[CL]《mmBERT: A Modern Multilingual Encoder with Annealed Language Learning》M Marone, O Weller, W Fleshman, E Yang... [Johns Hopkins University] (2025)
mmBERT:首个涵盖1833种语言的现代多语种编码器,预训练规模达3万亿tokens,采用创新的自适应调度策略,实现低资源语言的高效学习与性能突破。
• 采用ModernBERT架构,22层Transformer,基础版参数量约3.07亿,支持最长8192 tokens上下文,远超传统512限制。
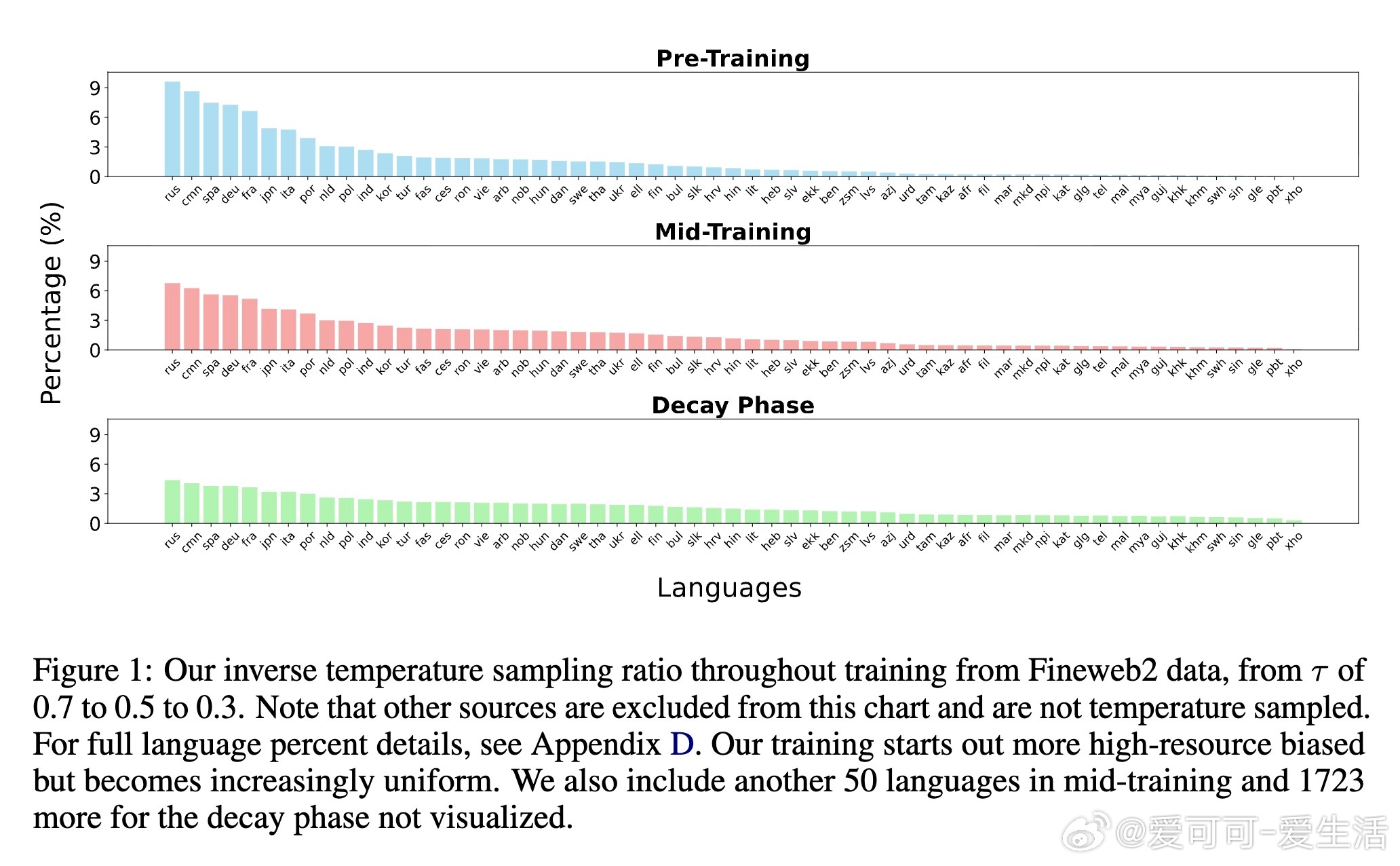
