无需外部奖励让模型学会推理让模型靠信心掌握推理能力
无需提供“标准答案”,就能让大模型学会复杂推理?
传统的大模型强化学习,例如RLHF和RLVR,往往需要大量的外部奖励信号或标注数据来指导训练。
这些方法容易引入偏差,而且对特定领域验证器的依赖,限制了它们在更广泛场景中的应用。
更重要的是,这些依赖结果正确性的方法往往忽略了推理过程的质量,导致在不同领域间的泛化能力不足。
来自加州大学伯克利分校的研究团队提出一种基于内部反馈的强化学习框架(RLIF),让模型依赖内在的“信心”,学会复杂推理。【图1】
具体而言,他们的实现路径可以分为两个部分:
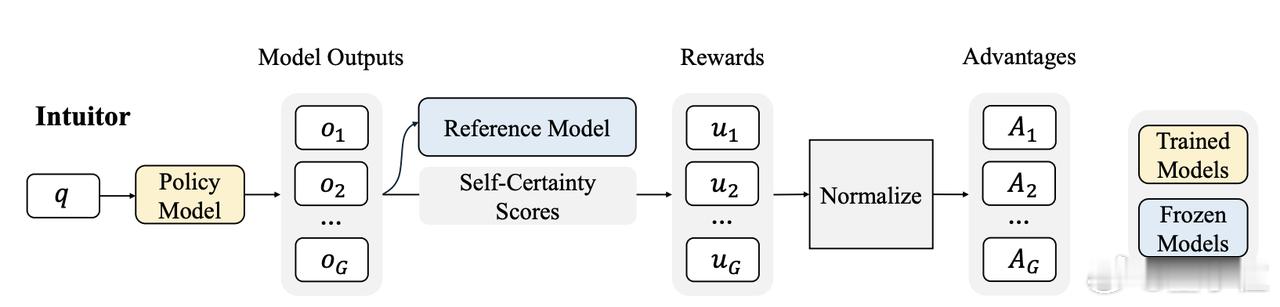
1. INTUITOR方法:利用模型自身的置信度作为唯一的内在奖励信号,通过不断优化这种置信度来提升模型的推理能力。这种方法不仅能提高模型在特定任务上的表现,还能显著增强模型的泛化能力。【图3】
2. 基于GRPO的实现:研究团队通过替换群组相对策略优化(GRPO)中的外部奖励机制,实现了完全无监督学习。这意味着模型不再需要依赖外部的判断或标准答案,而是依靠自身的内在评估来进行学习和提升。
RLIF框架的提出,带来了多重优势。它不仅减少了对监督基础设施的依赖,还提供了一种与任务无关的奖励信号,使得模型能够在外部验证不可用的领域中进行学习。
通过在数学推理、代码生成和指令遵循等任务上的实验,研究团队验证了INTUITOR方法的有效性。
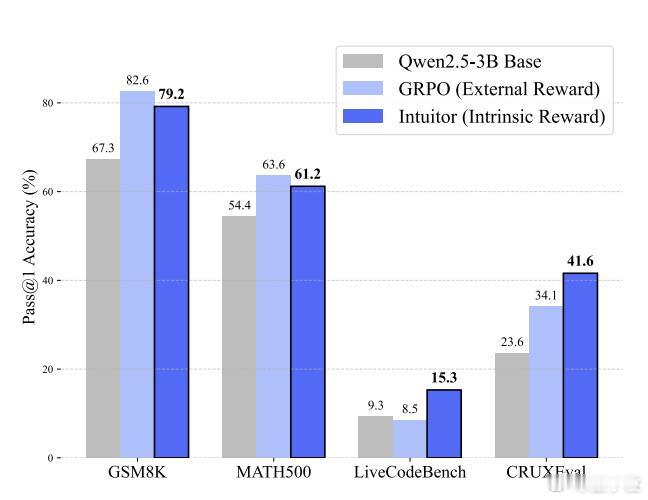
实验结果表明,INTUITOR在数学推理任务上与GRPO表现相当,同时在代码生成等跨领域任务上展现出更好的泛化能力。【图4】
模型能够完全依赖内在反馈学会结构化推理,包括提前规划、分解问题,甚至遵循指令。
这项研究证实,模型内在信号可以驱动跨领域的高效学习,为缺乏可验证奖励的自主AI系统提供了一种可扩展的RLVR替代方案。