近年来,大模型在数学推理、代码生成等任务上的突破,背后一个关键技术是 RLVR(Reinforcement Learning with Verifiable Rewards)。
简单来说,RLVR 不是让模型「听人打分」,而是让模型自己尝试多种解法,然后用可验证的规则(如答案是否正确)来反向改进自己。这使得模型能够通过反复试错不断变强,被广泛应用于当前最先进的推理模型中。
在实际训练中,为了让学习过程更稳定、避免引入额外的价值网络,许多 RLVR 方法(如 GRPO)都会对同一个问题生成一组回答,并在组内进行相对比较。模型不是直接看「这个回答好不好」,而是看「它在这一组回答中相对好不好」,这就是所谓的组内优势估计(group-relative advantage),也是目前几乎所有 group-based 强化学习方法的核心设计。优势估计并不仅仅是一个「评估指标」,而是直接决定策略梯度更新方向的核心信号。
然而,一个长期被忽视的关键问题在于:组内优势估计并不像人们通常直觉认为的那样是「近似无偏」的。
相反,北航、北大、UCB、美团最新的工作揭示了,这种组内优势估计在统计意义上存在明确且系统性的方向性偏差:困难题的优势会被持续低估,而简单题的优势则被不断高估。
 论文地址:https://arxiv.org/pdf/2601.08521
论文地址:https://arxiv.org/pdf/2601.08521 这一偏差带来的后果往往十分隐蔽,却极具破坏性。训练过程中,曲线表面上看似「稳定收敛」,但模型实际上正在逐渐回避困难问题、转而偏好简单样本。随着训练的推进,探索与利用之间的平衡被悄然打破,模型的泛化能力与长期训练稳定性也随之下降。
更关键的是,这并非一个可以通过简单调整超参数来缓解的问题,而是组内优势估计这一设计在统计结构层面本身就存在的内在缺陷。
定义
接下来,我们先引入若干必要的定义,以便于清晰表述后续的核心发现。我们首先给出最常用的组内相对优势估计的数学定义。
组内相对优势估计(Group-relative Advantage) :

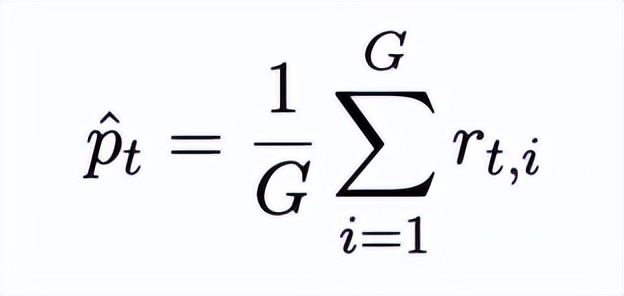
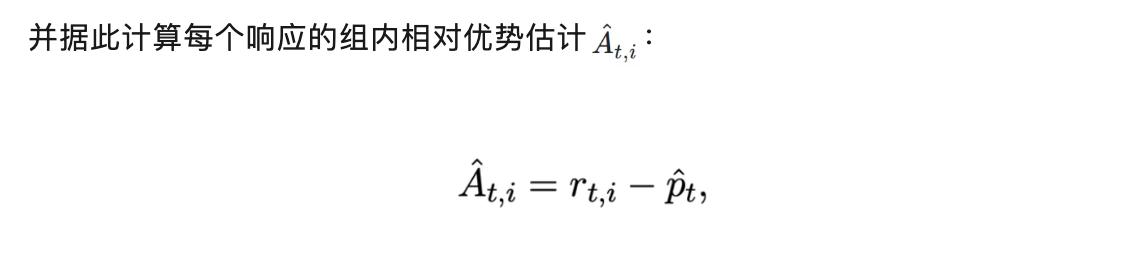
为便于阐述理论结论,下文中我们忽略标准化项。为了分析组内优势估计的统计性质,我们需要引入策略在给定提示下的真实期望表现和优势,并将其作为后续讨论的参照基准。
期望奖励:

期望优势:

为了刻画不同提示在训练中所处的难易程度,并分析偏差在不同难度区域的行为差异,我们引入如下基于期望奖励的题目难度定义。
题目难度:

