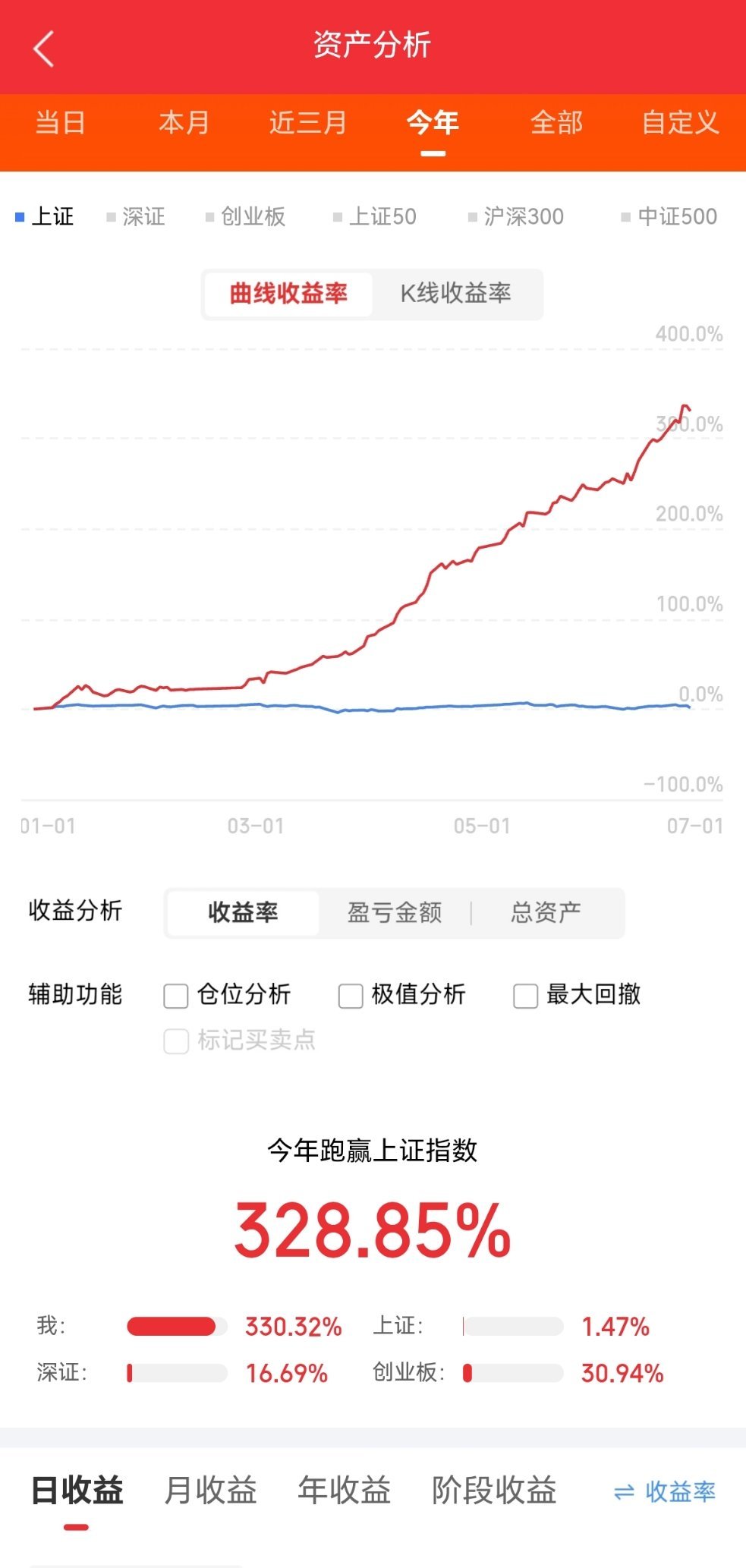
这项由KAIKAKU机构完成的研究,于2026年6月25日以预印本形式发布,论文编号为arXiv:2606.27288v1,感兴趣的读者可通过该编号查阅完整论文。
当越来越多的企业开始把多个AI模型拼在一起用,期待"三个臭皮匠顶个诸葛亮"的时候,这篇研究冷静地问了一个几乎没人认真问过的问题:这种组合到底什么时候真的有用?
