[CL]《Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?》J Kim, X Luo, M Kim, S Lee… [Microsoft Research & Seoul National University] (2026)
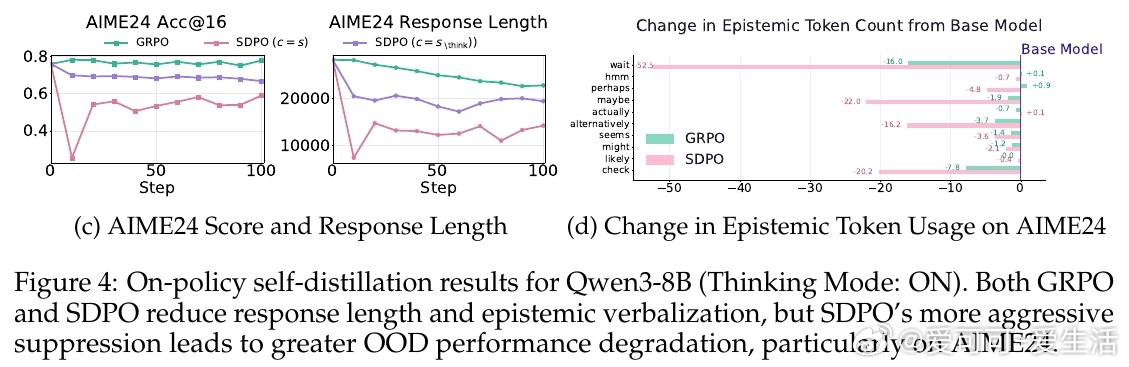
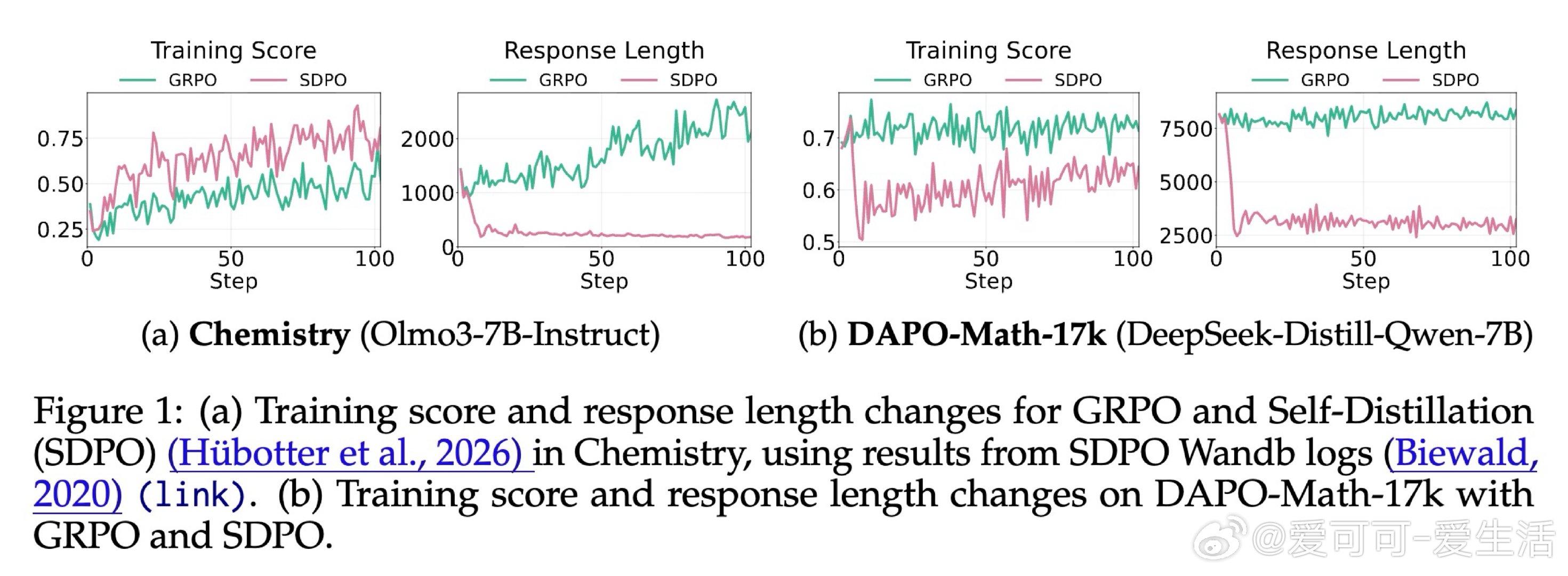
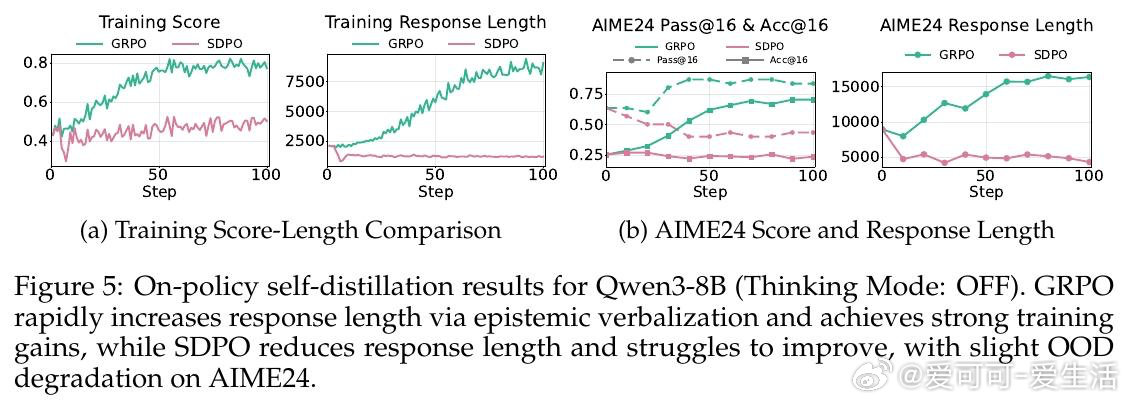
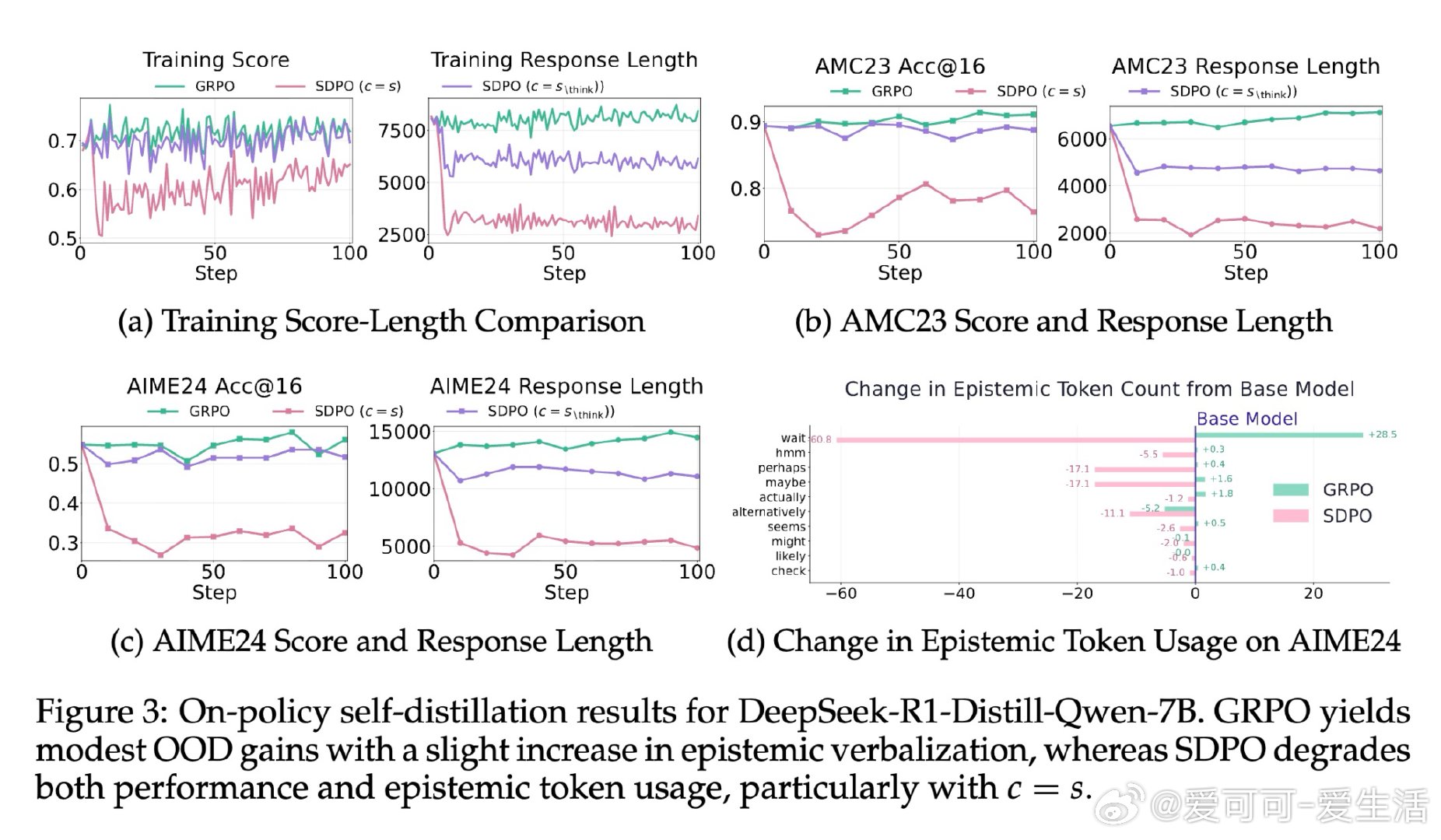
