[LG]《Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing》J Amico, G P Andrade, J Donaghy, B Fielding... [Gensyn AI Team] (2025)
SAPO(Swarm Sampling Policy Optimization)提出了一种全新去中心化、异步的强化学习后训练算法,突破了大语言模型后训练中的通信瓶颈和成本难题。
• 每个节点独立管理模型策略(policy),并以明文形式共享生成的rollouts,支持异构硬件和模型,无需同步或统一架构。
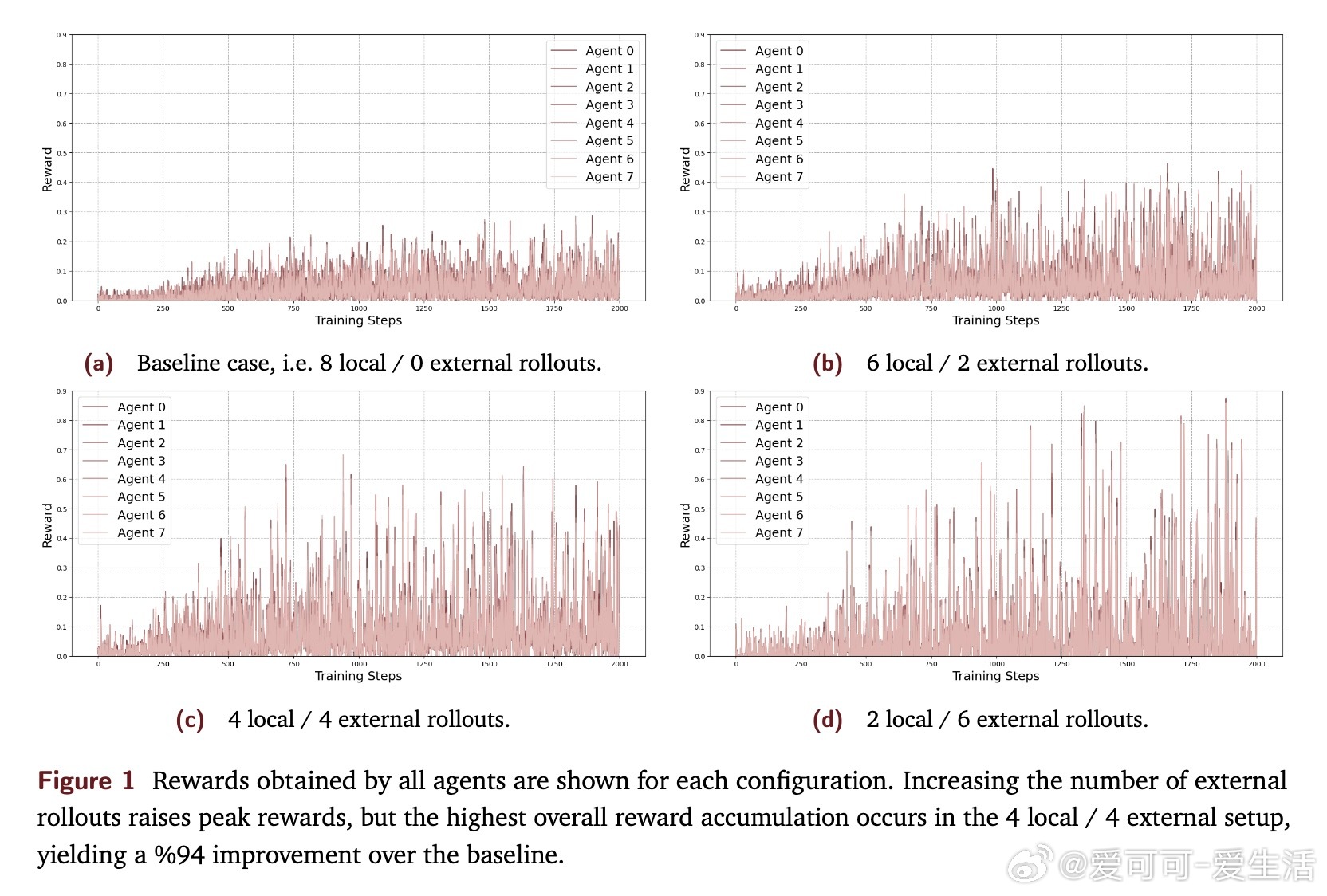