最后,在基于组的策略优化方法中,并非所有采样组都会对参数更新产生有效贡献。为聚焦于真正驱动学习的情形,我们需要显式排除那些导致梯度消失的退化情况。
非退化梯度事件:
R 表示奖励总和:
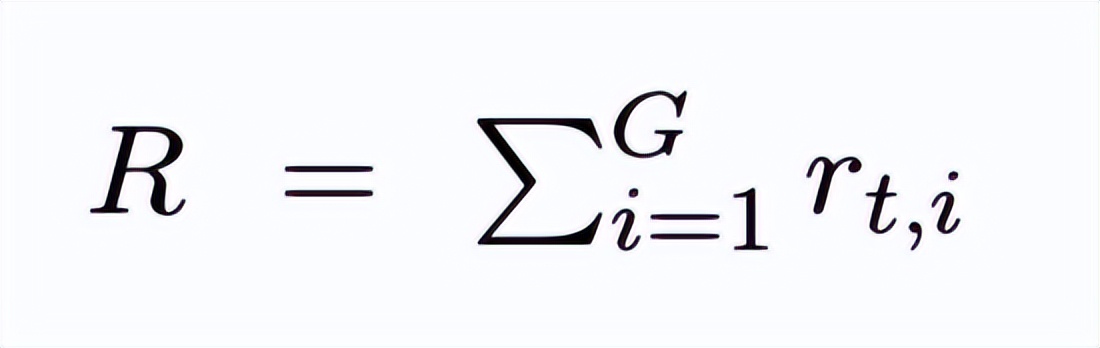

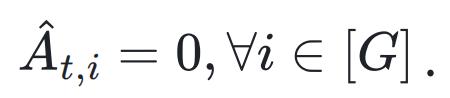
从而导致梯度消失,参数不发生更新。实践中,这类退化组不提供有效学习信号,通常被 GRPO 及其变体显式或隐式地忽略。因此,我们将分析聚焦于实际驱动学习的有效更新区间,即至少存在一个非零优势的情形。形式化地,定义非退化事件:
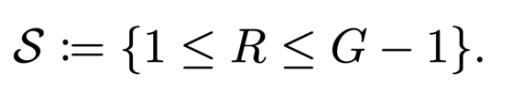
对 S 进行条件化并不会改变优化目标或训练轨迹,而仅刻画那些真正参与参数更新的样本子集,使我们能够精确分析组相对优势估计中的系统性偏差。
核心发现
重要发现 1:


这一结论表明,组相对优势的偏差并非由有限采样噪声引起,而是源自其相对优势估计机制本身,且与提示难度密切相关。
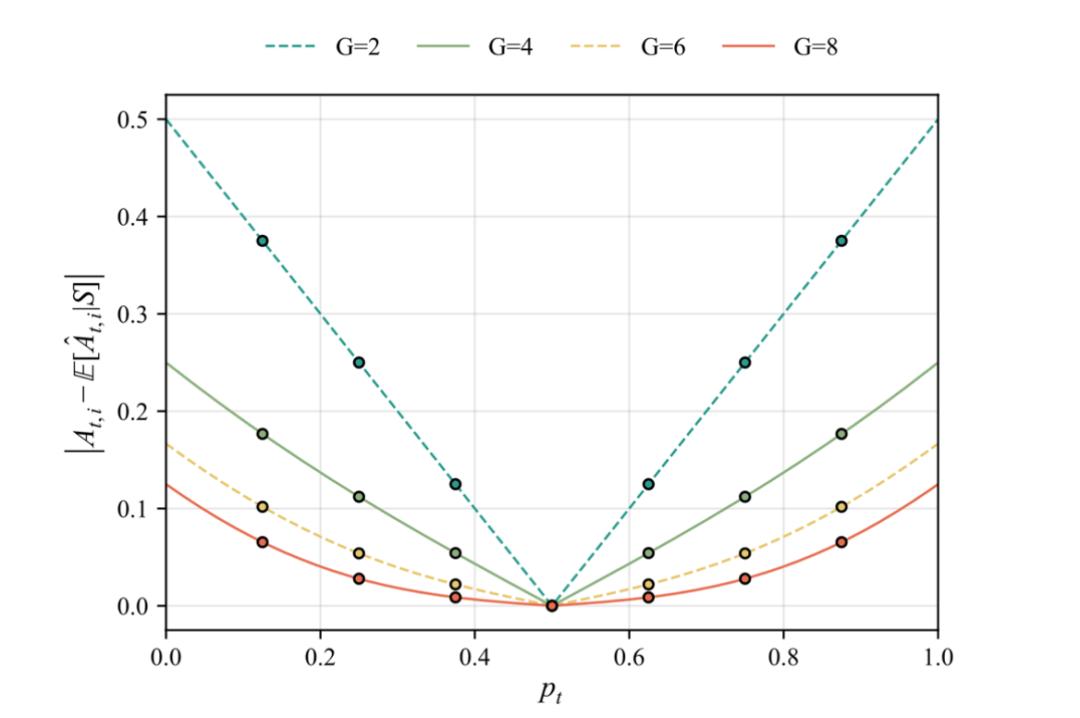

