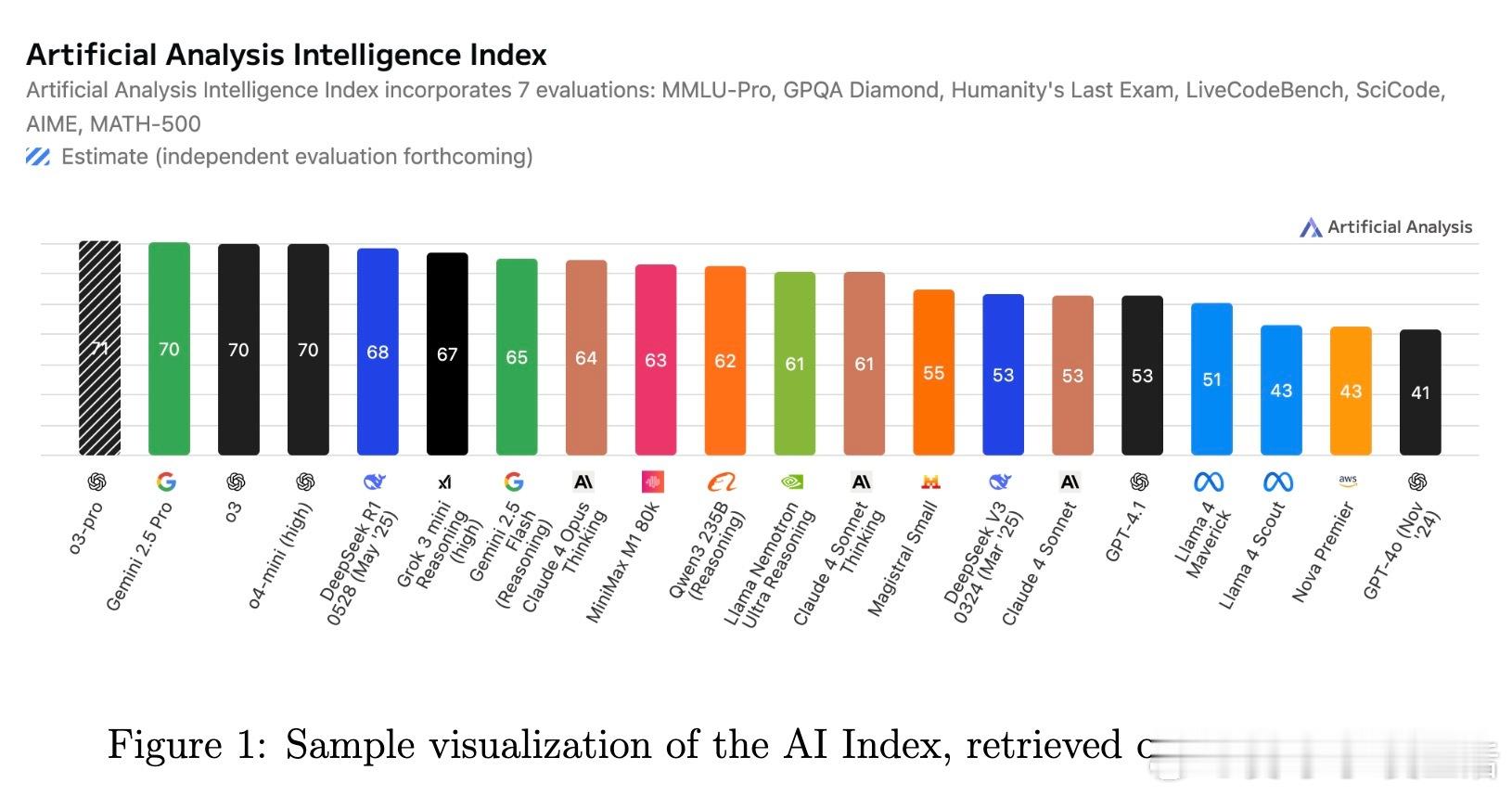
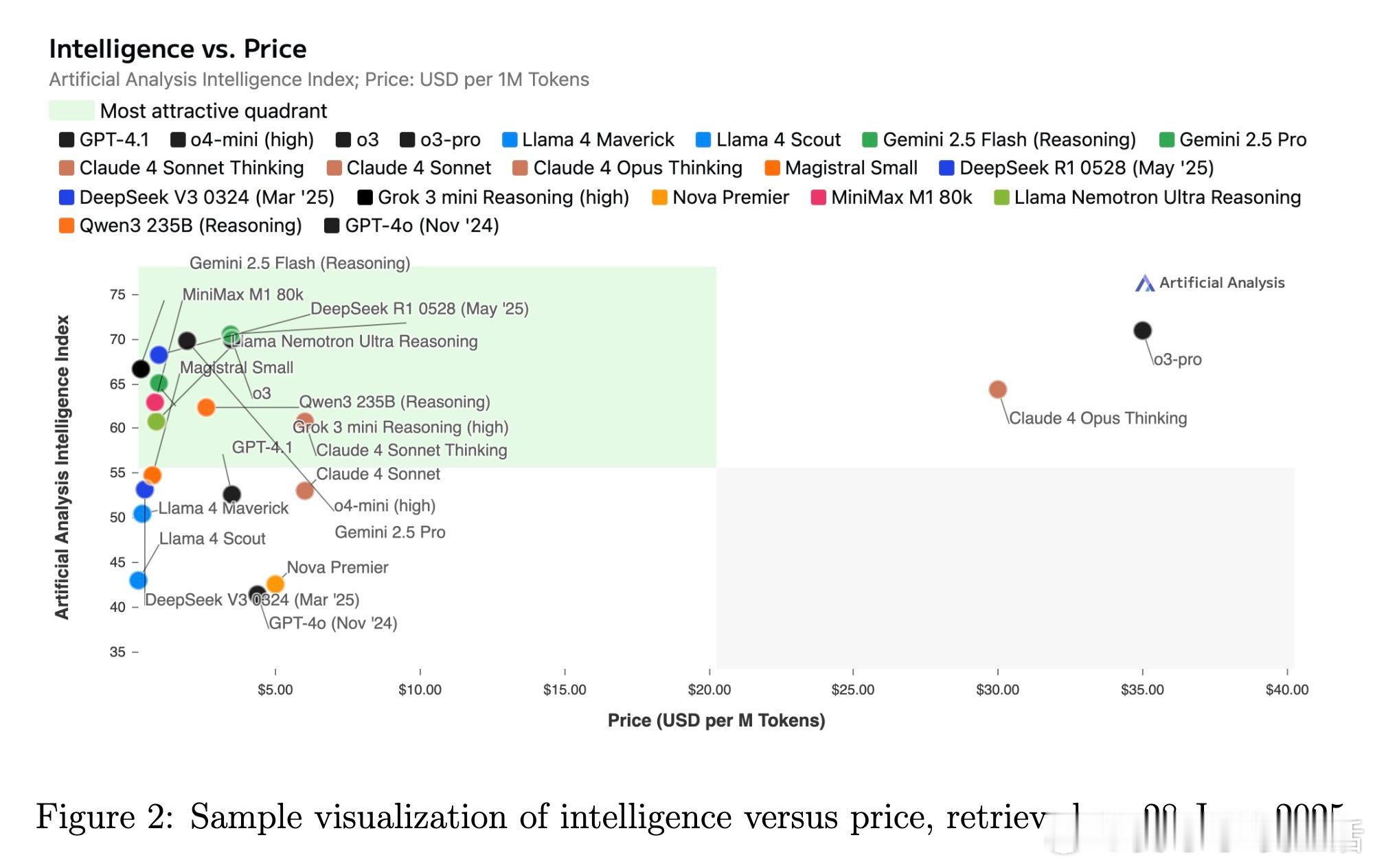
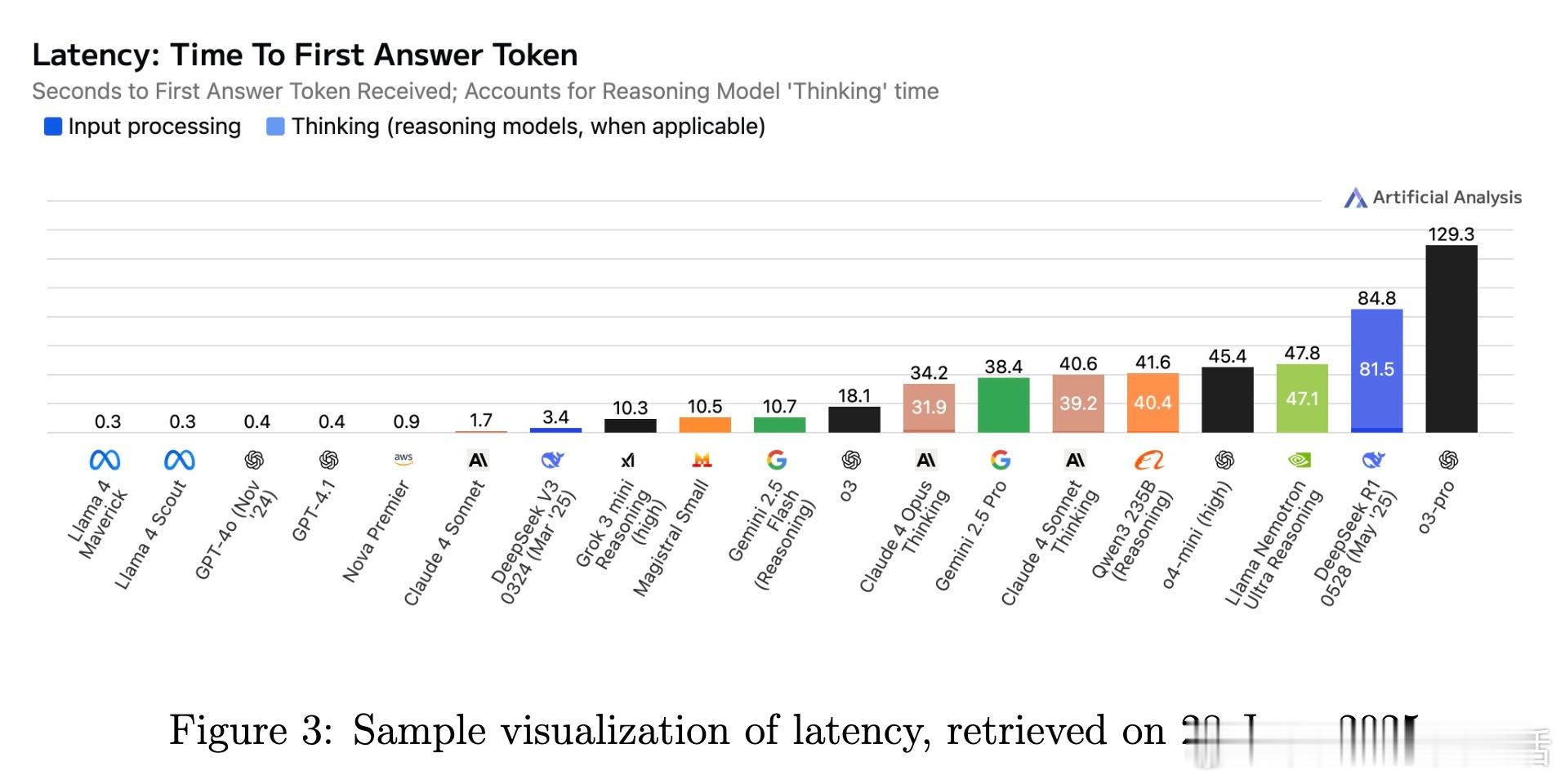
