[CL]《SSRL: Self-Search Reinforcement Learning》Y Fan, K Zhang, H Zhou, Y Zuo... [Tsinghua University & Shanghai AI Laboratory] (2025)
SSRL(Self-Search Reinforcement Learning)揭示了大型语言模型(LLM)作为内置“搜索引擎”的巨大潜力,为搜索驱动的强化学习任务提供了全新范式:
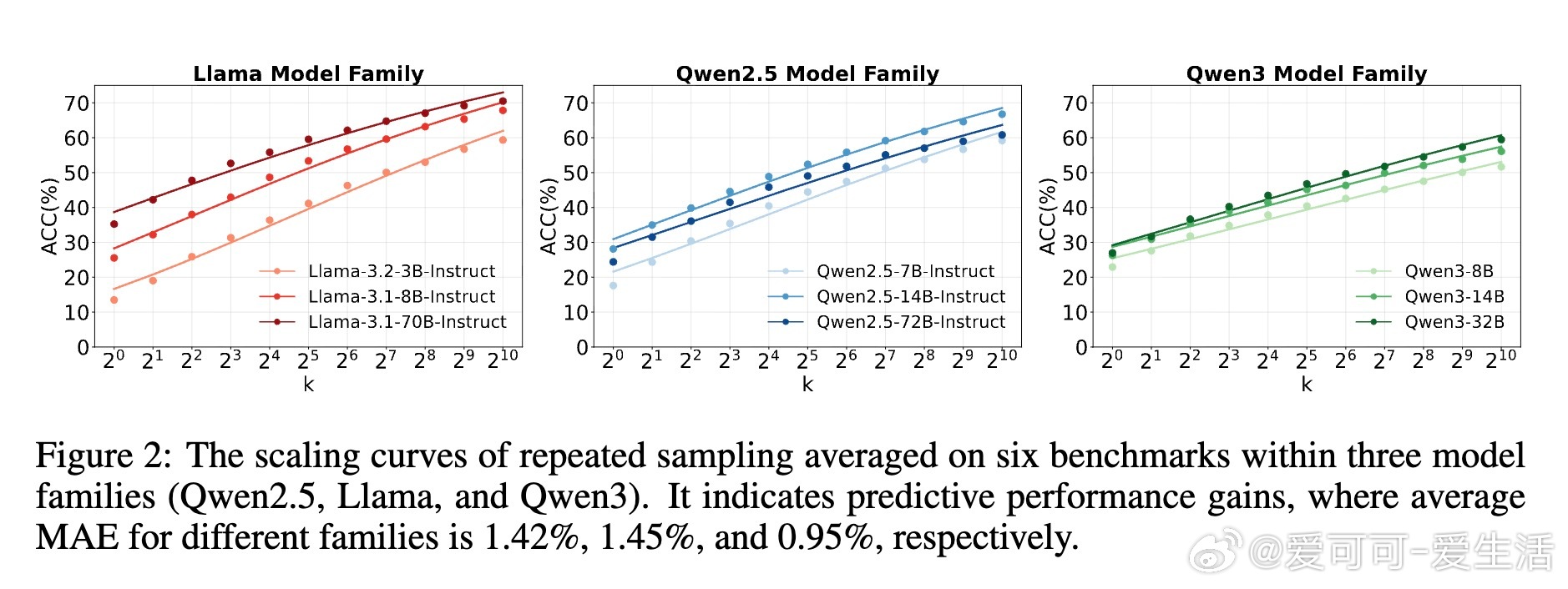
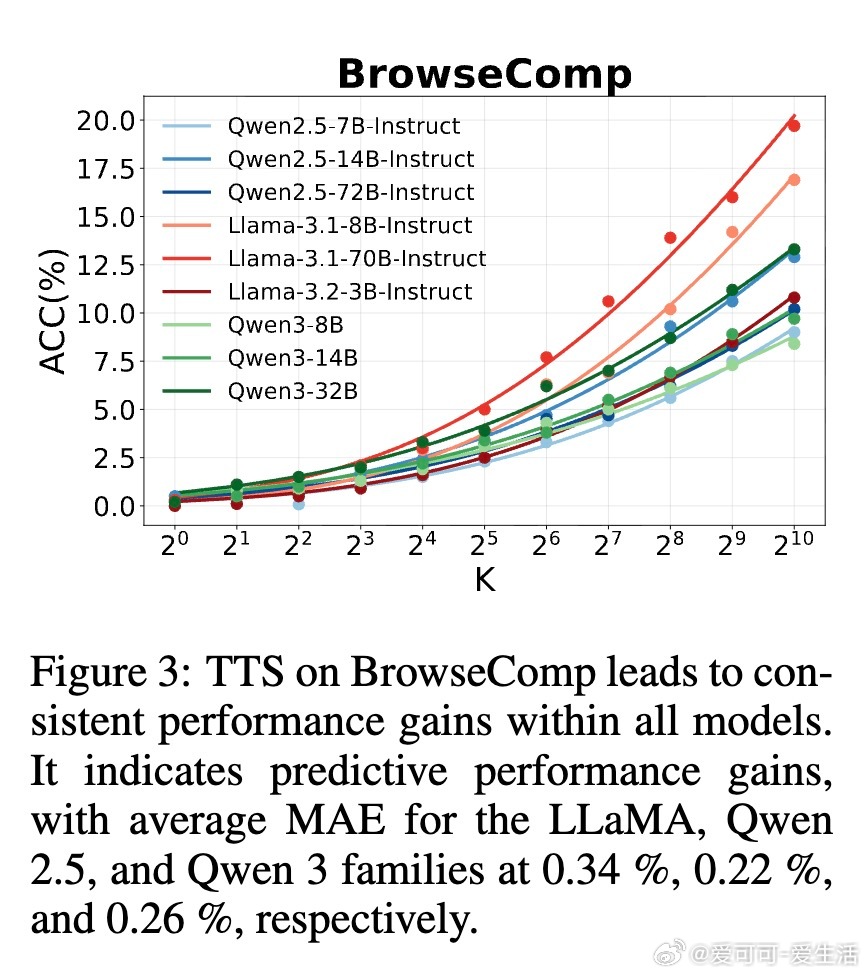
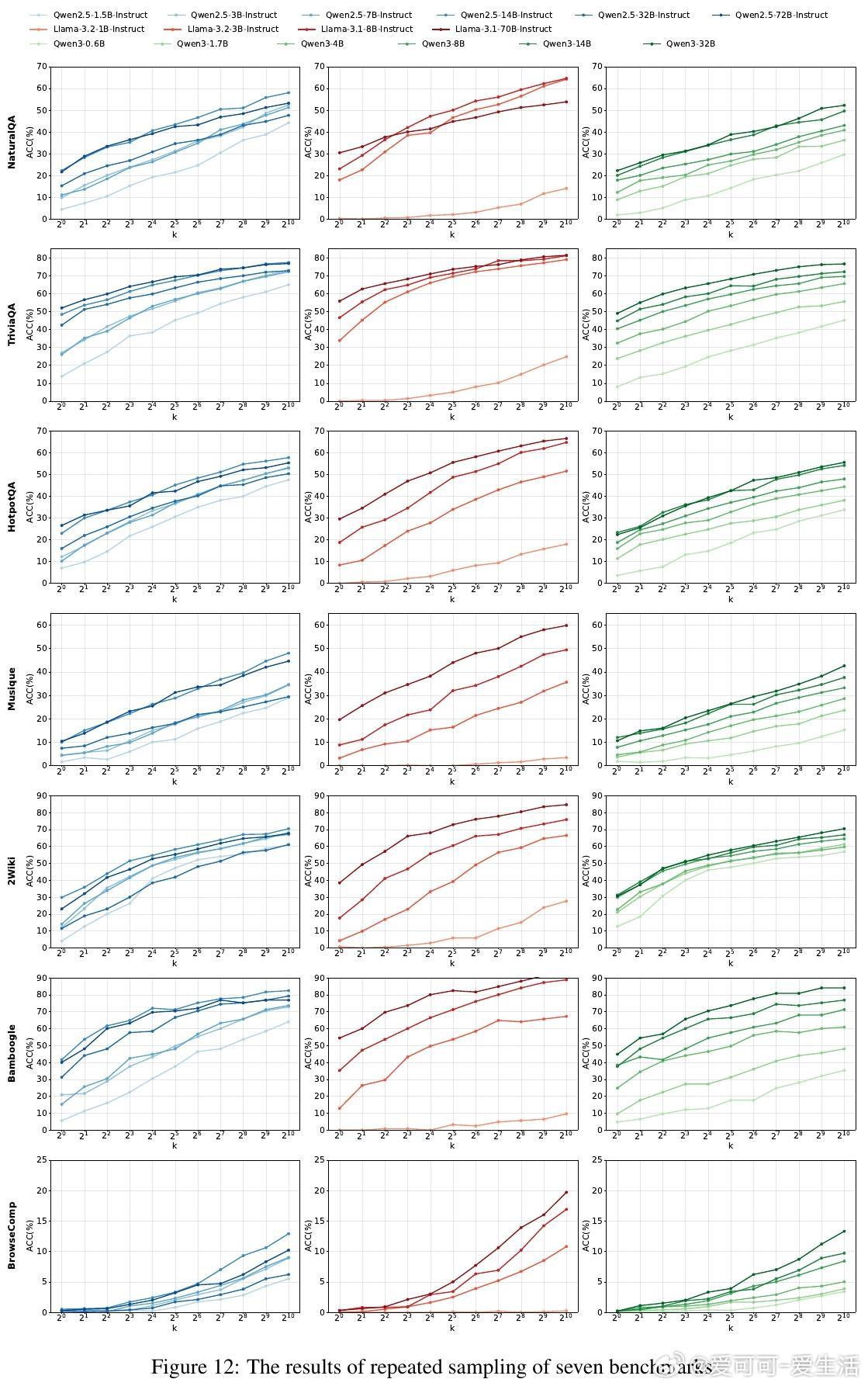
• 自搜索能力强:LLMs通过结构化提示和重复采样,实现对内部知识的高效调用,表现出显著的推理表现提升,特别是在复杂的多跳问答和开放域搜索任务(如BrowseComp)中。
