[LG]《Generative Data Refinement: Just Ask for Better Data》M Jiang, J G. M. Araújo, W Ellsworth, S Gooding... [Google DeepMind] (2025)
大规模模型性能的核心瓶颈正逐渐从模型规模转向训练数据的质量与多样性。生成式数据精炼(Generative Data Refinement,GDR)为提升训练数据质量提供了创新路径:
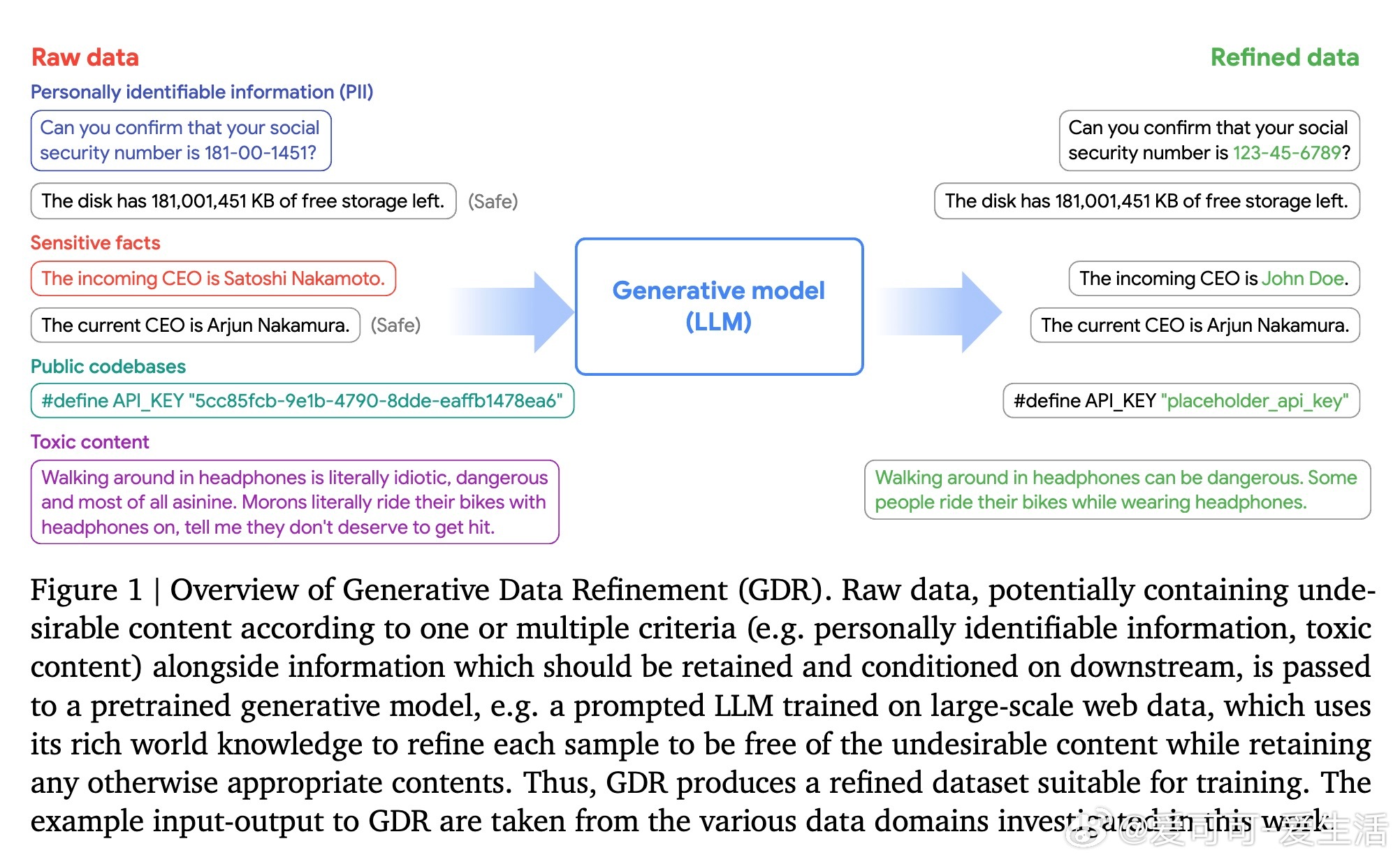
• GDR利用预训练生成模型,对原始数据进行上下文感知的重写,去除个人身份信息(PII)和有害内容,同时保留数据的有效信息,显著优于传统基于规则的检测与删除方法。
• 通过“接地”的合成数据生成,GDR能保持训练数据的多样性和真实性,避免纯模型采样带来的模式崩塌和信息丢失,极大提升合成数据的实用价值。
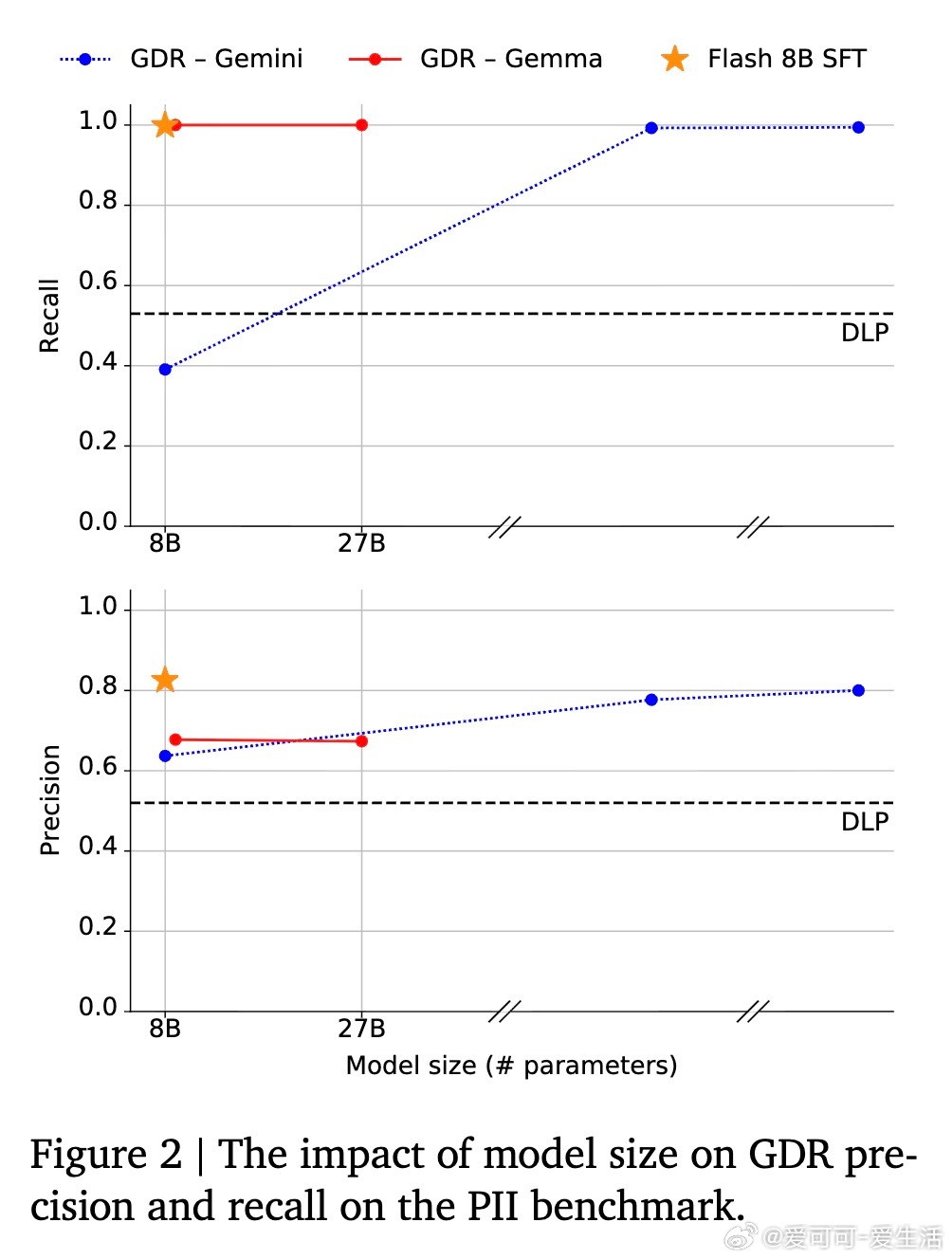
