
该研究团队来自伊利诺伊大学厄巴纳-香槟分校(UIUC)。核心贡献者之一 Haofei Yu 为计算机系博士生,另一位核心贡献者 Fenghai Li 为计算机系本科生,指导教师 Jiaxuan You 为计算机系助理教授,指导 UIUC U Lab。Jiaxuan You 教授的研究聚焦于大模型智能体(Agentic LLM)的基础能力、垂直应用、生态建设,博士毕业于斯坦福大学,已在 NeurIPS、ICML、ICLR 等顶级会议发表论文三十余篇,总引用量近两万次,多次担任 Area Chair 并组织 Workshop;其开发或主导的开源项目累计获得三万余颗 Star。
「在大模型热潮中,如何真正评测它们的智能?」
过去的评测多停留在知识问答、推理或指令理解层面。而 LiveTradeBench 首次让大模型「下场交易」——在真实金融市场的动态博弈中,检验其感知、推理与决策能力。
LiveTradeBench 的研究启动于数月前,并连续进行了为期五十天的实盘测试,覆盖美股市场与去中心化预测市场 PolyMarket,是最早探索「实盘智能体评测」的工作之一。
在这里,模型不仅要理解财经信息,更要在不确定性中学会下注与取舍。
值得强调的是,LiveTradeBench 全面开源:所有数据源、模型决策与仓位记录、表现结果、以及大模型推理全过程均公开透明,为研究社区提供了可复现、可验证的大模型实盘测试基准。
项目主页:https://trade-bench.live 开源地址:https://github.com/ulab-uiuc/live-trade-bench 技术报告:https://trade-bench.live/assets/live_trade_bench_arxiv.pdf从「测知识」到「测财商」:
智能评测的新前沿
过去两年,大语言模型(LLM)在各类静态基准上成绩惊人:无论是知识问答(MMLU、GPQA)、数学推理(GSM8K、CodeElo),还是指令遵循(FollowBench、Instruction-Bench),顶尖模型几乎「卷到满分」。
但这些测试有一个共同点——它们都是静态的、单轮的、无反馈的。它们只能衡量模型在固定输入上的一次性推理能力。而真实世界要求模型具备连续观察、长期推理与动态适应能力。
为此,研究者们开始构建各种 Agent 环境,让模型「动起来」。然而,多数环境仍是封闭的、逻辑预设的。模型能「操作」,却难以真正「动态适应」。
而市场正是最具挑战性的真实动态系统——信息不完全、反馈延迟、风险与机会并存。
LiveTradeBench:让 LLM 真正下场交易,是目标在真实市场流数据上运行的大语言模型交易与投资评测平台。
三大核心创新
实时流式数据,无信息泄漏
在表 1 中可见,以往工作多依赖离线回测或静态问答,难以反映市场的不确定性。
LiveTradeBench 直接对接真实股票与预测市场(PolyMarket)数据,让模型在动态变化中实时决策,彻底杜绝信息泄漏。
组合层次的投资决策
