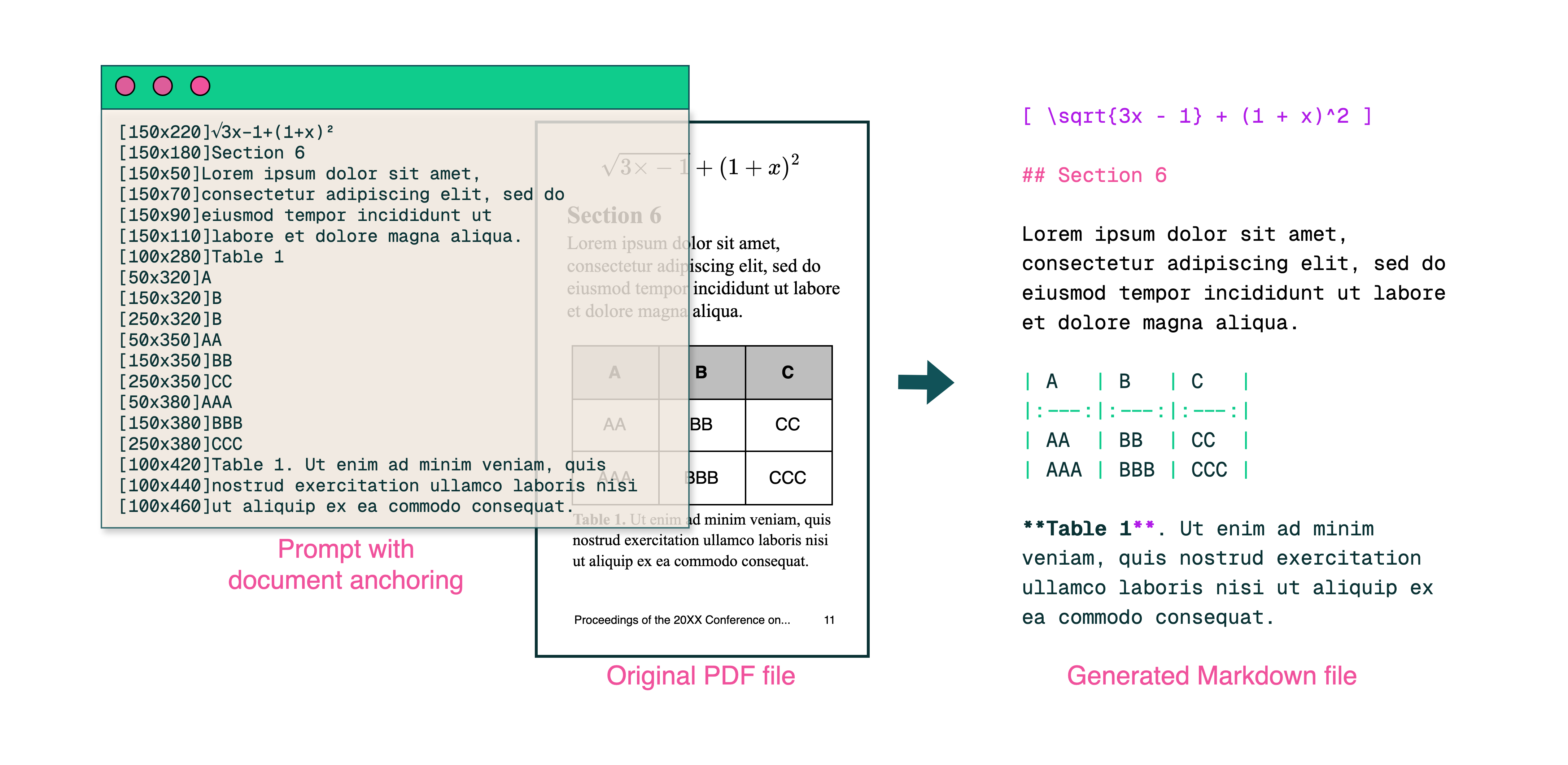
olmOCR ,一款开源的高性能 OCR 模型,专门用于将 PDF 和文档图像转换为清晰、结构化的纯文本。模型足够小,可以在本地运行。
github.com/allenai/olmocr
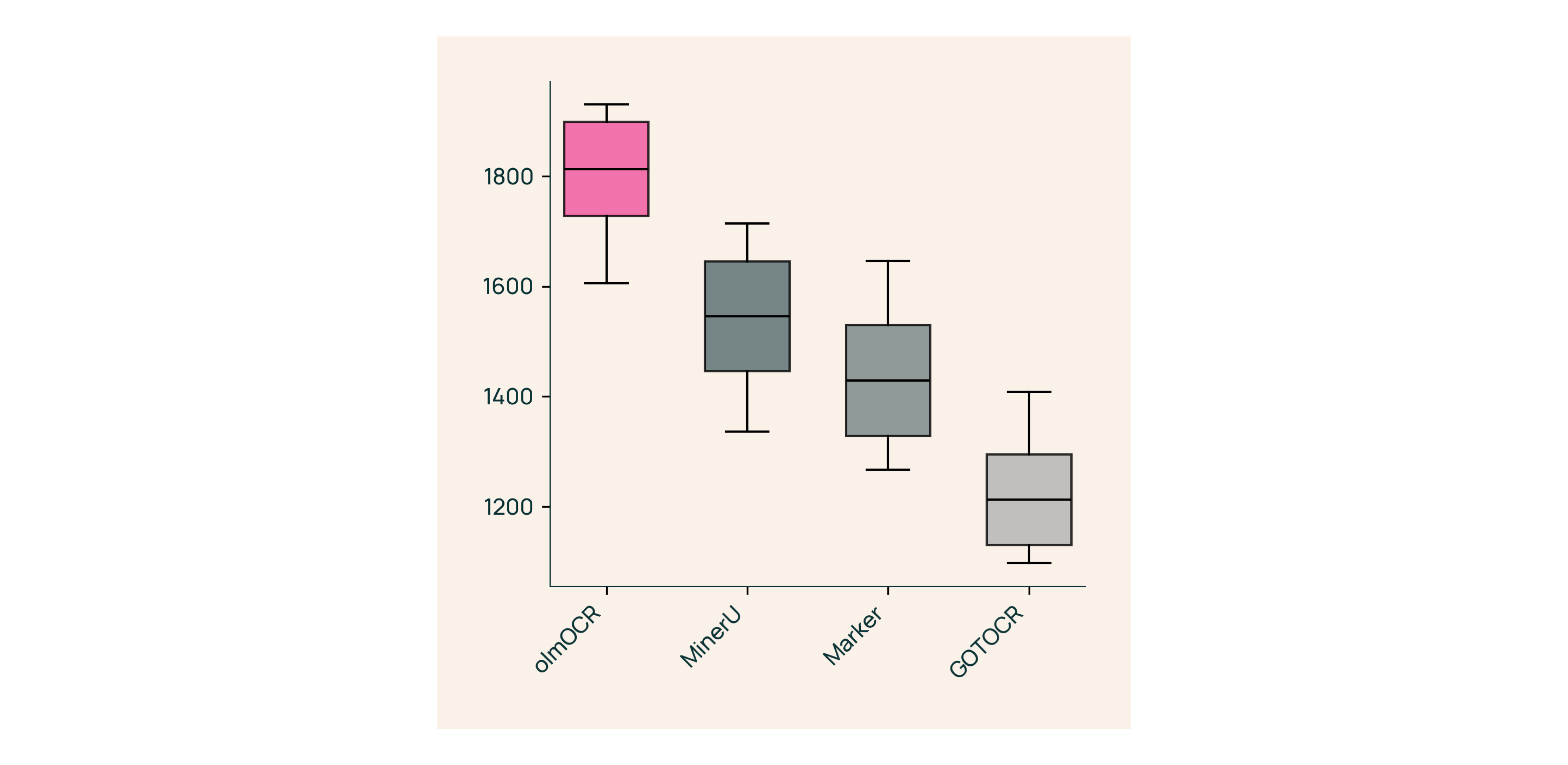
基于 Qwen2-VL-7B-Instruct 构建。它通过在多样化数据集上微调,并结合高效的推理引擎,实现了低成本、高质量的文本提取。olmOCR 的优势在于其性能卓越,能够处理复杂布局的文档;成本低,处理百万 PDF 页面仅需约 190 美元;输出为 Markdown 格式,便于解析;并且完全开源,支持大规模 GPU 扩展。