• 创新训练流程包括逆向掩码率调度和逐步扩展语言采样温度,实现从高资源语言到低资源语言的渐进式学习。
• 训练分三阶段:基础预训练(60语言,2.3T tokens,30%掩码率)、上下文扩展中训(110语言,600B tokens,15%掩码率)、衰减阶段(1833语言,100B tokens,5%掩码率),有效强化低资源语言表现。
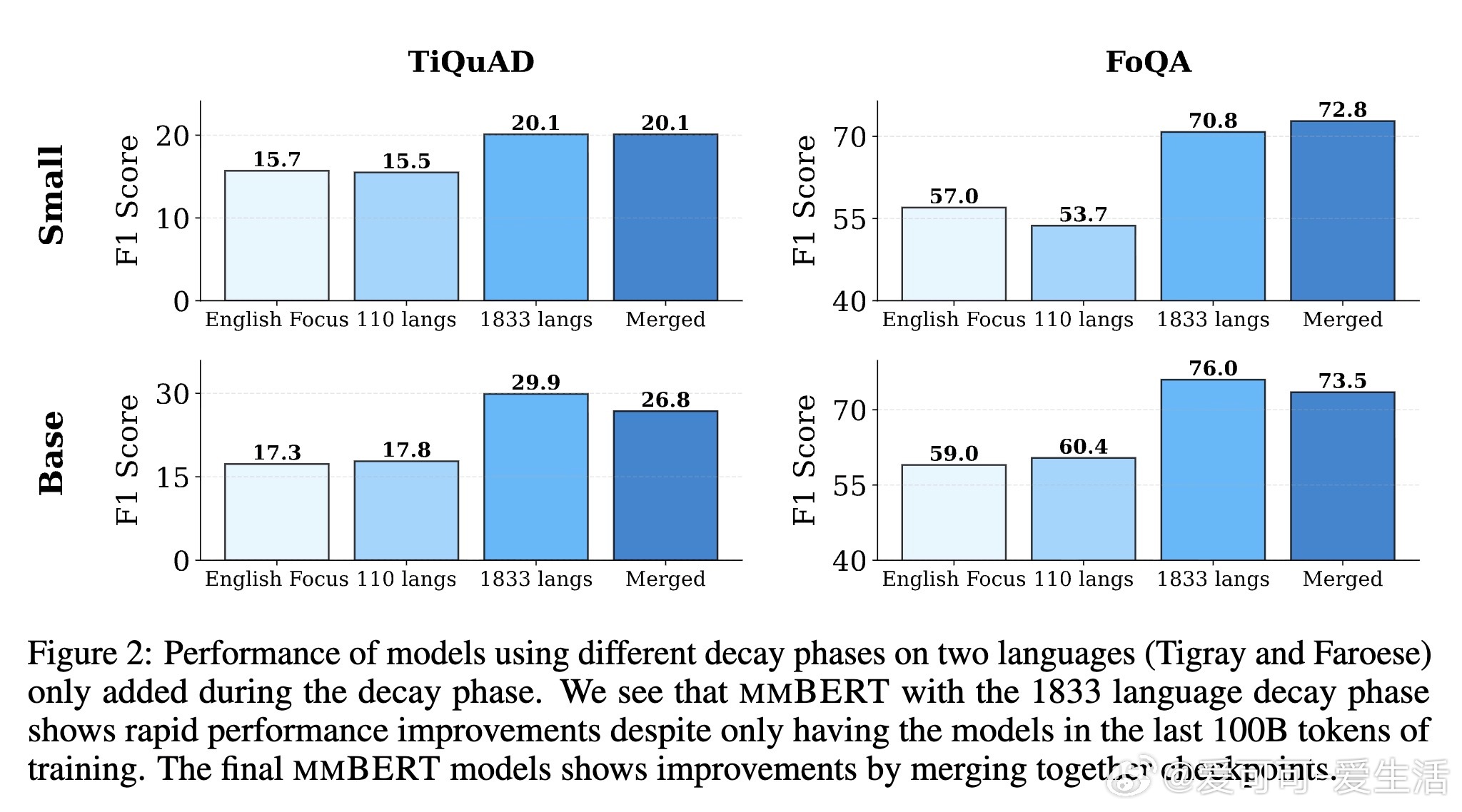
• 低资源语言数据仅在衰减阶段引入,但性能翻倍提升,超越OpenAI o3和Google Gemini 2.5 Pro等大型模型。
• 在GLUE、XTREME、MTEB等多语种NLU和检索基准上,mmBERT均显著优于XLM-R、mGTE及EuroBERT,且小型号模型性能接近甚至超过同尺寸对手。