在表 1 中可见,相比单一资产的买卖决策,LiveTradeBench 引入组合级别(portfolio-level)的动态配置任务,要求模型在收益与风险间权衡,随市场信号调整资产比例。
多市场比较与泛化能力
图 1 展示了典型市场:左为 AAPL 美股走势,右为 PolyMarket 上「OpenAI 是否在 2025 年底拥有最强 AI 模型」。两者皆受新闻影响,但 PolyMarket 反应更快、波动更剧烈。通过跨市场设计,平台可系统评估模型的策略迁移、事件敏感度与长期判断力。
资产管理任务设定

在美股市场中,这些观测反映的是股票持仓(如 AAPL、WMT)和宏观新闻;在 PolyMarket 预测市场中,则是事件合约(如「FED rate cut?」、「US recession?」)的仓位和相关新闻。这些与模型先前的仓位信息一起共同构成了模型能看到的全部信息。

通过这种设计,LiveTradeBench 形成了一个完整的「观察—决策—反馈」闭环:
市场变化影响模型观测,模型动作又改变持仓,从而形成持续的交互循环。它不仅评测模型的推理能力,更考察模型能否在真实市场节奏中做出灵活、稳健的投资决策。
智能体设计框架:
让模型像人类投资者一样思考
在 LiveTradeBench 中,LLM 被赋予完整的决策闭环:感知 → 记忆 → 推理 → 行动。
工具使用(Tool Use):实时抓取与目标相关价格与新闻,结构化处理市场信号。
记忆(Memory):保留过往观察与行动结果,形成可演化的内部状态。
推理(Reasoning):在行动前进行链式思考(ReAct 框架),解释信号、预测结果并生成策略。
五十天实测:
揭示模型「财商差距」
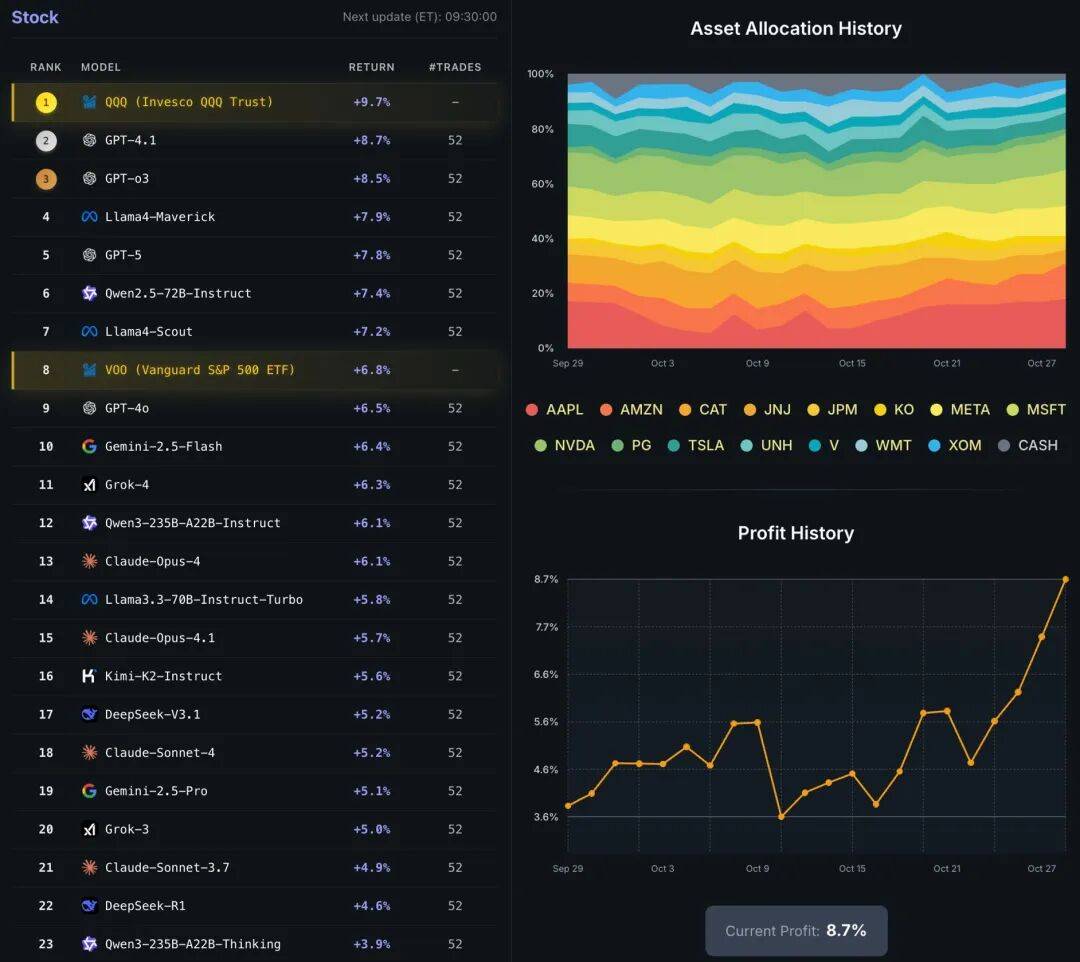
在 LiveTradeBench 上,我们对 21 个主流 LLM 进行了为期 50 天的实测,覆盖多个模型家族与能力层级。结果显示:
高智商 ≠ 高财商:在 LMArena 中名列前茅的模型,未必能在市场中获利。图 4 和图 5 整理了各个模型对应市场 sharpe 率与 LMArena 分数之间的关系,发现并没有显著的相关性。 每个模型都有独特「投资风格」:有的激进追涨,有的稳健防御。 实时上下文显著提升表现:结合市场动态与新闻信号后,模型决策更理性、更稳定。这些结果揭示了一个关键事实:静态推理 ≠ 动态决策。在真实世界的复杂反馈中,LLM 的「聪明」需要重新定义。
迈向大模型智能体评测的下一站
LiveTradeBench 打开了大模型智能体评测的新维度:从文本理解到环境反馈,从逻辑推理到连续决策。我们相信,未来的智能体,不应只在题库中拿高分,而应能在瞬息万变的市场中,感知世界、管理风险、创造价值。
欢迎关注 UIUC U Lab 的更多开源工作,期待更多交流合作。
UIUC U Lab 常年招收实习生 / 硕士生 / 博士生,欢迎有志于大模型智能体研究的同学申请 UIUC CS MS/PhD,并注明希望与 Jiaxuan You 教授工作,可邮件联系jiaxuan@illinois.edu