在相同的提示难度下,G 越小,优势估计偏差越大;随着 G 的增加,偏差虽有所缓解,但在有限采样范围内仍然不可忽略。
举例 1:

举例 2:
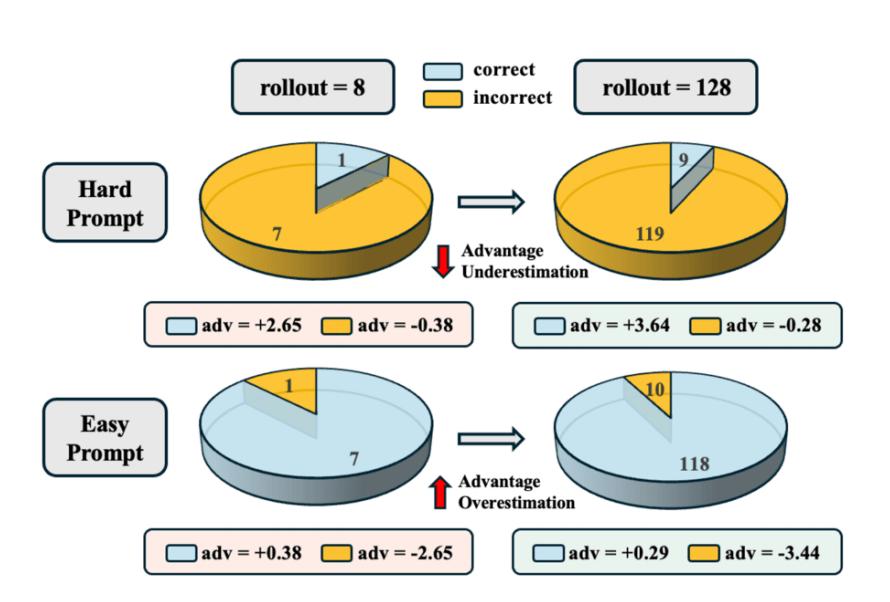
该图展示了在 MATH 数据集上,对于同一道困难题目,组相对优势估计在不同回答采样数量下的表现差异。当采用 8 次采样时,对正确回答所计算得到的优势为 A=2.65;而当采样数量提升至 128 次时,所估计的优势增大至 A=3.64,更接近其真实优势值。
重要发现 2:

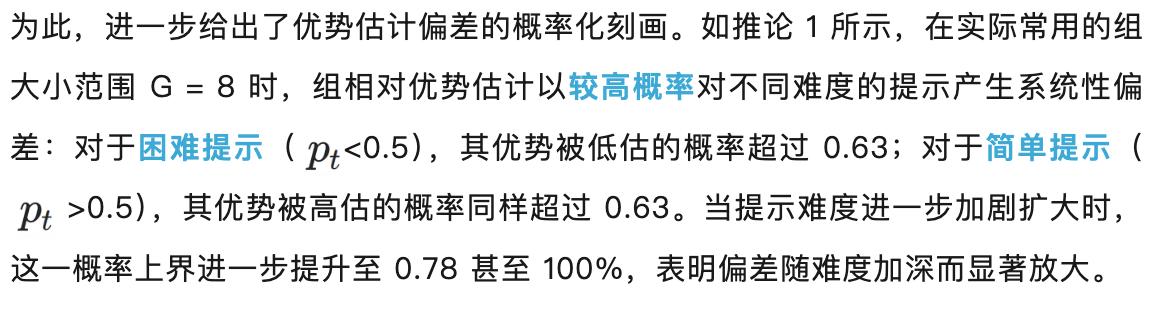
论文也提供具体偏差量估计:

