[LG]《SoK: Data Minimization in Machine Learning》R Staab, N Jovanović, K Mai, P Ganesh... [ETH Zurich] (2025)
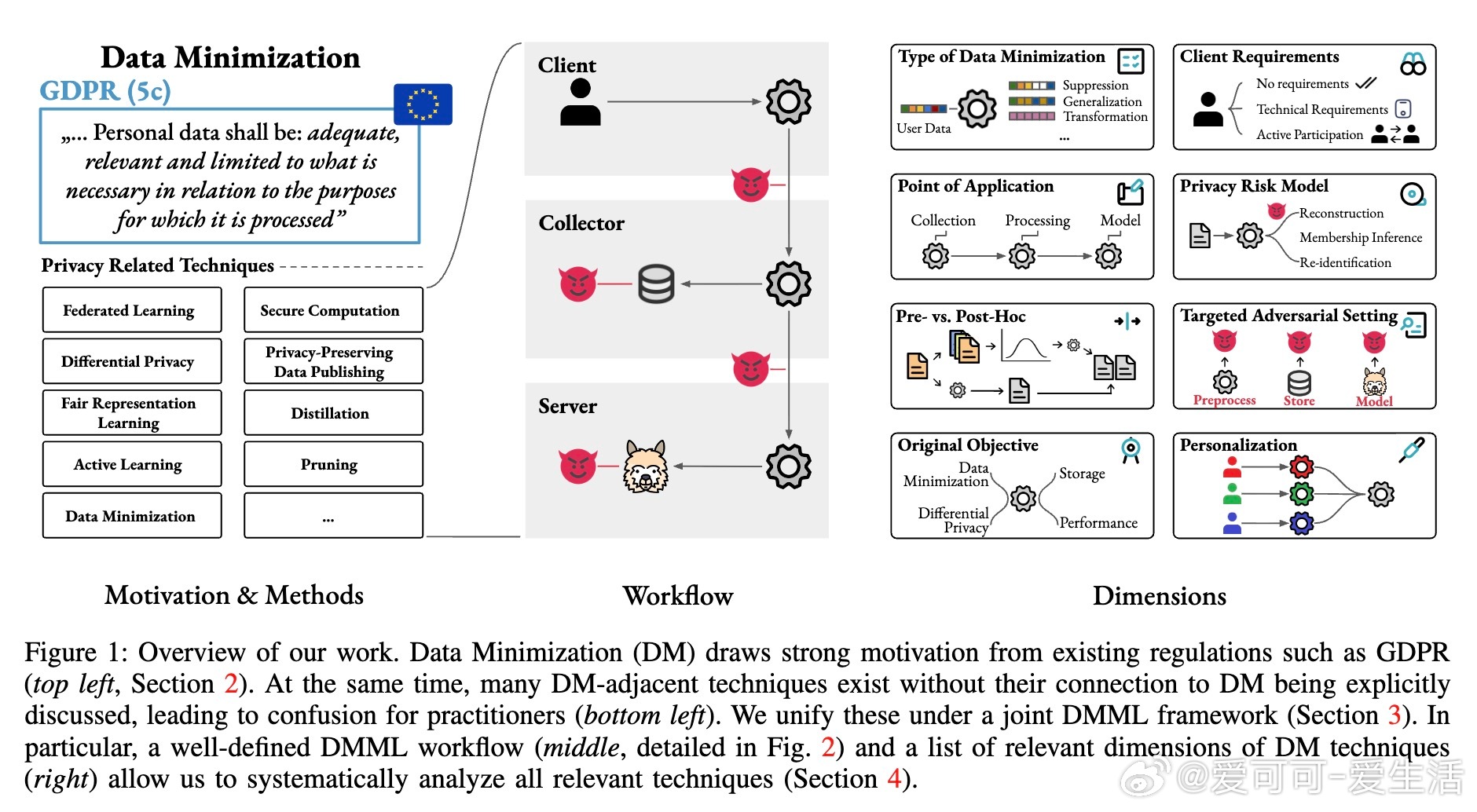
数据最小化(Data Minimization,DM)原则要求仅收集完成特定任务所必需的数据,已成为GDPR、CPRA等数据保护法规的核心。针对机器学习(ML)领域对大规模数据的依赖,最新研究提出了“机器学习中的数据最小化”(DMML)框架,统一定义了数据流程、角色、对抗方及评估指标,助力合规与隐私保护。
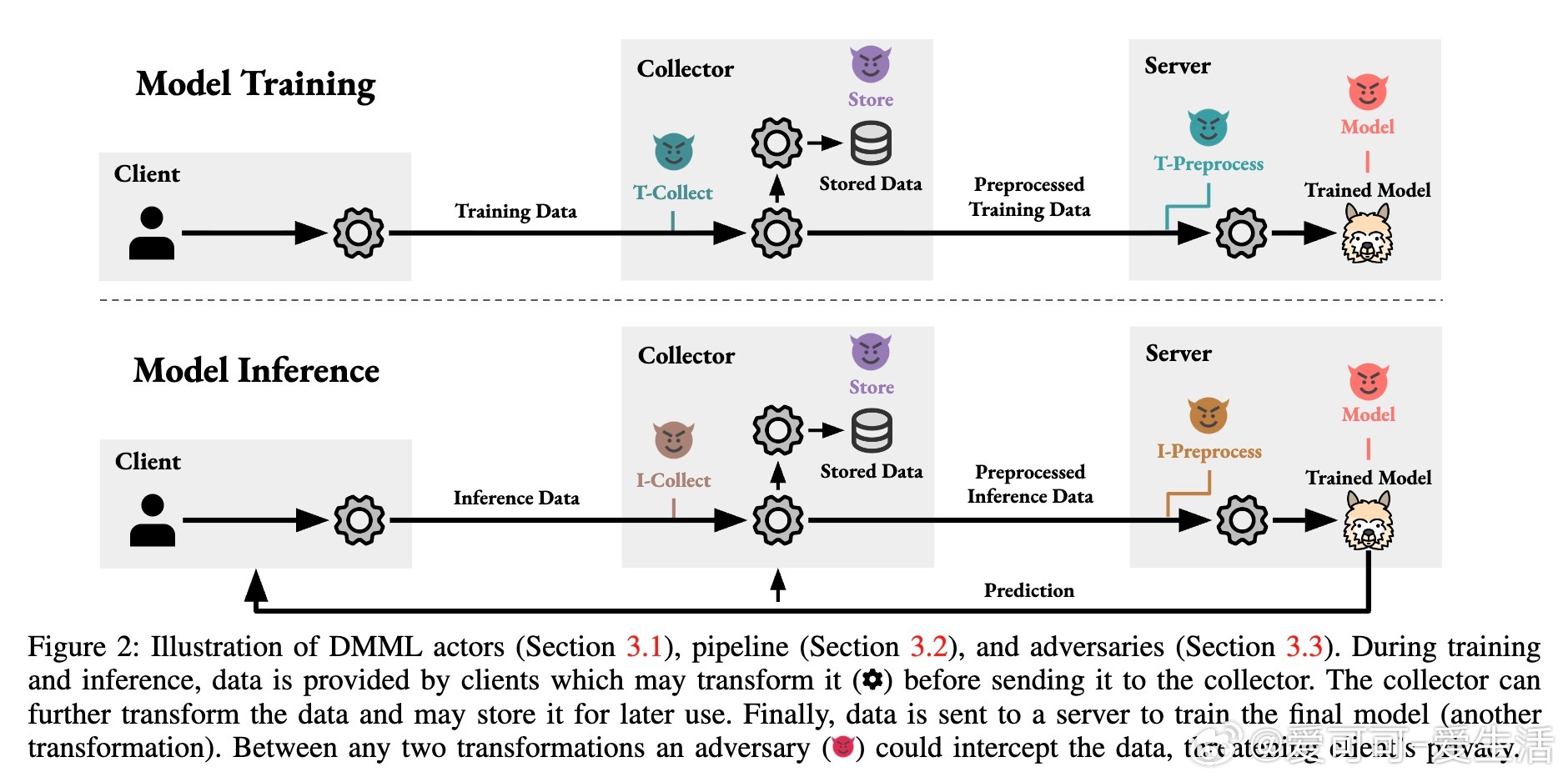
• 关键角色包括数据拥有者(Client)、数据收集者(Collector)和服务提供者(Server),数据在训练和推理阶段经过多轮转换,每轮均可能遭受不同对抗者的隐私攻击。
• DMML技术维度涵盖数据最小化的类型(横向减少样本、纵向减少特征、变换型编码等)、应用阶段(训练/推理)、执行主体(客户端/收集者)、执行时机(预处理前后)、客户端需求(无/技术能力/主动参与)和隐私风险模型。
• 代表性技术包括:
– 联邦学习(Federated Learning):客户端本地更新模型,防止原始数据外泄,但模型更新可泄露训练样本信息,需结合差分隐私和安全计算增强保护。
– 差分隐私(Differential Privacy):提供形式化隐私保证,中央DP保护模型对训练数据的影响,局部DP和分布式DP可更早阶段保护数据,但通常引入性能损失。