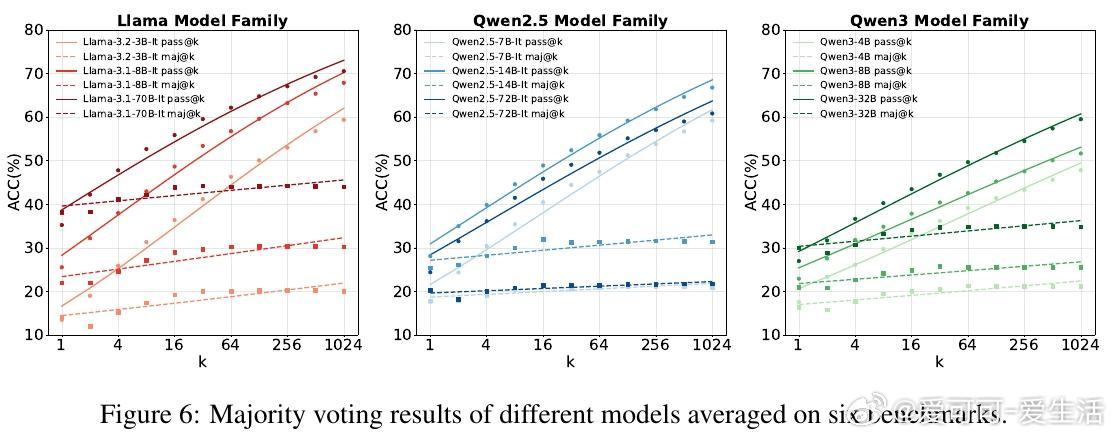
• 性能随推理预算呈规模效应增长:更多采样显著提升pass
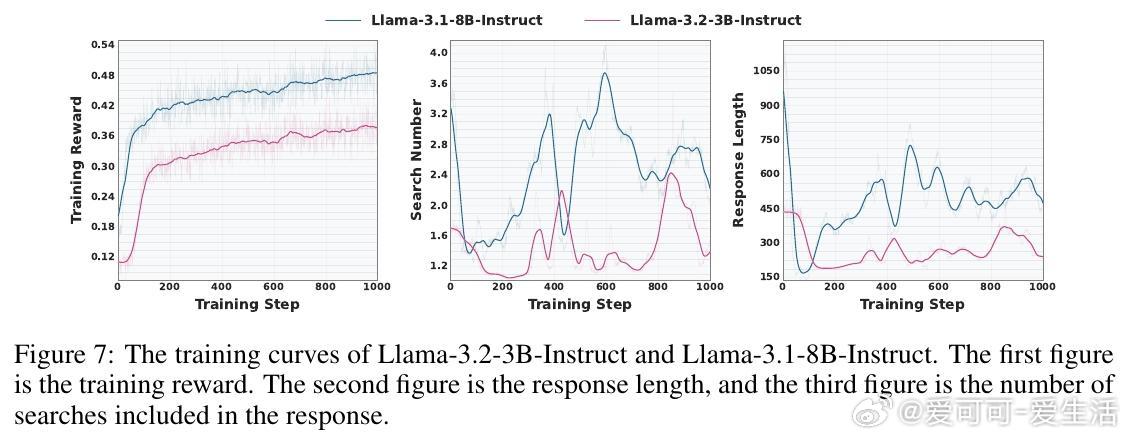
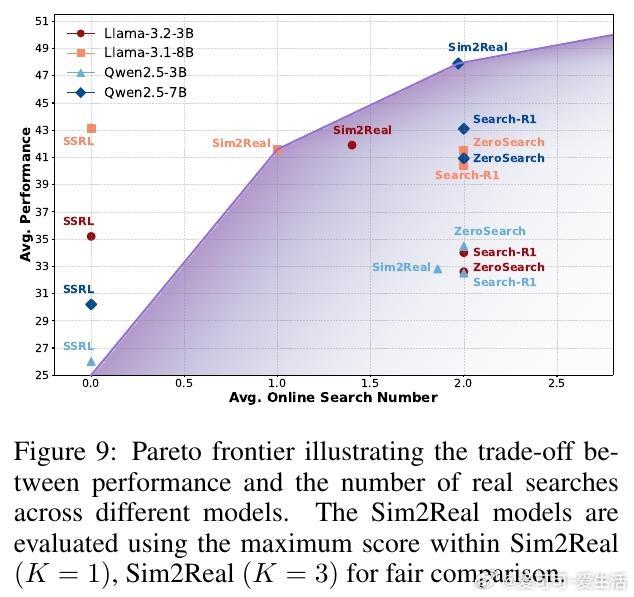
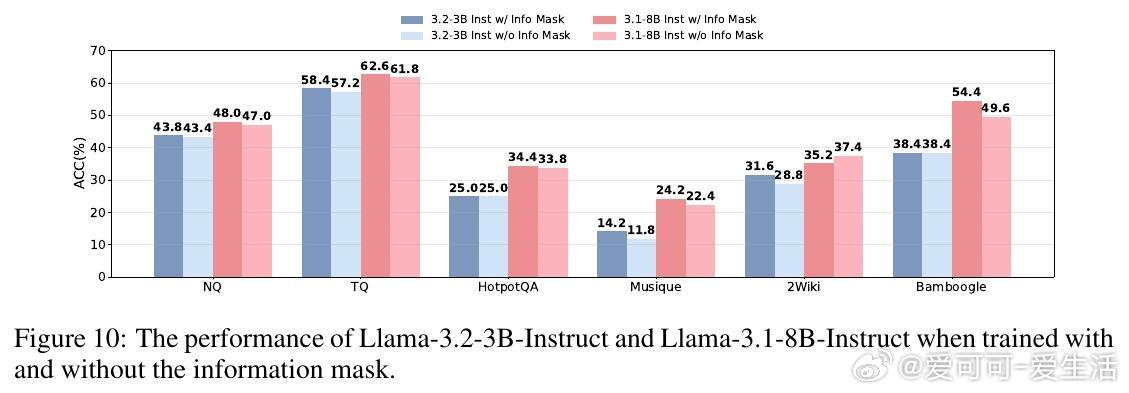