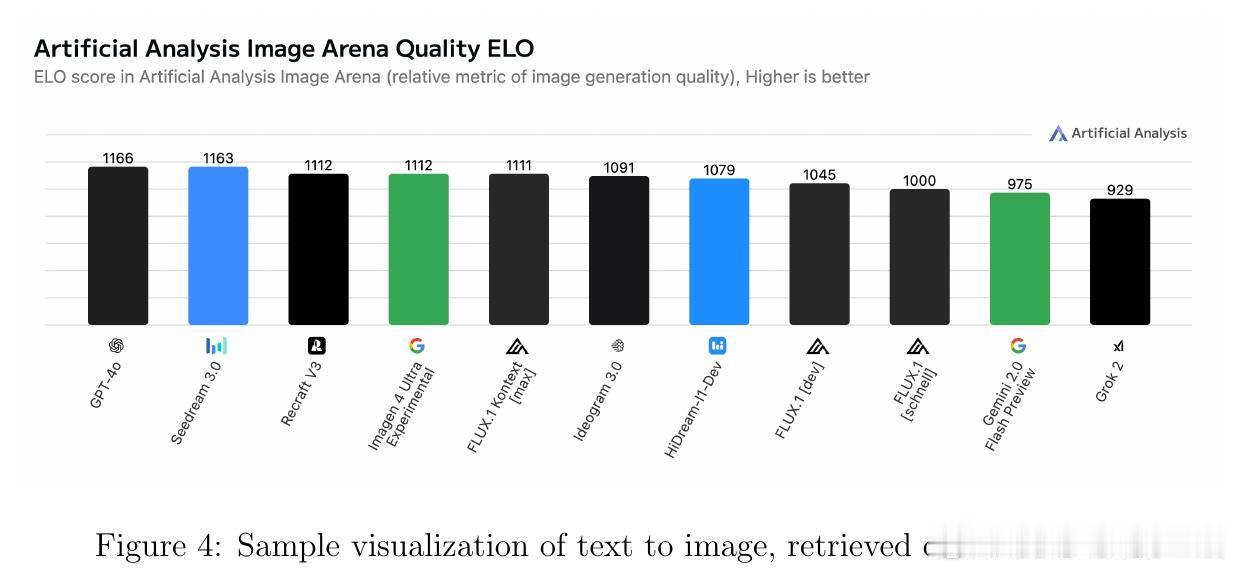
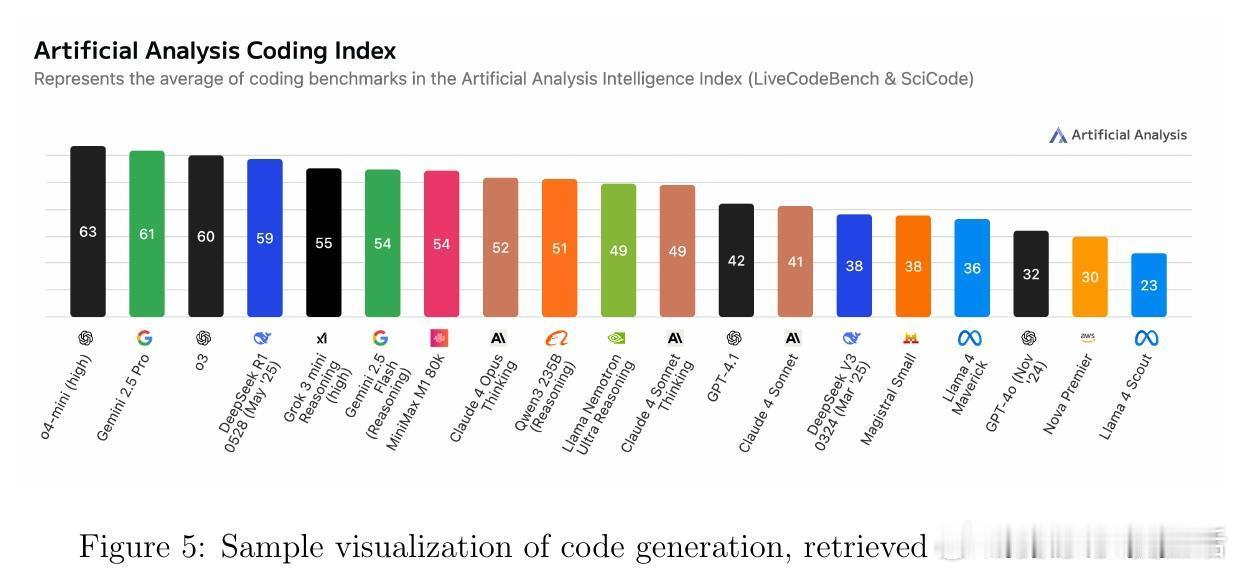
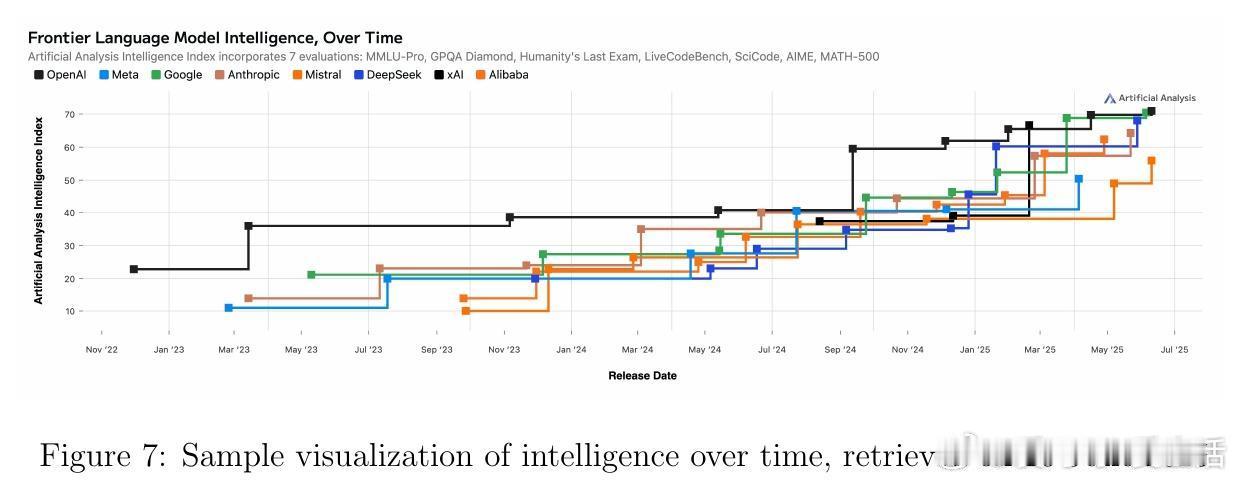
