
编辑|泽南
在医疗健康这一容错率极低的领域,大模型不再凭空「想象」,而是已变得严谨可靠、能引会搜:百川刚刚推出的新模型,实现了一个里程碑式的突破。
本周四,百川智能正式发布新一代大模型 Baichuan-M3 Plus,其面向医疗应用开发者,在真实场景下将医学问题推理能力推向了全新高度。新模型发布的同时,接入 M3 Plus 的百小应 App 与网页版也已同步上线。

在 AI 领域,从来没有一款大模型可以做到 M3 Plus 这么高的医学场景准确率,百川还大幅提升了模型的推理效率,M3 Plus 的发布,标志着 AI 在医疗领域的应用跨过了「敢用、好用、用得起」的关键门槛。
百川智能创始人、CEO 王小川表示,在垂直领域,M3 Plus 已经可以认为是医生版的 ChatGPT 或 DeepSeek,作为性能最强、推理效率最高的模型,可大规模用于 AI 辅助医疗落地。
全球最低幻觉率
从看着像,到真的准
长期以来,医生与患者对 AI 的态度一直存在矛盾:人们既期待 AI 能分担繁重的工作,又恐惧它们「一本正经地胡说八道」。信任,是 AI 进入医疗领域的最后一道墙。
在发布活动中,百川智能模型技术负责人鞠强现场演示了一个案例:一位医生曾尝试用 AI 检查一个肿瘤药物的不良反应,结果发现市面上的 AI 生成的内容虽然「画风」专业,引用文献看起来也很权威,但「按照生成内容的面积计算,90% 的信息都是完全错误的」。
这种「貌似专业」带来的风险比直接答错更大,且极具迷惑性 。
针对这一核心痛点,M3 Plus 延续了 M3 基座模型的内生逻辑机制,通过引入 Fact-Aware RL(事实感知强化学习)等新技术,将幻觉控制推向了新高度。
上周发布的百川新一代基座模型 Baichuan-M3,开拓了幻觉降低的技术路线,探索模型基座的幻觉降低范式,成功首创了 Fact-Aware RL 的强化学习范式,让模型在无工具、无检索增强的情况下大幅降低了幻觉,实现了 SOTA 水平,M3 Plus 延续了这样的能力。

Baichuan-M3 首创的 Fact-Aware RL。
Fact-Aware RL 范式下,模型生成的文本会被拆解成一条条可被核查的医学判断,再逐条和权威医学来源进行比对,进而量化 AI 生成内容的事实准确性。
这种设计赋予了 AI 模型与真实临床工作流程相契合的内在医学增强能力。据测试,Baichuan-M3 不仅在医疗沟通和推理能力上全面领先 GPT-5.2,在医疗幻觉率上也实现了超越,达到全球最低水平。
在 M3 Plus 上,AI 的推理还得到了「六源循证」方法(EAR)的加持。
在去年 10 月发布的 Baichuan-M2 Plus 模型上,百川首次应用了「六源循证」方法(EAR),将循证医学的范式引入大模型的训练和推理过程,使模型的每条建议都有专业医学证据支持。在其 RAG 检索的过程中,查询会被转化为结构化医学问题,并在六源数据库中进行分层匹配。