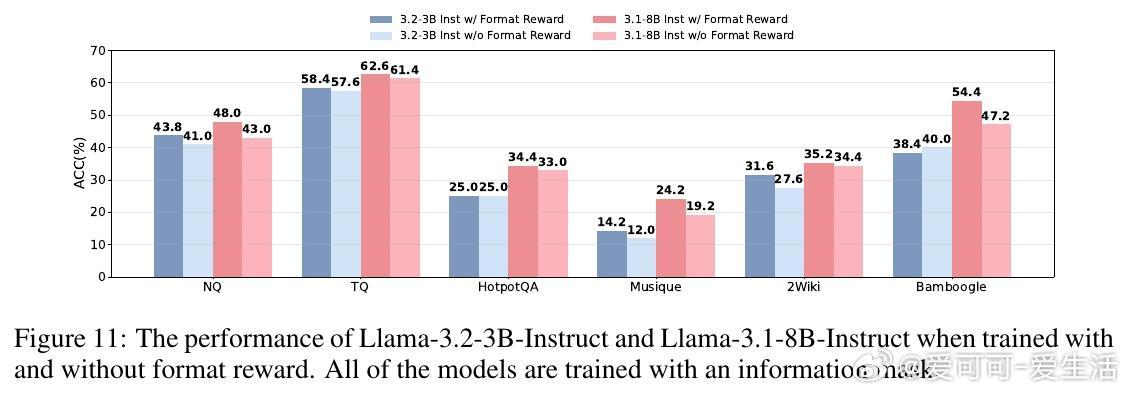
• SSRL训练优势明显:引入格式化与规则化奖励,强化模型对内部知识的调用和组织,训练出的策略模型在多基准测试中超越依赖外部搜索的强化学习基线,如Search-R1和ZeroSearch。
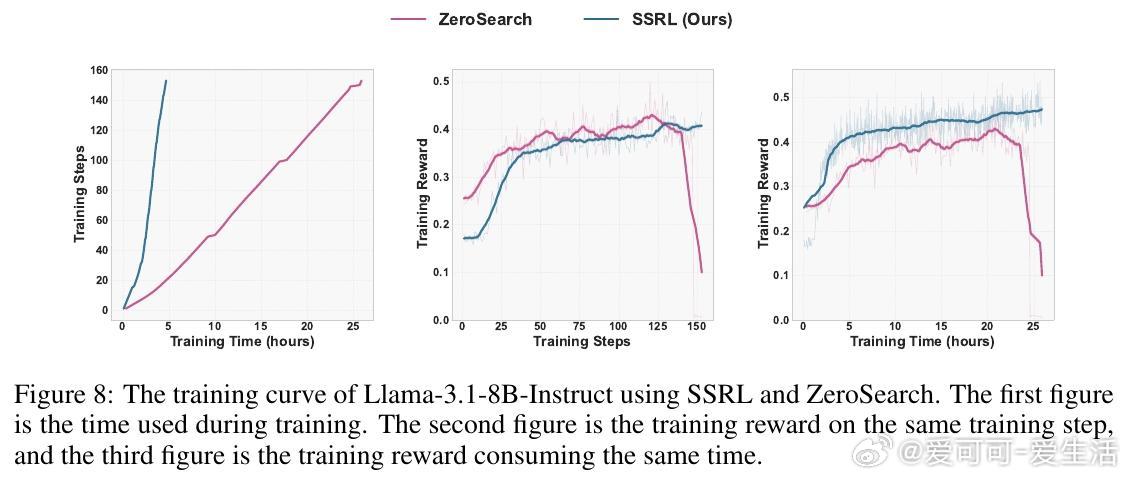
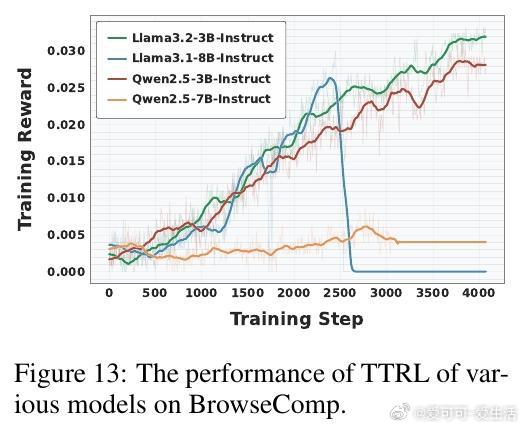