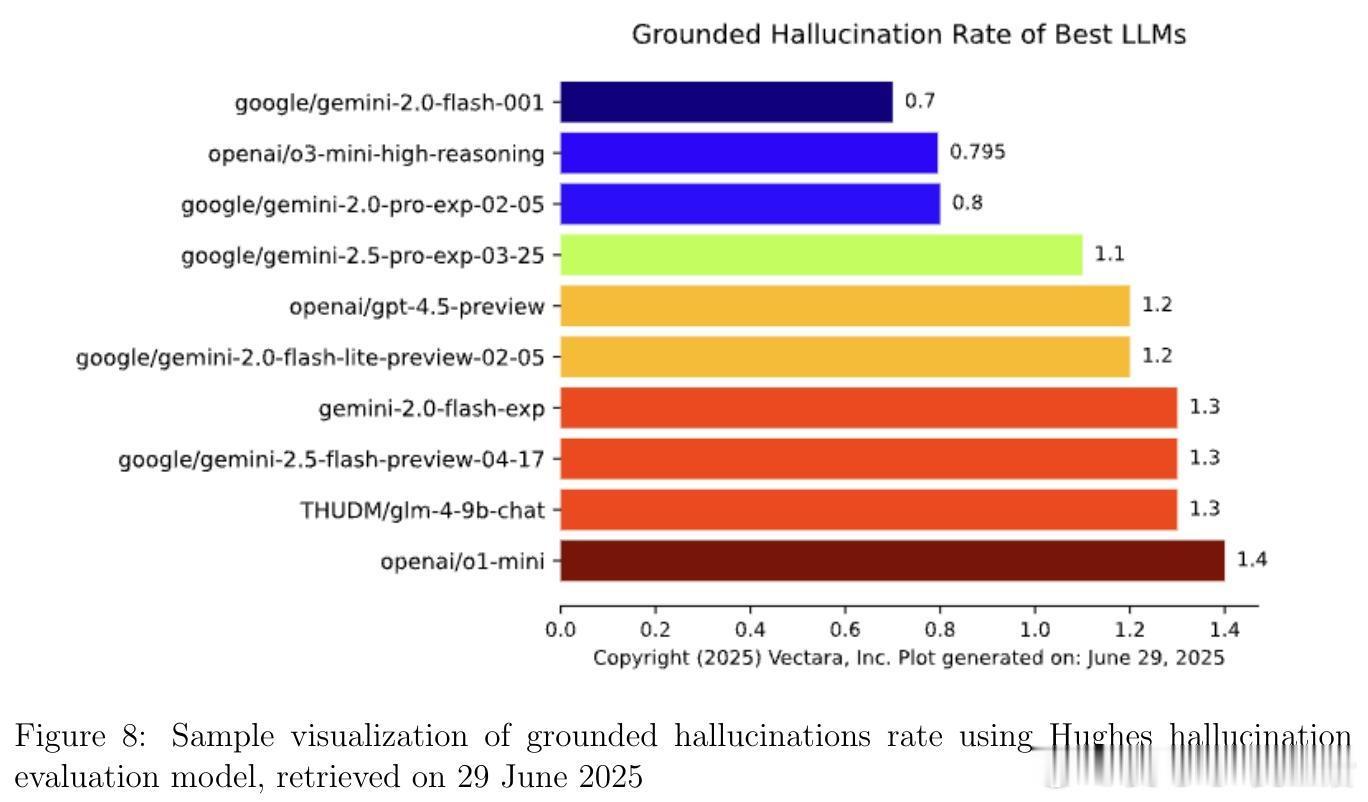
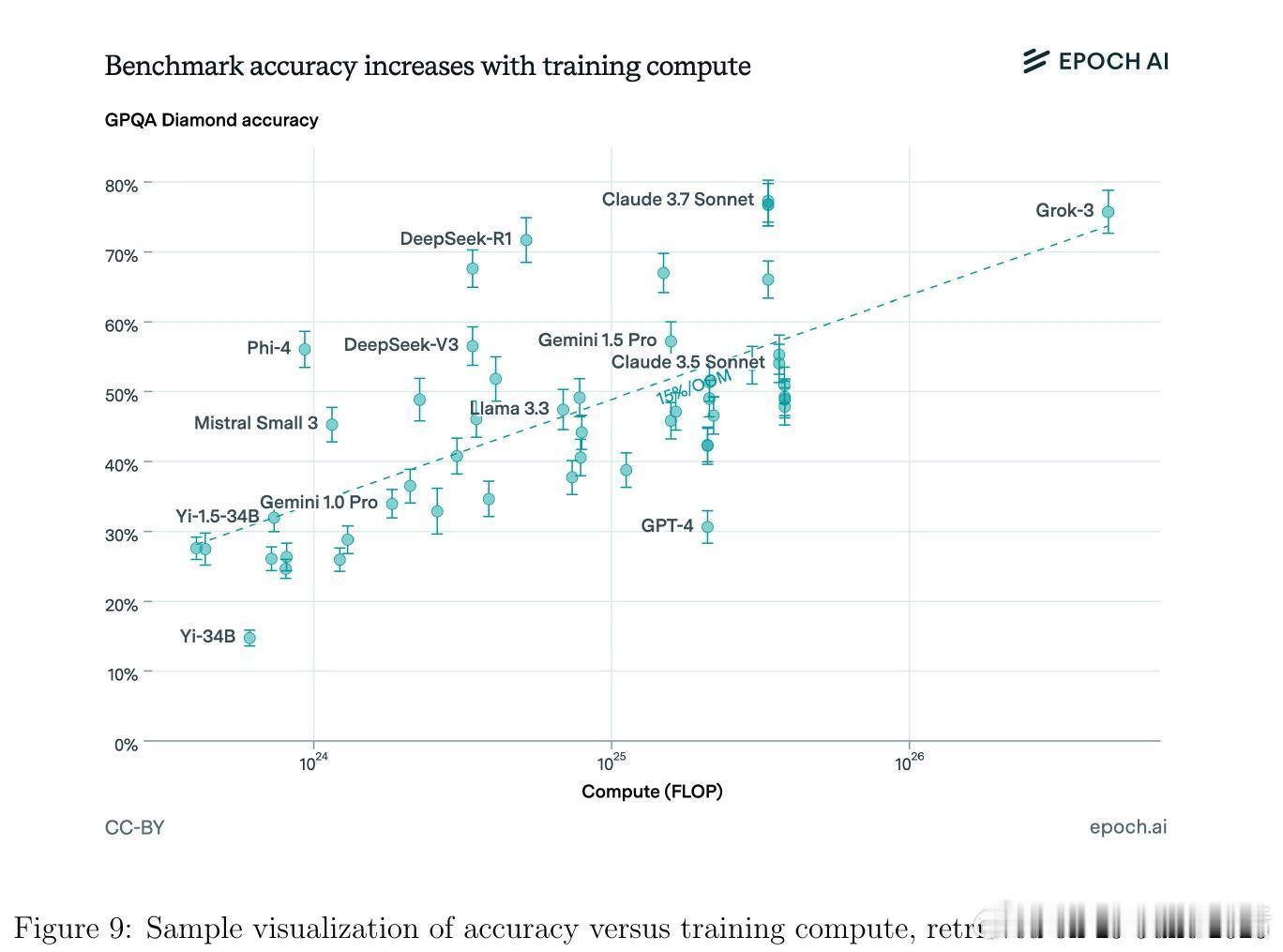
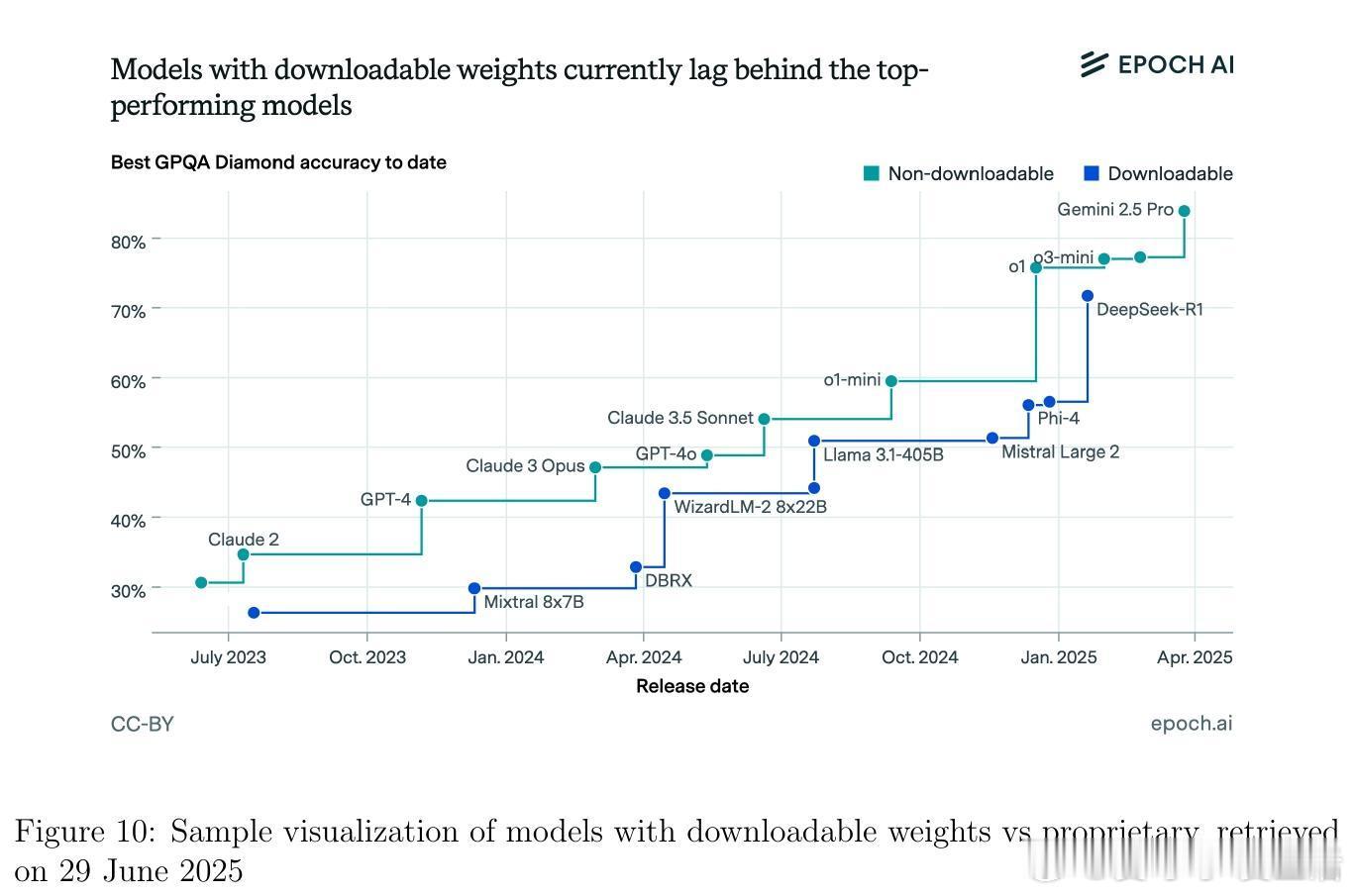