– 安全计算(Secure Computation):如同态加密和多方安全计算,允许加密数据训练/推理,保护数据收集和传输阶段,但计算开销大,且对模型访问攻击无防护。
– 隐私保护数据发布(PPDP):通过k-匿名、ℓ-多样性、t-接近性等技术,泛化或抑制敏感属性,保护发布数据隐私,适用于可信收集者环境,存在效用-隐私权衡。
– 合成数据生成(Synthetic Data):用生成模型替代真实数据,降低个体隐私泄露风险,但训练阶段需全量数据,生成数据可能存在记忆攻击风险。
– 特征选择(Feature Selection):去除无关特征,天然符合纵向数据最小化,减少隐私暴露,但通常基于效用驱动,缺少显式隐私保障。
– 主动学习(Active Learning):动态采集标签或特征,避免无谓数据收集,兼顾横向和纵向DM,但对采集样本隐私风险提升。
• 评估指标包括模型效用、数据规模、隐私风险(重建攻击、链接攻击、单独识别攻击、成员推断攻击)等,隐私与效用存在根本性矛盾,需权衡优化。
• 现实挑战在于法规定义抽象,技术实现多样且缺乏统一评价标准,研究和实践间存在脱节。未来重点在于构建标准化评估体系、实现跨技术的组合最小化策略,以及扩展到复杂数据类型(图像、文本等)和推理阶段的隐私保护。
本框架为AI/ML从业者提供清晰的术语、流程和工具视角,促进法规合规与隐私保护技术的融合应用。
详情🔗 arxiv.org/abs/2508.10836
数据最小化机器学习隐私保护联邦学习差分隐私安全计算合成数据特征选择主动学习