Baichuan-M2-Plus 提出的六源循证体系。
据介绍,这种方法克服了通用 RAG 的两大缺陷:对医学语义理解的缺乏,以及引用文献可靠性的不足。六源循证不仅使 AI 模型的医学知识储备和医学知识利用能力大幅提升,更直接将幻觉降低到 DeepSeek-R1 模型的 1/3,使模型的可信度达到比肩资深临床专家的水平。
M3 Plus 模型在 Halluciation Rate 评测中的幻觉率只有 2.6,比 GPT-5.2 低超过 30%,也低于目前行业的标杆 Open Evidence,刷新了医疗模型低幻觉世界纪录。
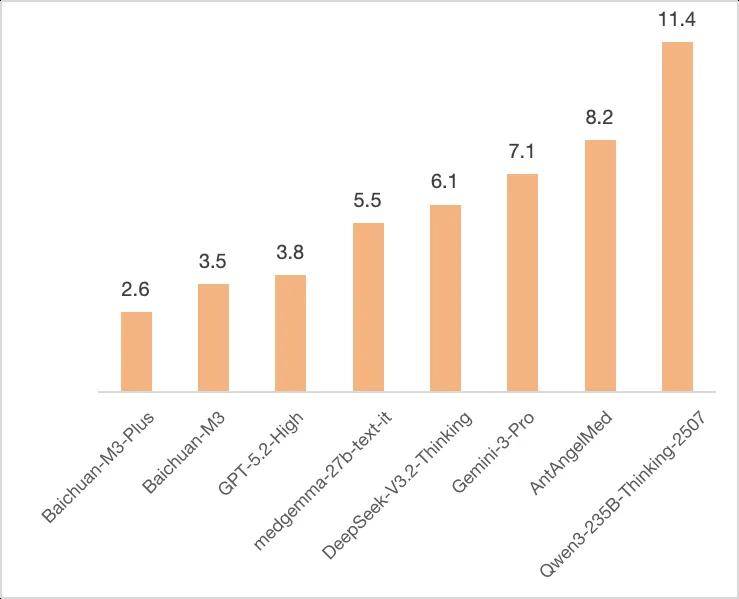
现在,AI 不再生成高频但模糊的建议,而是经过显式训练,系统地抑制了那些「看起来很美」但并无事实依据的回答。
让 AI 的每个医学判断都有据可查
「验证 AI 的回答,比自己查书还累,」这是很多医生使用通用大模型时的抱怨。在医疗场景中,引用是可信度的底线,但在大模型领域中,人们对于 AI 生成内容的引用准确性始终缺乏系统性优化路径。很多大模型列出的引用内容,指向的文献或段落并不支持当前表述,AI 并没有真正理解和呈现证据立场。
为此,百川智能首创了「证据锚定」(Evidence Anchoring)技术,让 AI 生成的每一句医学结论都能被逐句核验。
在 Baichuan M3 Plus 中,引用准确性被作为一个独立且核心的训练目标被进行系统建模。AI 不是简单标注「引用自哪篇文献」,而是被要求生成的每一句医学结论,都必须精确对应到原始论文或指南中的具体证据段落。每一句判断,都能被逐字溯源、逐条核验。
结合专门训练的 Citation Reward Model(引用奖励模型),对错误引用进行明确惩罚,模型现在只能在「确实有证据支持」的空间中推理与生成。最终,结论与证据段落的匹配准确率超过 95%,真正让 AI 的医学判断做到了可核验、可追责、可教学。
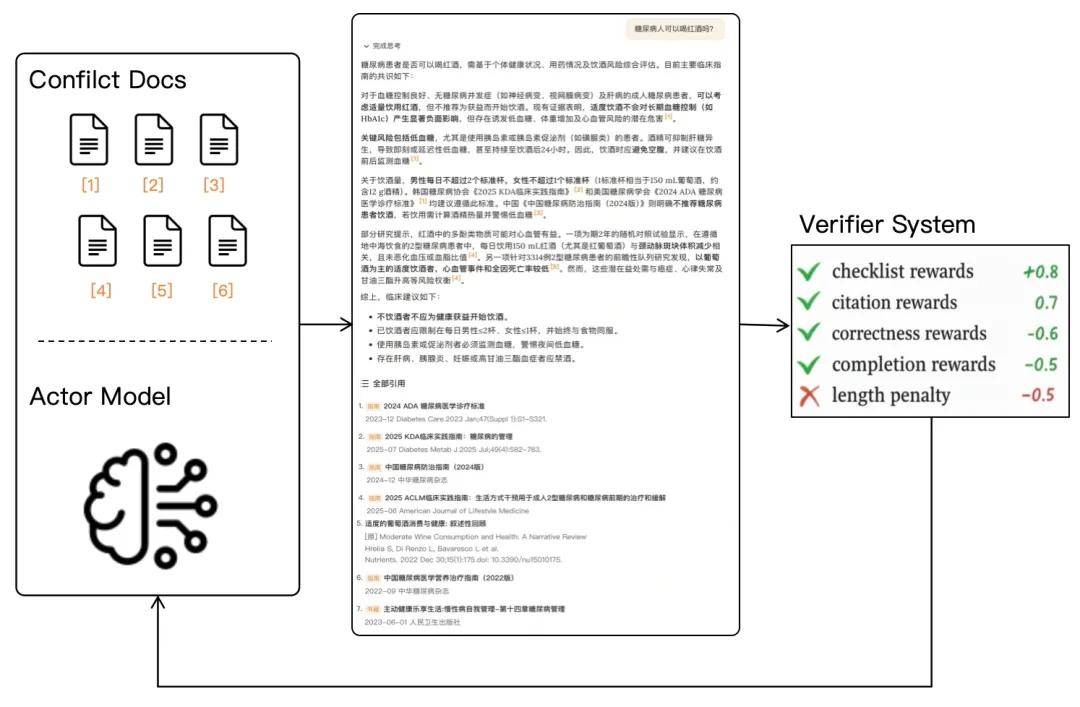
在 M3 Plus 生成的内容中,引用的段落和支持的表述是完全一致的,人们可以直接定位到支持这句话的证据,这样一来,验证来源的权力被交还给了医生。
王小川表示,基于低幻觉的新一代模型,百川希望面向医生提供 AI 辅助能力,并向患者提供建议,「我们认为随着大模型技术的提升,人们对于 AI 辅助的接受度将会逐步提高。同时,这也需要多方面持续努力。」
用免费开放
推动行业共荣
在美国,像 OpenEvidence 这样的 AI 医学知识助手已覆盖了 45% 的医生,但其高昂的订阅费在现阶段的中国市场难以落地 。中国医生面临着截然不同的工作环境:美国医生一天看 10 个病人,中国医生可能要看上百个 。如果要让 AI 真正普及,就不能增加医生的经济负担,也不能指望像 SaaS 软件那样简单收费。
为此,百川给出了更大胆的解法。
百川公布了「海纳百川计划」—— 面向所有为医务工作者提供服务机构,免费提供循证增强的 M3-Plus 的 API。百川希望通过这种方式推动更多服务于医生的 AI 应用落地,让更多医生拥有可用、好用的 AI 工具,推动临床、医学教育的进步。