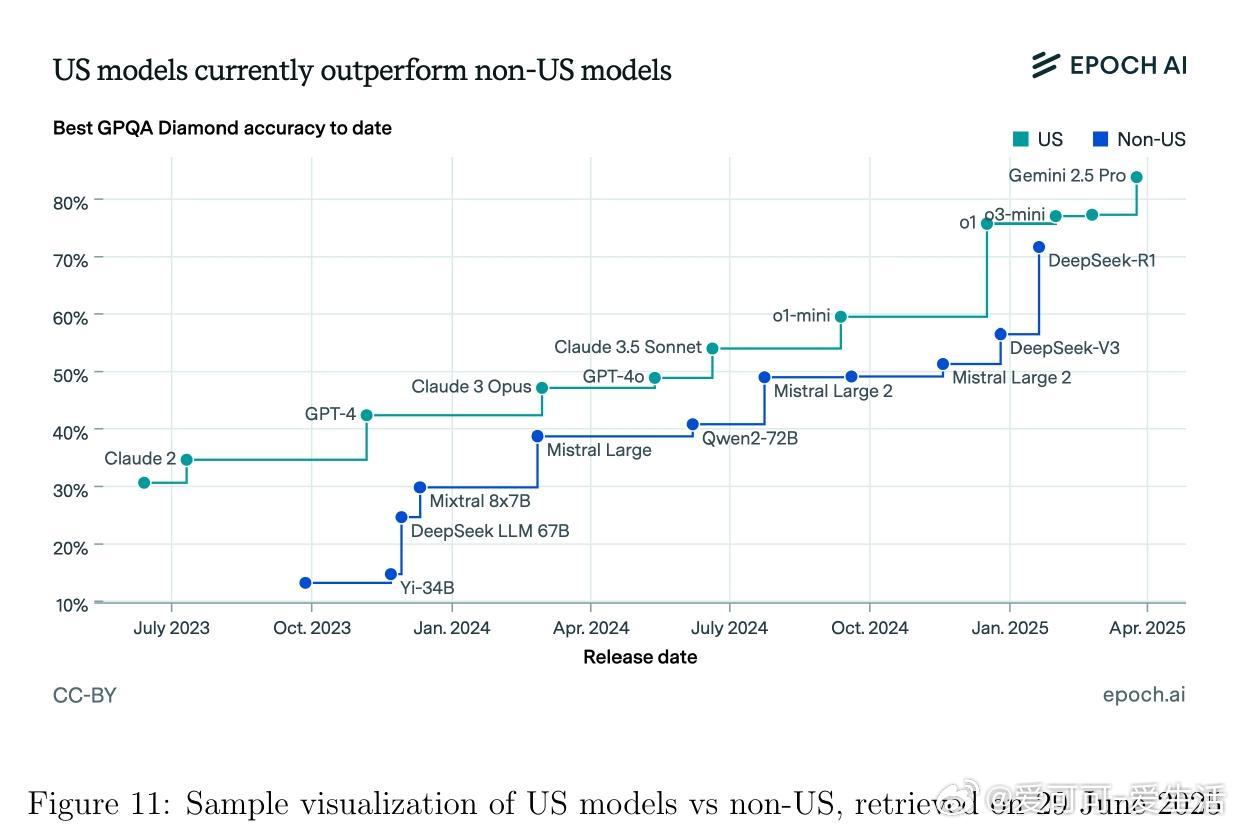
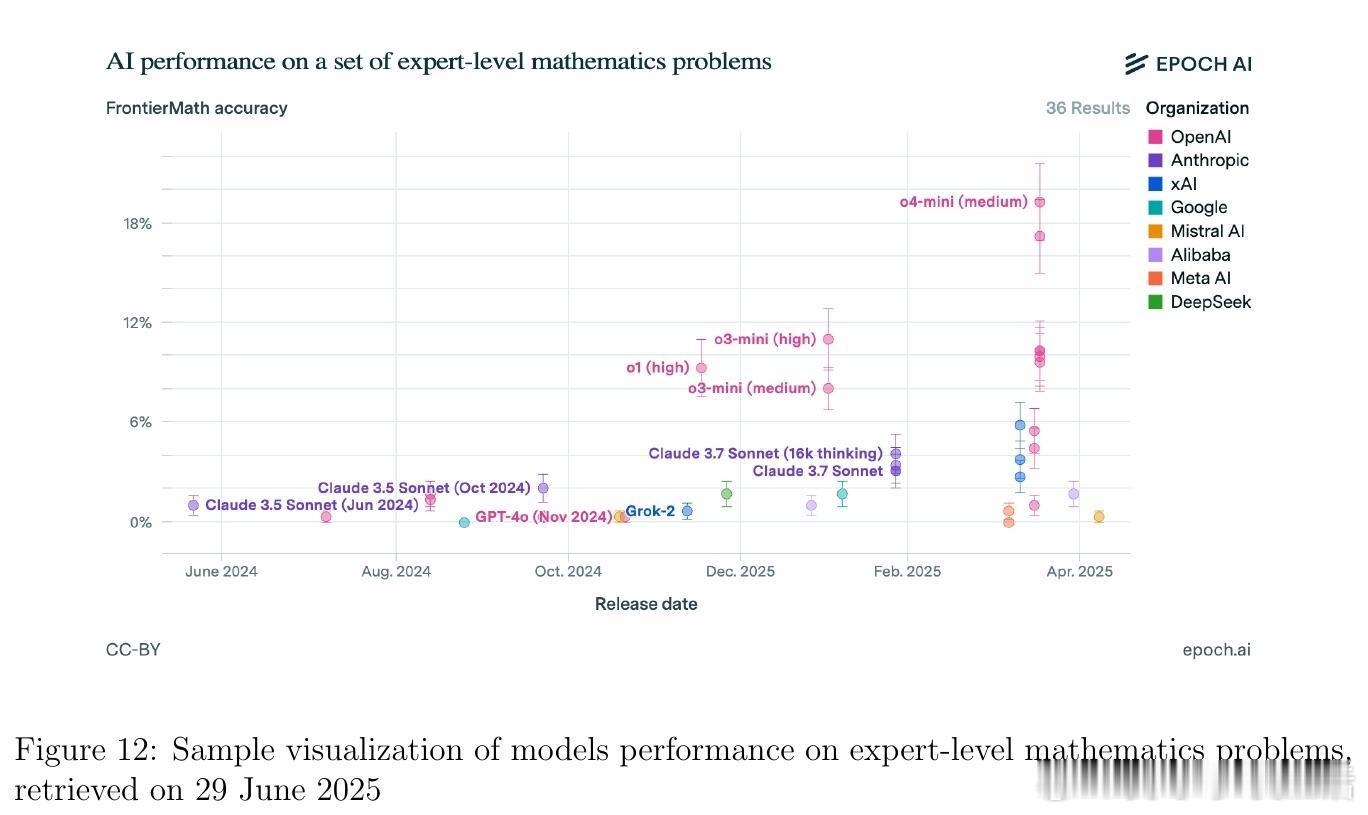
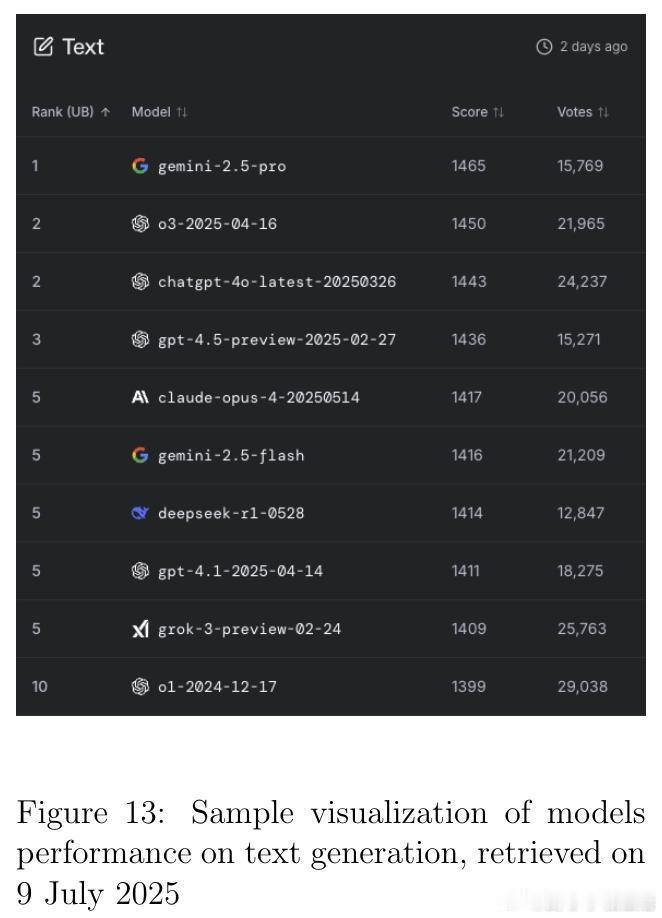