---
一、故事从一个常识开始
在很多人的直觉里,多个AI模型一起工作,总比一个强。就像让三位医生会诊,总好过只听一个医生的意见。过去几年,AI领域确实流行起一种做法,叫做"模型路由"或"混合专家系统"——系统里有很多模型,根据问题类型把任务派给最擅长的那个,或者让多个模型投票,少数服从多数,或者从便宜的模型开始,不够好再升级到贵的。
这套做法听起来很合理,而且业界也有一个公认的判断标准:**两个模型之间的"错误相关性"**,也就是它们犯错的习惯有多像。如果两个模型总是在同样的题目上犯错,那组合起来也没什么用;反过来,如果它们各有各的短板,组合就有价值。这个叫做"ρ(rho)"的数字,成了行业里判断"要不要组合模型"的核心指标。
然而这篇研究发现,ρ是个根本性的误导。它告诉你的,不是你真正需要知道的东西。
---
一、真正的天花板藏在哪里
研究者引入了另一个数字,叫做**β(beta)**——所有模型同时答错同一道题的概率。
用一个直觉上很清晰的比喻来理解:假设你组建了一个由10位专家组成的顾问团来回答问题。无论这个团队的投票机制多么精妙,也无论你的"路由规则"多么聪明,有一类问题是谁也救不了的——那就是10位专家全部答错的题目。在那些题目上,不管你选哪个专家、让他们怎么投票,结果都一样:错。
这个"全员翻车率"就是β。而整个多模型组合系统能达到的最高准确率,就是**1减去β**。也就是说,如果10%的问题所有模型都答不对,那无论你的组合策略多精妙,系统准确率的天花板就是90%。
这个结论本身并不复杂,但它的含义很深刻:在你花大价钱设计路由系统、训练分发器、调优投票规则之前,你应该先把β测出来,看看这个天花板在哪。如果天花板很低,再聪明的组合都是徒劳的。
---
二、ρ为什么看不见β
问题的核心在于,ρ和β是两回事,而且ρ根本无法推算出β。
这里有一个微妙但关键的数学事实:即使两个、三个甚至十个模型,它们两两之间的错误相关性(也就是ρ)完全相同,它们"全员同时犯错"的概率(β)仍然可以差天差地。换句话说,你知道每两个模型之间的配对关系,并不代表你知道所有模型的集体行为。
用一个生活类比来理解:假设你有三位朋友,每两个人之间的脾气相合程度相同。但这并不意味着三个人聚在一起时的相处模式是可以预测的——三人关系有一种两两关系中不存在的"集体特质"。模型的错误模式也一样,群体行为有超出两两关系的结构。
研究者严格证明了这一点:对于三个或更多模型,仅凭两两之间的相关性,在原则上就无法确定β。这不是数据不够多的问题,而是信息论层面的根本局限——任何基于ρ计算出来的β预测,都是有偏差的,而且随着模型数量增加,这个偏差会越来越大。
---
三、现实数据里到底有多严重
研究团队付诸实践,花费约270美元,在涵盖21家提供商的67个前沿AI模型上做了大规模测试,其中包括GPT-5.5、Claude Opus 4.8、Gemini 3.1 Pro、Grok-4.3、DeepSeek V4、Qwen3.7-Max、Kimi K2.7等当下最强的模型。
测试用的题目分几类:开放式数学竞赛题(MATH-500和更难的MATH-Hard Level-5)、研究生级别科学问题(GPQA-Diamond)、以及执行评分的编程竞赛题。
在数学题上,结果相当令人清醒。在330道题目中,所有67个模型同时答错的比例β是5.2%。这意味着,无论你的组合策略多完美,这批模型在数学上的准确率天花板约为94.8%,最强单个模型的准确率是83.6%,而每次查询的"理论最优"也不过94.8%。真正可以争取的提升空间,其实相当有限。
更关键的是,研究者还做了一件事:用行业常用的方法,根据ρ来预测β。结果是,即便使用了正确的、经过校准的统计方法(称为"四分相关"或"四分点相关系数",这是比简单相关系数更精确的工具),预测出的β是0.021,而实际测到的β是0.052,真实值是预测值的约2.5倍(90%置信区间为1.7到3.4倍)。这个差距意味着:用ρ来评估多模型组合的价值,系统性地高估了它能带来的提升空间。
更重要的是,研究者尝试了不同的统计模型来解释这个差距,包括考虑了所有67个模型两两之间的完整相关结构(67×67的矩阵),结果仍然低估了实际β,差距维持在2.25倍左右。这说明问题不是统计模型不够复杂,而是存在一种所有模型同时失败的"共同失效原子"——某些题目,不管模型多强、多多样,都会集体答错,而这种集体失效的概率,任何基于两两关系的统计模型都无法完全捕捉。
---
四、"集体失智"随池子变大而加剧