在大语言模型的数学推理领域,自蒸馏训练会缩短推理链路、提升答案准确率,这一认知在科学问答、代码生成等场景中已获广泛验证。然而在数学推理上,同样的方法导致了高达40%的性能下滑——即便模型始终在学习正确答案,退化依然发生。问题的根源,藏在那些看似冗余的词语里:Wait、Hmm、Perhaps。
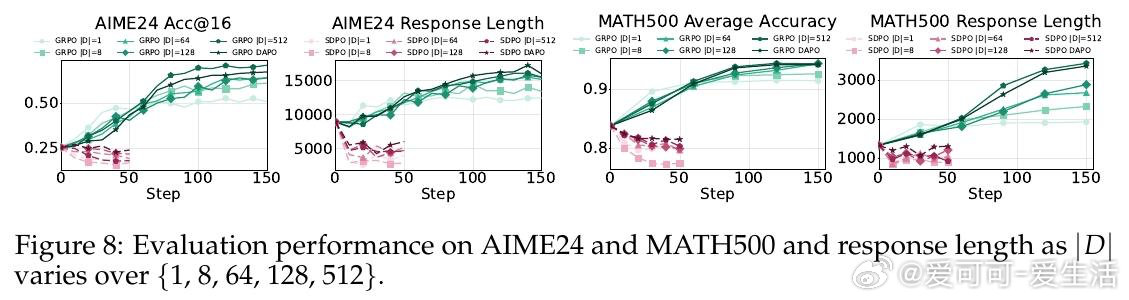
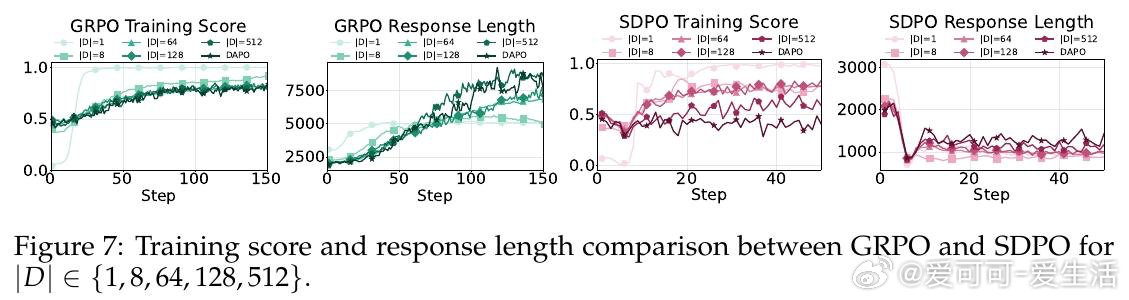
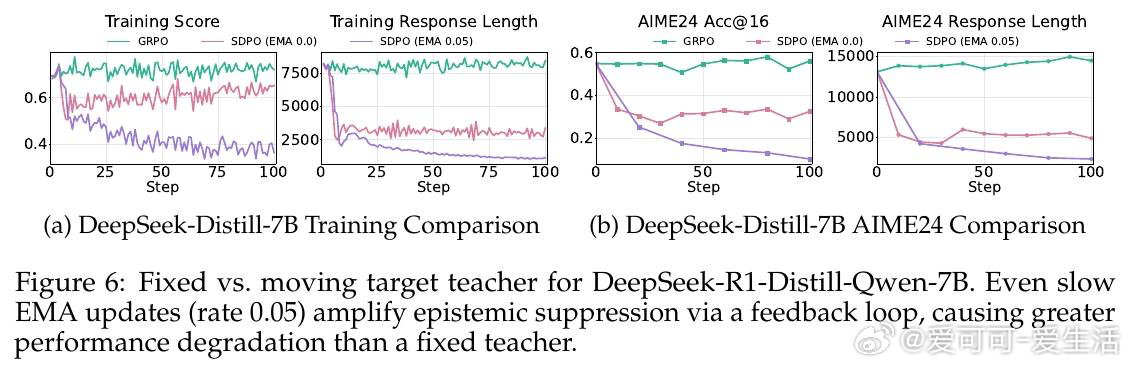
本文的核心洞见是:把"我不确定"的表达重新看作推理系统的校正信号,而非待压缩的冗余噪声。教师模型在已知正确答案的条件下生成推理轨迹时,会自然屏蔽不确定性——输出流畅、简短、自信。学生模型模仿这种风格后,在推理中失去了"遭遇歧路时停下重新评估"的能力。由此,训练集覆盖范围成为分水岭:问题类型单一时,压缩推理有效;一旦面对未见过的题型,缺乏不确定性信号的模型无法调整方向,性能急剧跌落。
这项工作真正留下的遗产是:正确答案的监督信号不足以保障推理能力,推理风格本身也需要被显式地保护。它为后来者打开的新门是重新审视"简洁"作为优化目标的适用边界——在泛化要求高的任务中,认知不确定性的表达是能力而非累赘。但尚未跨过的门槛是:如何在保留必要不确定性表达的同时,真正去除无效冗余,而非在两者之间简单取舍。
arxiv.org/abs/2603.24472
机器学习 人工智能 论文 AI创造营