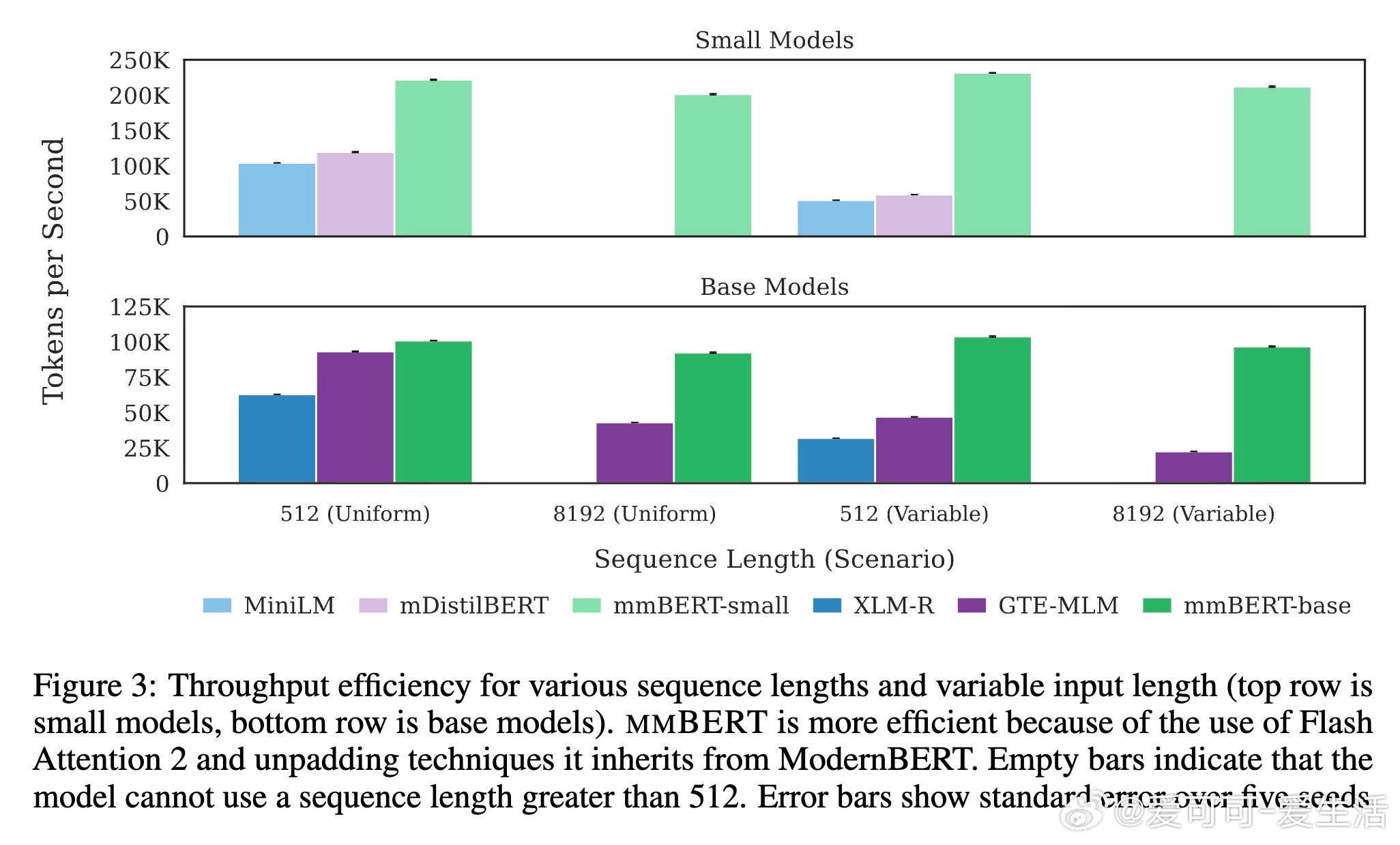
• 采用Flash Attention 2和unpadded技术,大幅提升推理速度,基版模型多场景下速度超越同类模型2-4倍。
• 全开源,包含模型、数据及训练代码,促进多语种NLP研究普及。
心得:
1. 延迟引入低资源语言并采用渐进式温度采样,有效避免数据稀缺带来的负面影响,实现快速且高质量的多语种学习。
2. 逆向掩码率调度打破传统固定掩码策略,提升模型对不同训练阶段的适应性,尤其加强后期微调精度。
3. 结合高质量多样化数据(代码、学术、指令、网页)和长上下文处理,保证模型兼具广度和深度,适用性极强。
详情🔗 arxiv.org/abs/2509.06888
多语种预训练编码器模型自然语言理解低资源语言长上下文模型效率