研究者还做了一个很有说服力的实验:把67个模型随机抽取不同数量的子集,比较每种规模下"真实β与预测β的比值"。
结论是:当只有2个模型时,这个比值是1,也就是说预测是准确的。但随着模型数量增加,比值单调递增,到67个模型时,中位数达到2.5,而且几乎所有随机抽取的子集都显示出同样的趋势。
这说明,"ρ低估β"不是某几个特殊模型组合的偶然现象,而是一个系统性规律:你把越多模型放进池子,ρ所代表的"多样性"对于估计真实集体失败率就越不可靠。
直觉上的解释是:每新增一个模型,它和其他每个模型两两之间的相关性是可以测量的。但整个群体"全员同时失败"的概率,取决于一种高阶的集体结构——类似于"这道题有一种根本性的困难,让所有模型都绕不过去",而这种集体难题随着模型池扩大会更难被察觉,因为两两的相关性稀释了这个信号。
---
五、花钱前先拿到"上限证书"
研究者提出了一个实用工具,叫做"可实现性证书"。原理很简单:在你花钱训练路由器、部署多模型系统之前,先从你要处理的题目中抽取一批样本,让所有候选模型都答一遍,数出有多少题目是所有模型全部答错的,用统计学方法(Clopper-Pearson区间估计)得出β的置信区间,然后算出最大可能收益的上限。
如果这个上限比你的系统运维成本还小,那答案就很清晰了:不值得。而且这个测试几乎不需要额外花钱,因为你要做的只是用你已有的模型跑一遍样本题,不需要训练任何新系统。
研究者把这套工具做成了一个叫`beta_certificate.py`的脚本并公开发布,任何人都可以拿来用。输入的只是"全部答错的题数"和"总题数",以及单个最佳模型的准确率,输出的是任何组合策略所能超越单个最佳模型的最大理论上限。
---
六、实际路由器的表现
研究团队不只停留在理论层面,他们还真的训练了多个路由器来验证。在15个模型、多领域混合题目的实验中,每次查询的"理论最优路由"比单个最佳模型高出4.4个百分点。但当他们实际训练了一个基于文本特征的路由器之后,这个路由器只比单个最佳模型高出0.5个百分点左右,而且置信区间横跨零值,说明这点提升很可能只是统计噪声。
他们还尝试了更强的路由方案:基于梯度提升的正确性预测器、直接预测最佳模型的多分类器,甚至用GPT-5-mini作为"路由决策的AI"——给它看每道题,让它在了解所有模型特长之后选择最合适的模型。结果是这个AI路由器100%的时间都选了单个最好的模型,对整体准确率的贡献为零。
为什么路由器学不到什么?因为当最好的几个模型不一致时,这道题的"正确答案在哪个模型手里"这个信息,往往藏在答案本身里,而不是藏在问题的文字里。看题目的特征,通常无法预测哪个顶尖模型会答对、哪个会答错。
---
七、两种截然相反的困境
在更大规模的测试中,研究者发现了一个很有意思的现象:不同类型的任务,组合模型遇到的障碍完全相反。
在开放式数学题上,障碍是"天花板太低":β明显大于零,全员失败的概率不可忽视,这把整个系统的准确率上限压低了,再好的路由策略也无法突破这个上限。这类情况研究者称为"天花板约束型"。
在研究生级别的科学选择题(GPQA-Diamond)上,情况完全相反:在130道题的测试中,竟然没有出现哪怕一道所有模型全部答错的题目,β约等于零,天花板是开放的。但这不意味着组合没用——实际上理论上的最优路由比单个最好模型高出15个百分点!问题在于,这15个百分点完全是"可解决的分歧",也就是不同模型各有各对的题目,只要你能准确判断该选哪个模型,就能实现这个提升。但现实中没有一个路由器能做到这一点,因为这需要在回答前就知道答案——而这恰恰是路由器无法做到的事。这类情况研究者称为"可实现性约束型"。
这两种困境同样令人悮,但原因完全不同。ρ这个指标对两种情况都无能为力——它既无法告诉你天花板在哪,也无法告诉你那15%的提升空间到底有没有办法实现。
---
八、是格式决定了"集体失智",而非内容
研究团队做了一个精心设计的实验,专门证明集体失败不是数学或编程题的专属现象,而是"开放式回答"这种格式本身带来的。
他们把79道GPQA-Diamond科学题(这是研究生级别的物理、化学、生物混合题),先以多项选择题的形式让模型回答,再把完全相同的题目改成开放问答(去掉选项,让模型自由作答),然后用五个AI裁判组成的评审团来判断开放式回答对不对。
多项选择版本:β约等于零,所有模型全部答错的题目接近于没有,平均准确率66%,最佳模型91%。
开放问答版本:β跳到了12.7%,10道题上所有模型全部答错,平均准确率51%,最佳模型77%。