目前,M3 Plus 也面向所有开发者开放为期 15 天的 API 限时免费体验,所有开发者均可以申请使用。
王小川表示,即使全中国临床医生都在使用 M3 Plus 模型,一年的成本也在可控范围内(约 1 亿元),百川愿意承担这笔费用来催熟生态。
当然在技术层面上,新模型也进行了极致的工程优化。
M3 Plus 围绕医学场景对模型架构、推理路径与部署形态进行了系统的工程重构,在不牺牲模型能力与可靠性的前提下,让 API 调用成本较上一代降低 70%。
该模型完成了两项新型优化工作。首先是 Gated Eagle-3 投机解码框架,它通过门控注意力机制(Gated Attention),可以在几乎不增加计算开销的前提下实现对外部信息流的动态筛选与精细调控,draft 模型能够「有选择地」吸收主模型语义指导,显著提升预测准确率。
就像是有一个教授在带着助教在写诊断书,助教(Draft 模型)先快速写出草稿,教授只负责进行快速审核与修正。M3 Plus 的创新在于让这个助教更聪明,能精准领会教授的意图,从而在不降低论文质量的前提下,让产出速度提升。
在相同配置下,Gated-Eagle3 相比原始 Eagle-3 实现约 15% 的推理吞吐量提升,直接降低单位请求的推理成本。

Gated Eagle3
另外还有面向医学 MoE 模型的极致量化。在部署侧,百川针对 MoE 架构的稀疏激活特性设计了面向医疗场景的定制化的量化方案,并通过专家均匀激活校准避免了 MoE 专家量化失衡。量化之后的 M3 Plus 在主流基准评测和医学效果评测上推理成本下降 30%,同时性能几乎无损。
鞠强表示,在具有最高专业度的同时,M3 Plus 的每 Token 成本比通用的 DeepSeek、千问等模型还要更低。
医疗健康
今年 AI 落地的主战场
「今年是 AI 进入医疗的关键一年,」王小川判断。
事实上,在国内外 AI 领域,今年一开年,就有很多与 AI 医疗相关的大新闻曝出。
1 月 8 日,OpenAI 宣布推出 ChatGPT Health,提供了一个「专门用于与 ChatGPT 进行健康相关对话的独立空间」,连接电子医疗记录和各类健康应用,生成的回复能够结合用户的健康信息与个人情境;1 月 12 日,Anthropic 推出 Claude for Healthcare,使医疗服务提供者、支付方和消费者能够将 Claude 用于医疗用途;在国内,蚂蚁阿福(AQ)作为 AI 驱动的医疗健康应用已经获得了 3000 万的月活用户。
这一方面证明了医疗正在成为 AI 技术落地的核心场景,也证明了百川率先切入医疗赛道的正确性。
不过在应用大模型的方向上,百川选择的路径与很多试图构建 AI 健康助手的玩家有着本质的不同 —— 当很多 AI 应用试图通过连接你的手表和手机,成为你的「健康管家」时,百川选择了一条更艰难、更垂直的道路:直面严肃场景,进入医院核心科室,成为医生的「第二大脑」。
M3 Plus 的发布,标志着中国 AI 公司在垂直赛道上,通过极致的工程化与场景深耕,正在构建起属于自己的护城河。
王小川表示,相信在三年以内,AI 辅助的医疗问诊等应用将会在国内外大规模落地。
加入「海纳百川」计划:https://www.baichuan-ai.com/home?sessionid=