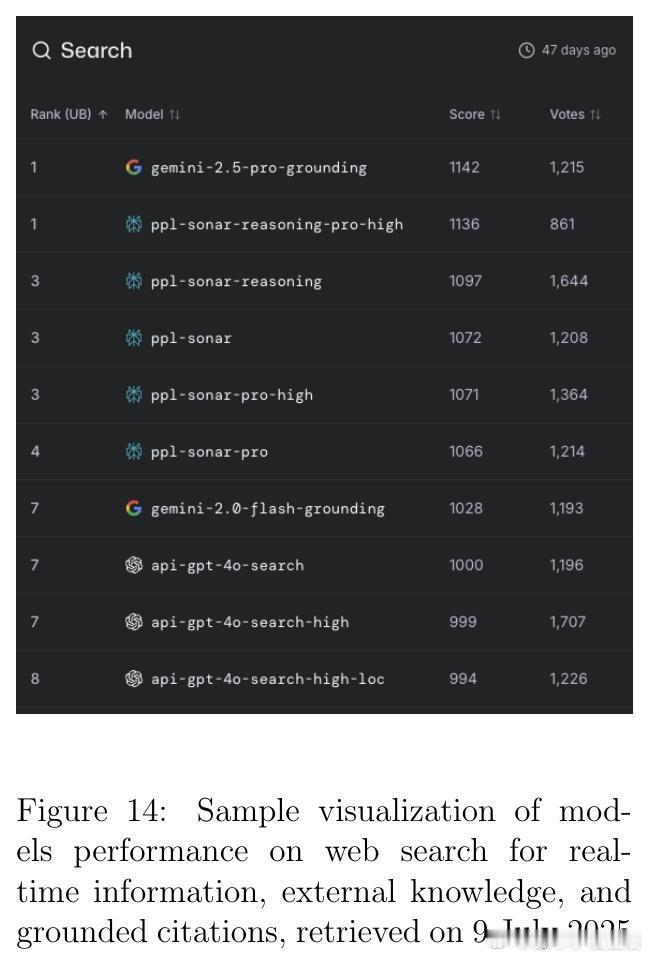
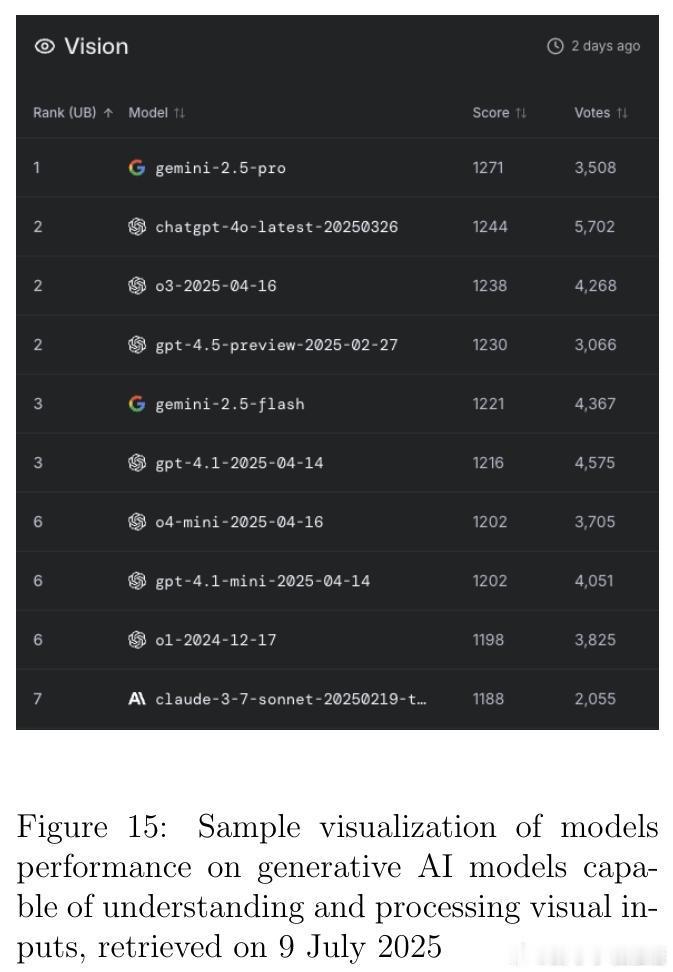