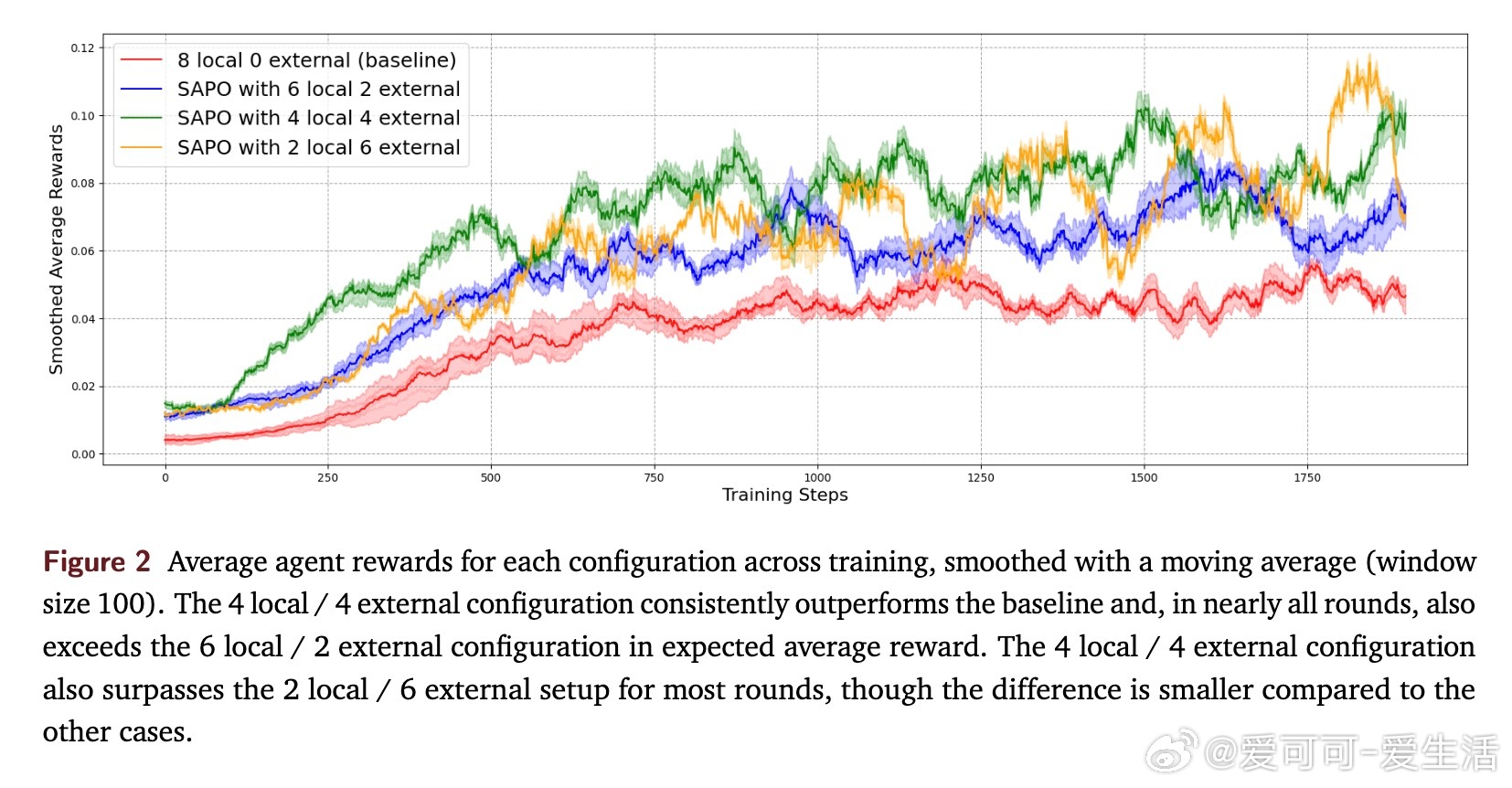
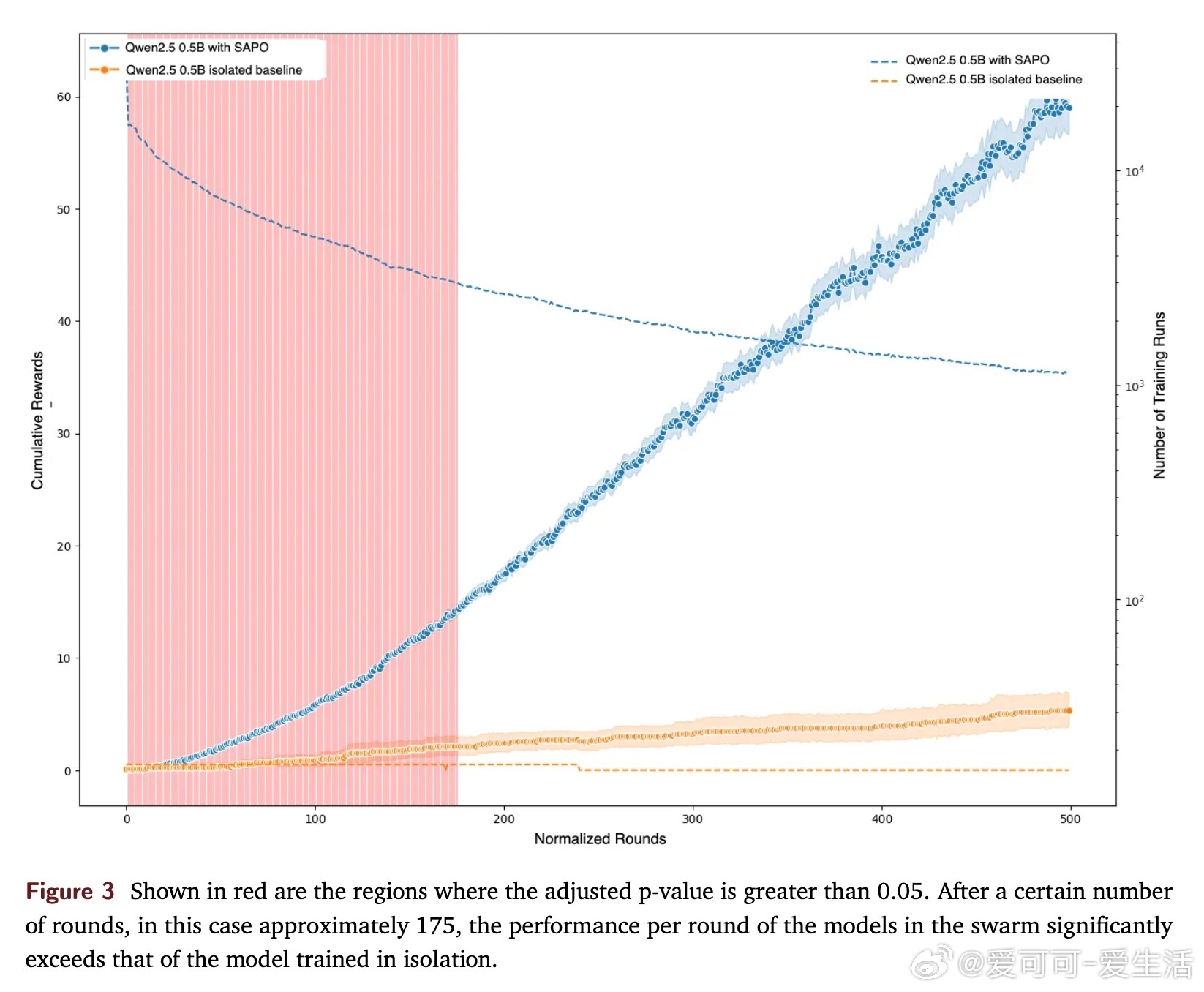
• 通过跨节点共享经验,促进“灵光一现”在网络中传播,显著提升样本效率和任务表现,实验中累计奖励提升高达94%。
• 4本地/4外部rollouts的经验分享比例最优,过度依赖外部经验会导致性能波动和遗忘,体现了合作与独立采样的微妙平衡。
• 实验基于ReasoningGYM数据集,涵盖符号、数值、抽象推理多领域,采用灵活的规则化奖励模型,验证答案正确性自动高效。
• 大规模开源demo中,数千异构节点参与,结果显示中等规模模型最能受益,表明SAPO对模型容量和多样性敏感。
• SAPO框架兼容多模态数据,未来可探索图像、文本等多模态协同训练,展现出跨领域协作的潜力。
• 该算法为强化学习后训练提供了实用且可扩展的路径,推动语言模型向更复杂推理能力迈进。
心得:
1. 去中心化经验共享避免了传统分布式RL的同步瓶颈,降低了硬件与通信门槛,使得边缘设备和异构资源也能贡献训练力量。
2. 经验共享机制实际上是一种隐式的多智能体协作,充分利用多样性产生更丰富探索,提升泛化和学习速度。
3. 合理平衡本地与外部采样比重关键,不同节点间的质量差异直接影响集体学习稳定性,提示未来需设计动态采样和信任机制。
了解更多🔗 arxiv.org/abs/2509.08721
强化学习语言模型多智能体系统分布式训练机器学习人工智能