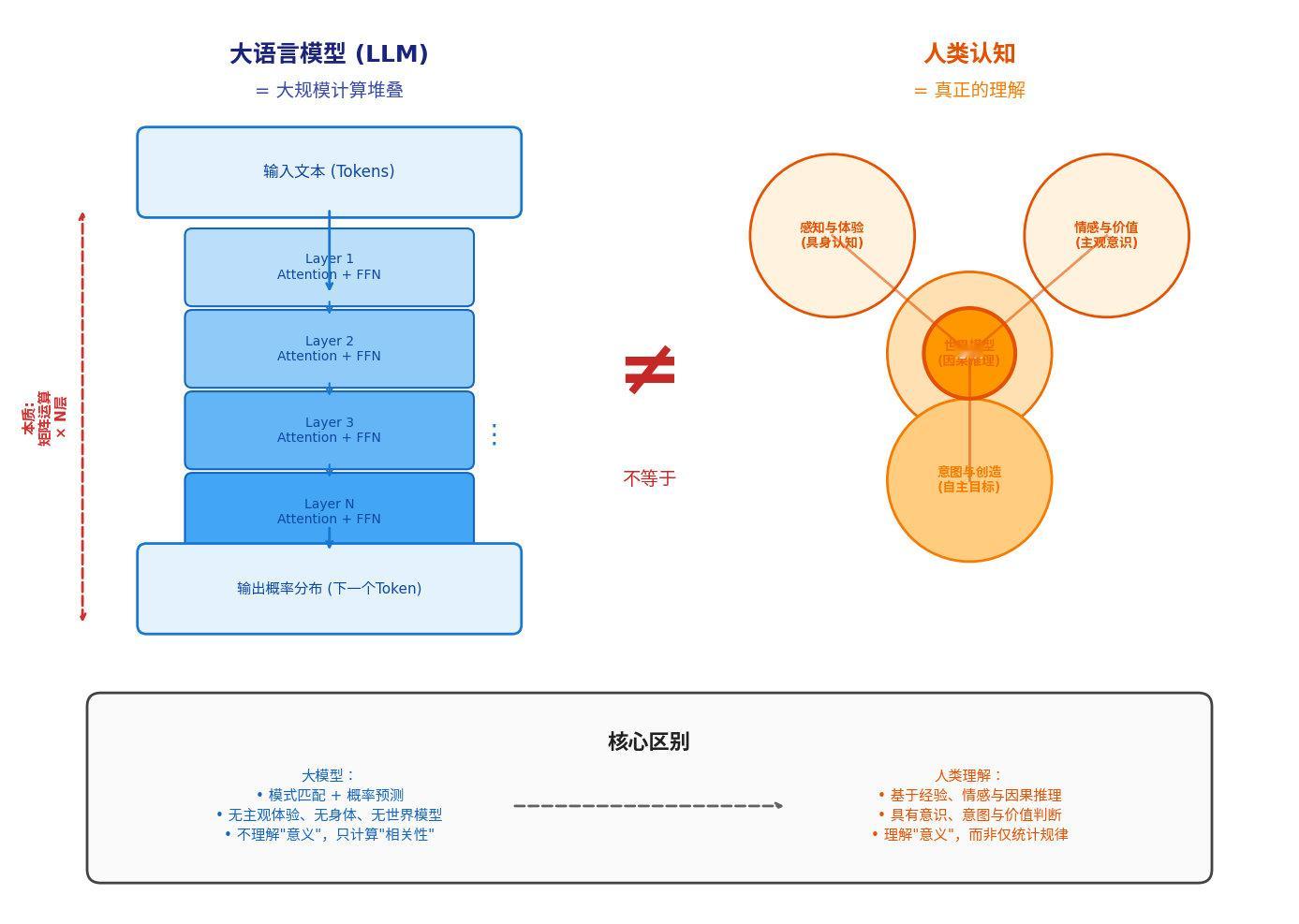
AI大模型建立了一个计算结构,能够输出“像是理解”的token。和人类的理解不一样,它是一种计算。人类智能不可计算的部分更为关键
最近和AI聊多了,觉得这东西太厉害了,连一些很高深的论文都理解得很好。感觉似乎比人类专家都厉害,更不要说能横跨无数个领域。
以前还是能看出理解问题的,幻觉很多,现在少多了。在我很熟的领域,AI偶尔有问题,我们自己犯错更多。
聊多了以后,慢慢有结论了,觉得人类还是有优势。它理解知识的基础是一些固定的系数,这些系数在推理时不变。训练的时候,先用10多万亿token的固定语料,预训练出知识结构。然后在“后训练”,让完成一些任务,不对就改正系数;让人类来给它的聊天输出打分,输出不对就打低分,修改系数追求高分,先训练个打分器,可以海量打分。然后还有思维链,让加长思考时间,做难的数学题,根据输出结果改系数。
训练结束后,搞出来的固定的系数,就能理解领域知识了,对人类的问题,能给出高质量的回答。测试集的问题都回答的不错,这样就是能够输出理解token,而且一般是正确的。根据答案,感觉里面的固定系数,就是正确的理解。
我的顿悟是,这并不是人类的理解,而是一个“计算”的结果。可以类比的是,计算器能够全部计算正确,即使如此,也不能说计算器“理解”了计算。计算器算得再好,都是“死”的,没有对数学计算的理解。
大模型就像计算器一样,能够对“智能问题输入”,输出正确的结果,但是不理解背后的智能。大模型输出的智能,是“可计算”的,经过人们海量语料预训练、耐心后训练,很多计算结果token序列都很像样了,就和计算器的精准结果一样。计算时间加长,能够输出的智能也增加了。
但是,仍然存在大量“不可计算”的智能问题,理论上大模型搞不定。典型的就是“写人类满意的小说”,很可能就是不可计算的问题。这些与"taste"相关的问题,很难用训练样本来定义。训练再久,大模型也写不出好小说。
为什么“写好看的小说”,不是可计算的问题?这里涉及人类深层次的理解,要让人看出“深意”“新意”“鲜活表达”,这些本质上不是简单的理解,而是人类真正灵魂理解,需要“意会”“领悟”“体会”,很难用训练案例来捕捉。可以模仿文学家的文字风格,但是核心情感很难模仿。人类会产生强烈的情感冲动,有时表达出来很好。
人类的理解,有时显得很平凡。但是由于与物理世界有真实链接,会有难以用语言形容的理解。例如“酸甜苦辣”就是文字意义上不可理解的。大量基于人类物理信号的理解,是非文字的,例如对空间的理解。
可计算的智能,是token世界的。token世界覆盖了人类的一些智能,但是没有全部覆盖。因此,大模型在一些token可计算的智能任务上超过了人类。但是,这些智能是有严重缺陷的,本质上不完整。例如大模型看似完全理解了某些学科的知识,但是人类专家仔细盘问,就能看出它是在计算,并不是真正的理解,说多了就露馅了。而且很容易被误导,例如告诉它一个假知识,它可能立刻就胡言乱语了。