• 训练成本与效率优化:相比外部搜索RL,SSRL大幅降低训练成本,实现训练稳定且快速收敛,支持多种强化学习算法(GRPO、PPO等)的兼容适配。
• 强大Sim2Real泛化能力:训练时基于自搜索的策略可无缝衔接真实搜索引擎,支持熵引导的混合搜索策略,有效减少在线搜索调用频次,节约成本同时保持性能。
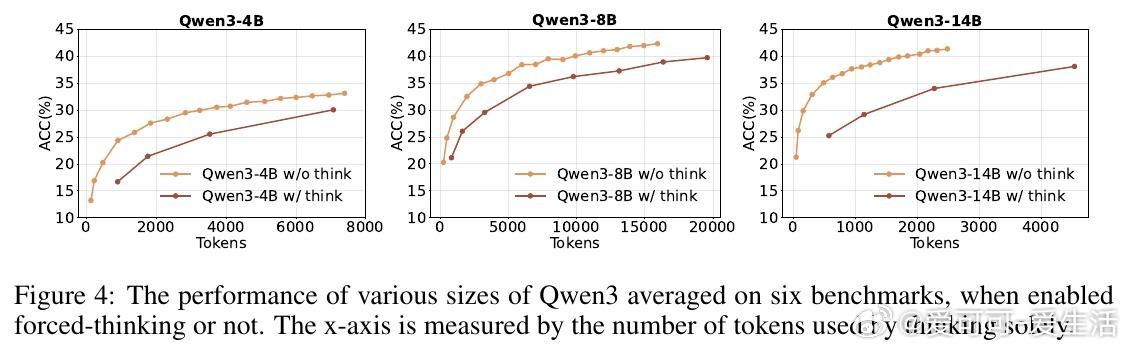
