什么是反压
1.1 反压释义
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。由于实时计算应用通常使用消息队列来进行生产端和消费端的解耦,消费端数据源是 pull-based 的,所以反压通常是从某个节点传导至数据源并降低数据源(比如 Kafka consumer)的摄入速率。
1.2 反压的影响
checkpoint总体时间变长,最终超时失败,然后不断重试,最后job作业挂掉;state状态变大;kafka数据积压;OOM。1.3 反压的原理

1)反压的机制
数据接收速率 > 数据输出速率,压力往上游一步步传导。
2)压力传递的细节
输出缓冲区resultPartition -> local bufferpool -> network bufferpool输入缓冲区inputGate -> local bufferpool -> network bufferpool1.4 反压的原因
资源不合理(cpu少了,内存小了,并行度小了);数据倾斜;代码性能低;与外部系统交互。反压的定位
2.1 通过web UI BackPressure,可以看出具体作业的忙碌状况
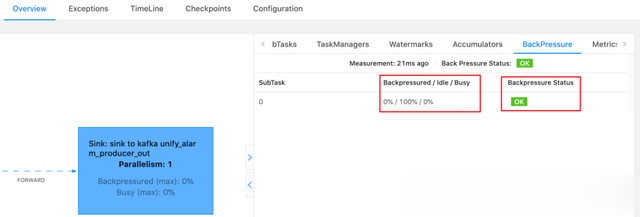
2.2 通过web UI metric,主要分析输入缓冲区和输出缓冲区的占比,如果输出缓冲区100%,说明下游对他造成了压力,数据一致没有输出到下游

反压分析
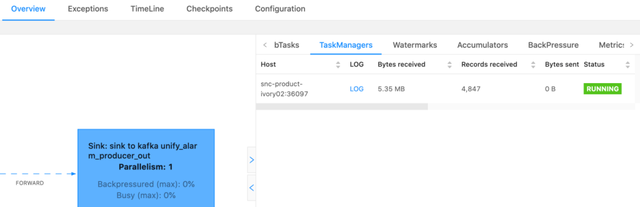
3.1 通过SubTasks分析
可以看到任务的接收字节数,和输出字节数,可以看出数据是不是出现了数据倾斜。
3.2 通过火焰图分析
具体开启方式分为两种,代码里面设置参数开启,和yarn作业提交时参数设置开启。
纵向:调用链,最上面的是执行中的;横向:可以理解为执行时长。总结:找最上面最长的那个,然后定位代码。

3.3 分析GC日志
通过参数指定,打印GC日志;通过web ui下载;通过gc工具打开gc日志,查看是不是出现了fullgc情况,分析是不是出现了内存泄露。3.4 与外部系统交互
适当的增加缓存,或者异步IO,对于mysql,clickhouse等数据库,适当的攒批可以提高吞吐量。提高性能。
总 结:
反压是 Flink 应用运维中常见的问题,它不仅意味着性能瓶颈还可能导致作业的不稳定性。
定位反压可以从 Web UI 的反压监控面板和 Task Metric 两者入手,前者方便简单分析,后者适合深入挖掘。
定位到反压节点后我们可以通过数据分布、CPU Profile 和 GC 指标日志等手段来进一步分析反压背后的具体原因并进行针对性的优化。