总结

具体而言,该估计方法会对困难提示系统性地低估真实优势,而对简单提示系统性地高估真实优势。进一步地,对于极其困难的提示,优势估计必然被低估;而对于极其简单的提示,则必然被高估。
尽管上述分析主要基于 0–1 二值奖励的设定,该假设覆盖了大量 RLVR 场景,尤其是依赖硬判别 verifier 的推理任务,但真实应用中的奖励信号往往更加一般。
为此,论文在附录 D.5 中将分析推广至连续且有界的奖励分布。
结果表明,组相对优势估计中的核心偏差现象并非 Bernoulli 奖励假设的偶然产物,而是在更广泛的有界奖励模型中同样普遍存在。
这个发现告诉我们什么
该发现对 RLVR 训练具有直接而深远的影响。
具体而言,组相对优势估计的系统性偏差会导致不同难度提示在学习过程中受到不平衡的梯度信号:对于困难提示,其真实优势被低估,从而产生较小的梯度更新,导致学习进展缓慢;而对于简单提示,其优势被高估,模型则容易对其过度强化。最终,这种不对称的优势估计会抑制有效探索,使训练过程偏向于反复强化简单样本,而忽视真正具有挑战性的提示。
基于上述分析,我们认为优势估计应当根据提示难度进行自适应调整:对于困难提示,应适当放大其估计优势以鼓励探索;而对于简单提示,则应抑制其优势以防止过度利用。
为在实践中判定提示难度,论文提出算法 HA-DW,引入短期历史平均奖励作为动态锚点,将新提示与该锚点进行对比,从而判断其相对难度,并据此对优势估计进行自适应重加权。
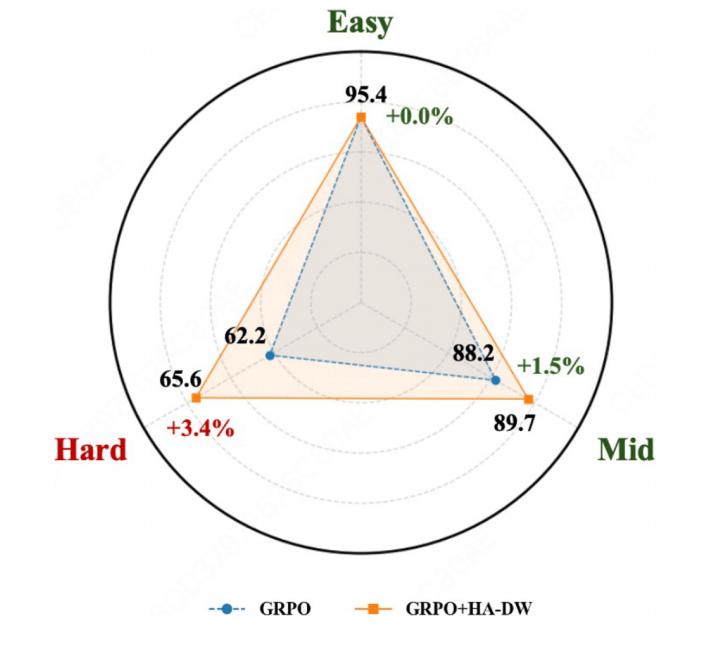
该图展示了在对组相对优势估计进行校正之后,不同难度提示上的性能变化。可以观察到,引入优势校正机制后(GRPO+HA-DW),模型在困难提示(Hard)上的性能提升最为显著,相比原始 GRPO 提升了 3.4%。
GRPO/Group-based PO 的问题不只是 variance,而是 bias。这项工作也释放了一个很强的信号:LLM 强化学习正在从「工程上能跑出效果就行」,回到「估计是不是准确」的根本问题和可解释性。以后 RLVR 里,bias analysis /estimator correctness 很可能会成为标配。