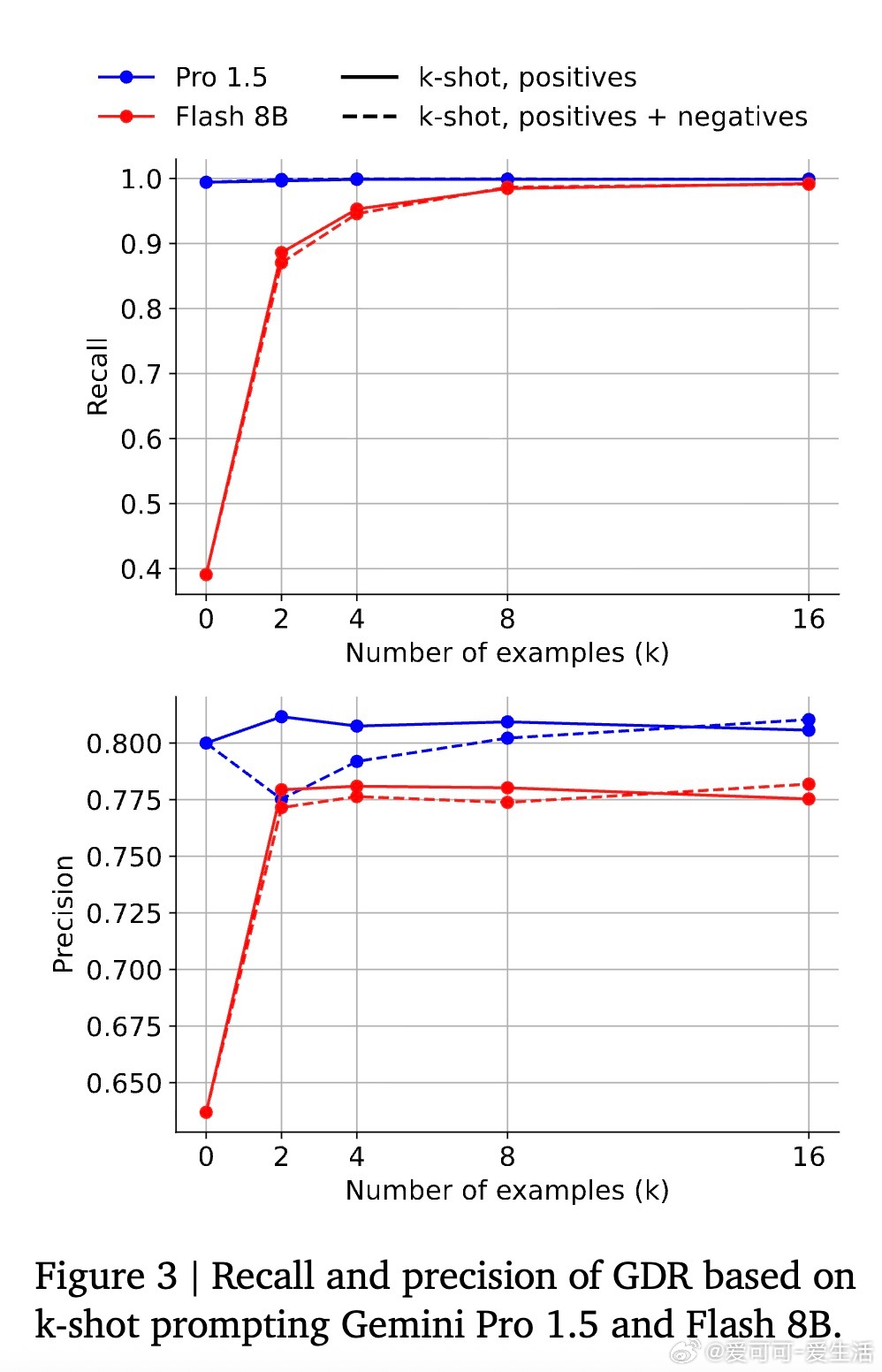
• GDR可适配多种模型规模与任务场景,通过少量示例提示或监督微调,实现中小模型高效数据精炼,降低计算成本,适合大规模工业应用。
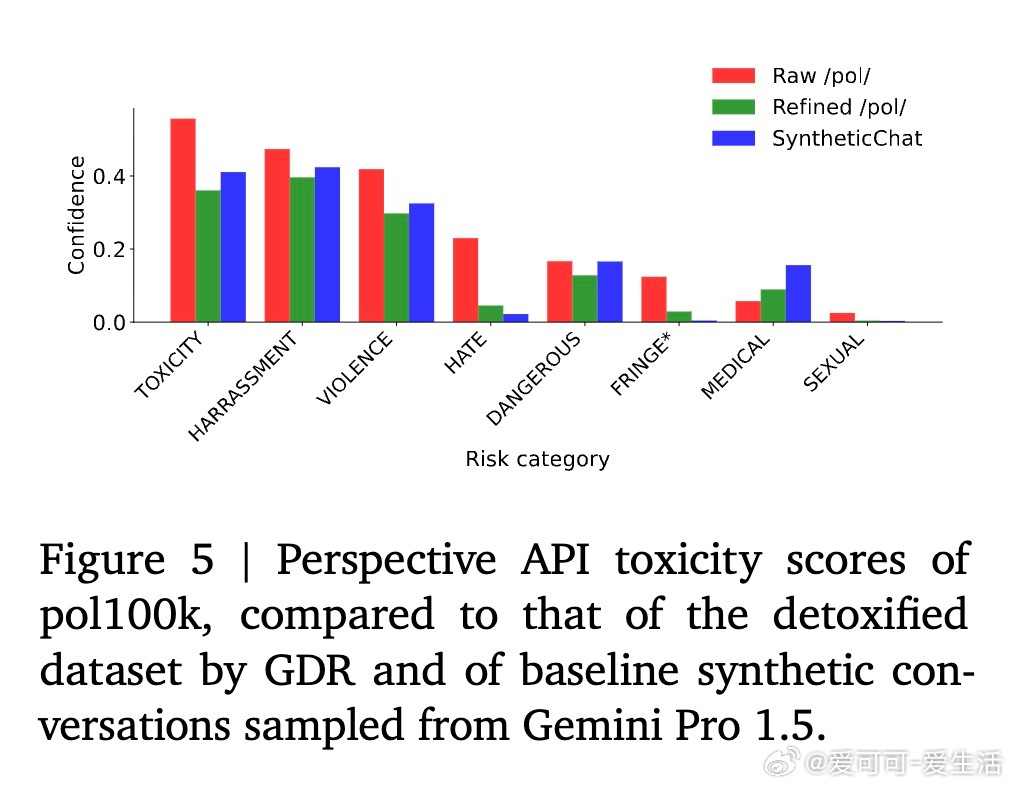
• 在代码匿名化和网络对话去毒化任务中,GDR能精准定位敏感信息并生成语义一致的替代内容,既保障隐私安全也保留训练价值。
• 经过GDR处理的数据训练出的模型在保持公共知识的同时,显著减少私人信息和毒性内容的泄露风险,显示出极强的实际应用潜力。
心得:
1. 训练数据的“质”的提升往往比“量”的扩张更为关键,GDR通过智能重写实现数据质量的跃升。
2. 结合真实数据样本进行有条件生成,解决了合成数据多样性不足的核心难题。
3. 生成模型不仅是数据生成工具,更能作为精细的数据过滤与改写引擎,开启数据安全与高效利用的新纪元。
详见🔗arxiv.org/abs/2509.08653
生成式数据精炼数据隐私保护合成数据大规模语言模型数据去毒机器学习数据安全