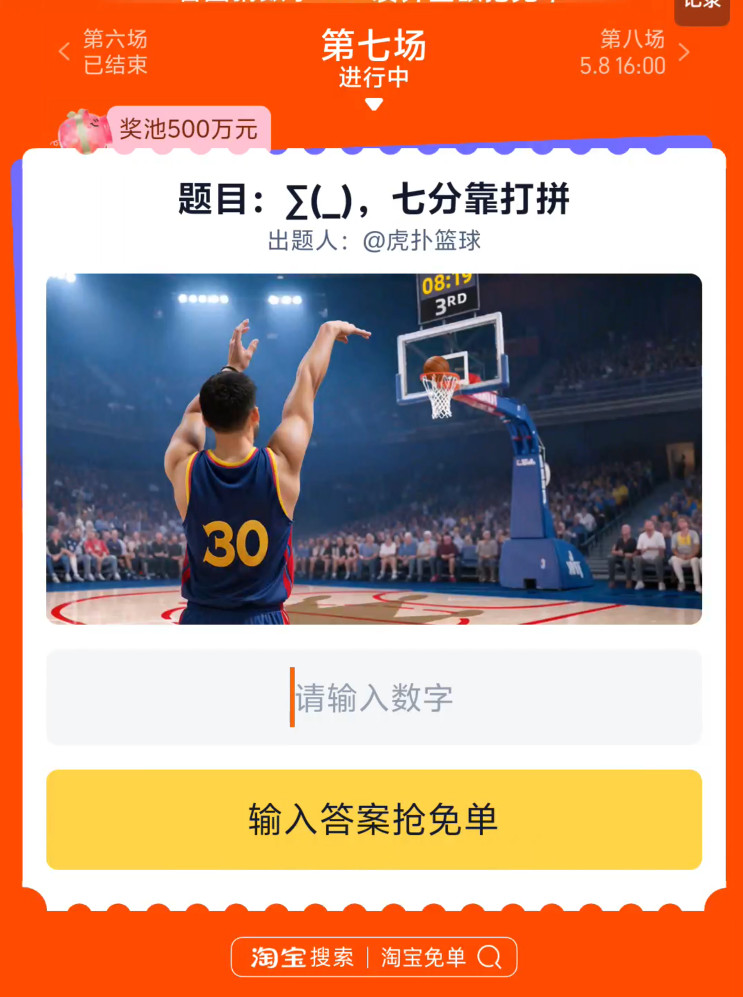
昨晚李想的AI talk是目前我听过最深入浅出解释VLA的一场谈话。
在这个层面上,甚至也能看到李想的用户思维。这个传播并不只针对于行业内,而是一些对辅助驾驶感兴趣的用户、对理想有购买意愿的用户、愿意了解辅助驾驶发展的用户也愿意听且能听懂的一场对谈。
这,很重要。
无论是地平线还是理想,都告诉我们,技术强和能把技术传播出去同等重要。
VLA这个概念,车和机器人都在用。
但李想认为VLA一定会最先实现在汽车身上,背后朴素的道理是,一辆车最多有三个自由度,而机器人有四十多个自由度,太过于复杂。且汽车显然更容易收集数据。
那么从2020年到现在,辅助驾驶其实发生过三个进化:规则算法(昆虫动物智能)——端到端+VLM(哺乳动物智能)——VLA司机大模型(人类智能)。
如果按照朴素的科学道理,只有昆虫是无法进化成人类的,但哺乳动物可以。这也是为什么张晓珺问李想,能不能直接做到VLA,李想非常坚决否定的原因——没有端到端这些基础的能力,就不可能拥有理解世界的能力。
但为什么不停留在端到端呢?
李想举了个例子,在通行能力上,如果遇到一个复杂的修路路口,规则算法可能会撞上去,端到端可能会停下来,VLA可以轻松解决,而且不需要海量数据,只需要生成数据训练。在交流能力上,VLA可以具备AI Agent的能力,和用户用自然语言直接对话,如果用户想直行,那么VLA就不会走左拐的那条路。
那么VLA,到底是什么呢?
通俗来说,VLA可以拆解为预训练、后训练和强化学习。预训练像学习知识,后训练像驾校学车,强化学习就像去社会上开车,其实非常像人的学车轨迹,科一——科二、科三、科四——自己去公开道路开车。
第一个阶段:预训练,打造了一个视觉-语言基座模型,这里面需要两种数据,一种是视觉数据,另一种是视觉和语言同步对齐的数据,紧接着就要把这个32B的VL基座模型蒸馏,让它满足Thor U或者双Orin-x可以承担的帧率。
第二阶段:后训练,在基座大模型里加入动作模块,生成 4-8 秒驾驶轨迹,模型从 32 亿参数扩大到 40 亿。
第三阶段:强化训练,第一步RLHF人类反馈强化汛期,接入人类接管和偏好数据,要先让轨迹和人类习惯对齐。第二步在世界模型里进行闭环学习,引入G值(舒适度)、碰撞、交通规则三个标准来打磨、反馈,让VLA比人类看得更好。
第四阶段:形成司机Agent智能体,来个VLA就像教练开车,且拥有直接与用户对话的能力。
具体可以参考理想的短视频,用户可以直接通过车机语音,让辅助驾驶系统带自己去指定的停车区。
李想说“不要老想着摘第十个包子”,外界也有声音认为,理想就是摘第十个包子的人,行业里也不乏有声音“talk is cheap,show me your code”,但我认为coding is a skill,talk is too。