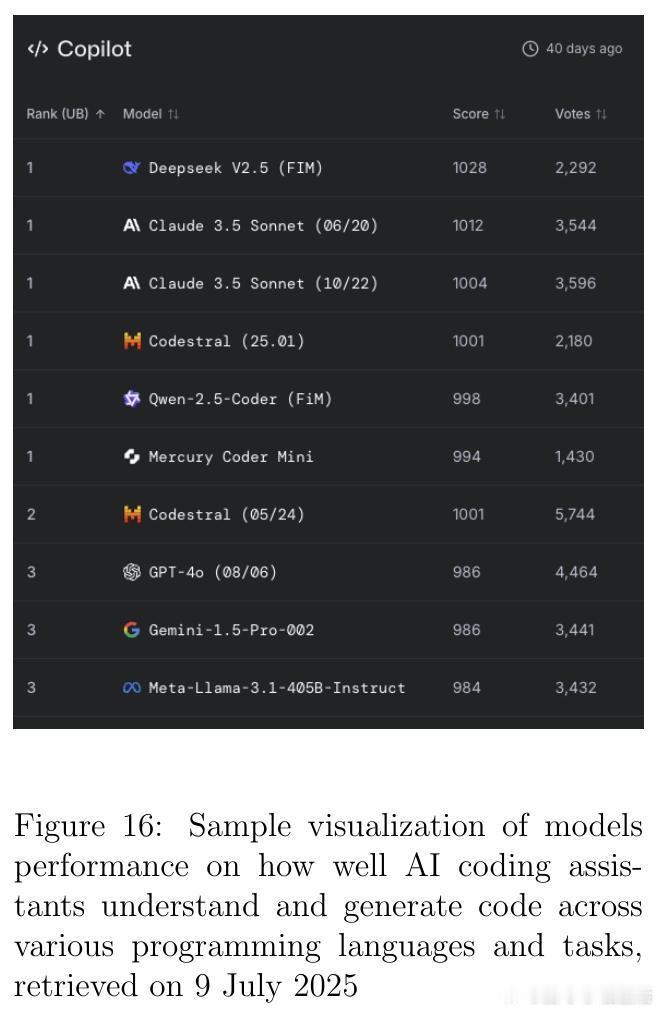
• 监测平台与资源:Artificial Analysis、Vectara Hallucination Leaderboard、Epoch AI Dashboard、LM Arena等提供实时公开的模型性能及幻觉率监控,支持社区驱动的透明评价与持续改进。
• 未来展望:
- 幻觉为LLM固有限制,关键在于构建健壮的检测和缓解体系。
- 用户界面设计应提升不确定性表达与来源标注,强化用户批判性思维。
- 责任部署需强调人类在环监督,尤其在医学、法律等安全关键领域。
- 推动统一、细粒度的幻觉分类标准与评估框架,加速科研与产业实践融合。
深度洞见👉 arxiv.org/abs/2508.01781
人工智能大规模语言模型幻觉自然语言处理模型安全知识检索人机交互