中国大模型用6倍成本优势把老美逼急了,马斯克和唐杰直接下场争论
有个好玩的细节:上周智谱发布GLM-5.2,全球AI圈炸了锅,连马斯克都坐不住了。
起因很简单,有人在外网问:中国大模型啥时候能追上美国最前沿的Fable级别?
独立研究员Teortaxes算了笔账,说7个月左右。马斯克一听赶紧接话:我看得明年Q1,测试跑分追容易,真要“好用”还得等。
最精彩的来了。智谱创始人唐杰只回了一句:不用那么久。
这话不多,信息量不小。你细品,头部玩家敢这么硬气,手里肯定有底牌。
底气从哪来?我看了下数据,两个点很有意思:
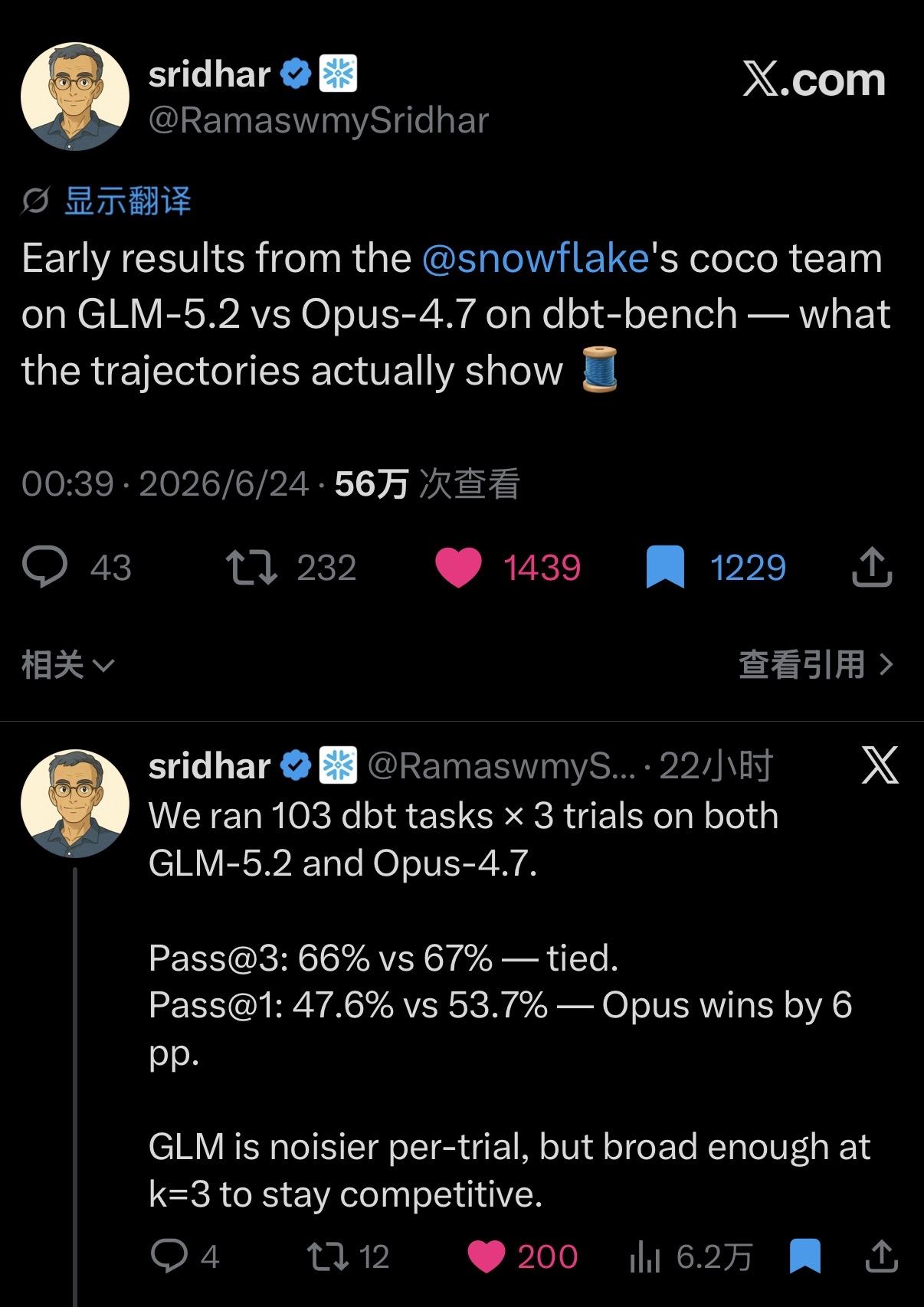
一是GLM-5.2在综合榜单拿下51分,跟Claude Opus 4.8掰手腕,直接登顶全球开源模型第一。北大研究员张有鱼评价得很直白:在多数实际开发场景里,这玩意儿已经能当海外顶尖模型的替代品。
二是成本,这个更狠。有人做了对比,同样做一个登陆页面,GLM-5.2花0.06美元,Opus 4.8花0.49美元。便宜6倍,效果几乎看不出区别。
我刚开始也觉得夸张,但查了一圈发现真不是吹的。OpenRouter平台数据摆在那,5月中旬开始,DeepSeek已经稳坐最常用AI模型厂商第一名。初创公司Vercel那边,4月份DeepSeek份额才1%,5月直接飙到17%。
回过头想马斯克那句话,他说“明年Q1追上就相当令人刮目相看”,但按现在这个成本结构,哪怕还有10%的智能差距,90%的成本优势已经让全球企业开始用脚投票了。
这可能是今年AI行业最被低估的变局:当性价比天平倾斜,烧了几万亿美元的资本配置逻辑,会不会本身就是个错配?