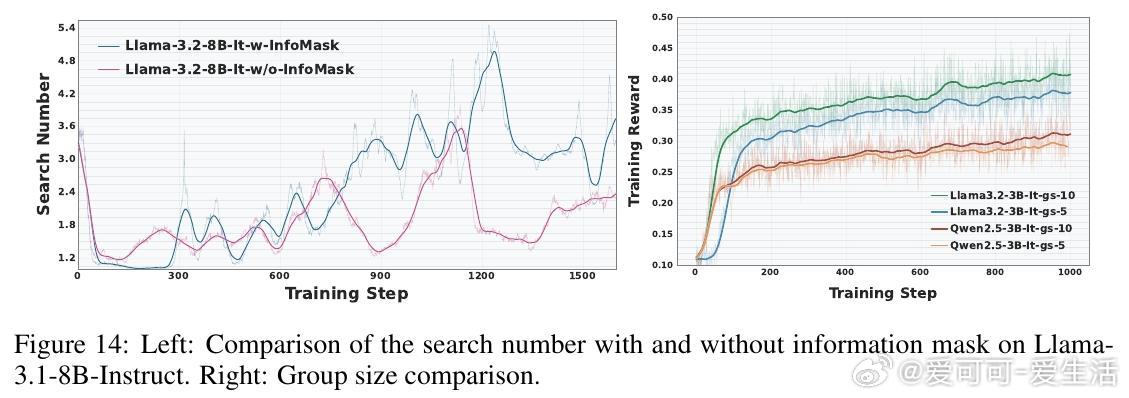
• 深层洞察:长链推理和多轮搜索并非总带来性能提升,知识的高效利用和结构化输出格式更为关键,强调知识提取与推理的平衡。
• 未来方向:SSRL为构建更自主、可扩展的LLM智能体奠定基础,推动强化学习与生成式搜索的深度融合,减少对昂贵外部资源的依赖。
详情见👉 arxiv.org/abs/2508.10874
强化学习大型语言模型自搜索知识提取Sim2Real人工智能