这个对比的力度在于:内容完全相同,换的只是答题格式。这说明"集体失智"的根源不是某个学科有多难,而是开放式生成本身带来的不确定性——当没有选项可以"锚定"答案范围时,模型面对的困难会发生质的变化,而且这种困难会以一种集体同步的方式爆发出来。这个发现把前面所有的数学和编程结果统一成了一个更简洁的解释:不是题目的内容,是开放式回答这件事本身,让全员失败的概率非零且不可忽视。
---
九、多样性是把双刃剑
研究者还探讨了另一个流行说法:"模型越多样,融合效果越好。"他们用15个模型中所有可能的3个模型组合(共455种)做了测试,让三个模型投票,少数服从多数。
结果是:平均来看,投票的准确率比三个模型里最好的那个还差。在难题集上平均低了10个百分点,在混合题目上低了2个百分点。"多模型投票"这件事,竟然是有害的。
原因并不神秘:如果三个模型质量差异大,那两个差的模型投票否定一个好的模型,结果是更差。这就像让三个人投票决定一道数学题的答案,其中一个是数学教授,另外两个是普通人——普通人的多数票会把教授的正确答案淹没。
但有一个关键的前提让结论反转:**如果三个模型质量相当**,那低相关性的组合确实比高相关性的组合更好。研究者用一个精心设计的实验验证了这一点:把"多个不同模型"(错误相关性低,约0.42)与"同一个最好的模型多次采样"(错误相关性高,约0.80)做对比,在质量相当的前提下,前者在从第三个成员开始就稳定超过了后者,在60次不同的随机样本划分中全部如此,而且平均提升幅度约为2.7个百分点。
这个结论很微妙:多样性有用,但前提是质量对等。在质量差异大的情况下,强行追求多样性反而是负担。
---
十、研究的边界与诚实
研究团队对自己工作的局限性相当坦诚。这项研究依赖于"可以用程序自动评分"的任务,比如数学题和编程题,而对于更开放的生成性任务,比如写作质量、解释能力,很难做到客观评分,这部分还是个未解决的问题。
在编程任务上,虽然全员失败的概率(β=7.9%)和ρ低估的现象都得到了验证,但只有5道题是全员答错的,样本相对有限,确切的倍数(3.1倍)的置信区间很宽(1.5到6.2倍),精确数值仍有不确定性。研究者在文中明确标注了这一点。
另外,路由器的训练和测试只在15个模型的较小样本上完成,而那个"67个模型"的大规模测试由于没有记录每道题的具体输入提示,无法在上面训练和测试路由器,大规模测试的结论依靠的是β证书,而非端到端的路由实验。这个局限性研究者同样直接说明了。
---
说到底,这项研究把一个大家习以为常的操作——把多个AI模型组合使用——放在了一个更严格的框架下审视。结论不是"多模型一定没用",而是"你问错了问题"。行业一直在问"这些模型有多不同",但真正应该问的是"这些模型同时失败的概率是多少",以及"就算理论上有提升空间,现实中有没有办法实现它"。
对于普通用户和企业决策者来说,这意味着:在决定是否投入多模型系统之前,花一点时间测一测β,看看天花板在哪,可能比反复调优路由策略更有价值。如果你在处理的是开放式数学题、代码生成这类任务,全员失败的问题会真实存在,而它不是多加几个模型能解决的。
真正能帮助系统变得更好的,不是更多的模型,而是能在不同问题上犯不同错误的模型——这个道理听起来简单,但真正去量化它,需要的不是ρ,而是β。有兴趣深入了解的读者可通过arXiv:2606.27288v1获取完整论文。
---
Q&A
Q1:什么是多模型路由系统,普通用户会用到吗?
A:多模型路由系统是指在多个AI模型中自动选择最合适的那个来回答问题的机制,类似于"把问题派给最擅长的专家"。企业用户在部署AI服务时经常用到,比如同时接入GPT、Claude、Gemini等模型,然后根据问题类型自动分发。个人用户目前接触较少,但随着AI应用普及,这类系统会越来越常见。
Q2:β和ρ的区别是什么,为什么β更重要?
A:ρ(rho)衡量的是两个模型犯错的相似程度——它们是不是总在同样的题上出错。β衡量的是所有模型同时全部答错同一道题的概率。区别在于,ρ只反映两两之间的关系,而β反映整个群体的集体行为。由于任何多模型系统都无法"纠正"所有模型同时答错的题,β直接决定了系统准确率的天花板,而ρ根本做不到这一点,甚至在原则上也无法从ρ推算出正确的β。
Q3:开放式问答为什么比选择题更容易让所有AI模型同时答错?
A:选择题提供了有限的选项,模型即便不确定,也能在几个答案里"锁定范围",犯错的方式被约束了。开放式问答没有这个约束,模型需要从零生成答案,面对的不确定性更大。当一道题本身有根本性难点时,这种不确定性会以一种集体同步的方式爆发,导致所有模型同时失败——就像去掉了参考答案提示后,学生们反而会集体往同一个错误方向走偏。