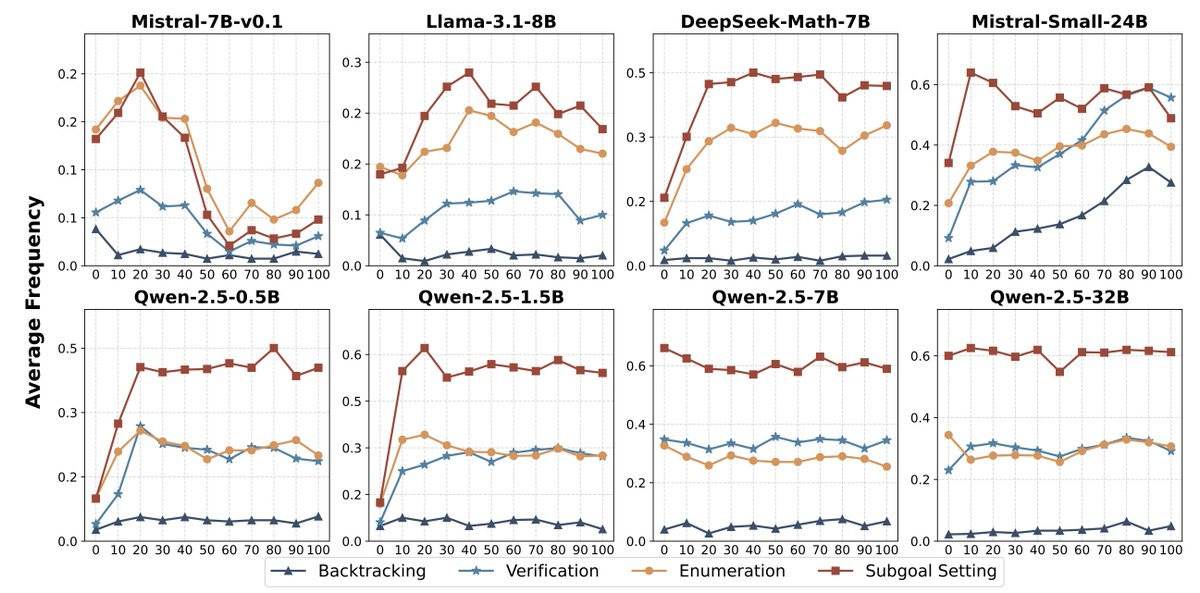
Junxian He 分享了关于零强化学习(RL)训练的最新进展,介绍了 SimpleRL-Zoo 项目。项目中涉及了零 RL 训练中的一些关键发现,包括模型的“顿悟时刻”、格式奖励的影响以及不同模型的表现差异。
论文:arxiv.org/pdf/2503.18892
🌟零强化学习在多种基础模型上显著提升了推理准确性和响应长度,但不同模型的训练动态存在差异。
🌟研究发现,格式化奖励(如强制答案格式)会限制模型的探索能力,尤其是对于初始指令跟随能力较弱的模型。
🌟训练数据的难度必须与基础模型的探索能力相匹配,否则零强化学习可能失败。
🌟传统的监督微调(SFT)作为强化学习的预训练阶段可能会限制模型的探索能力,从而抑制高级推理能力的出现。
ai创造营