大语言模型的文本生成方式一直都是以自回归为主:一个token接一个token,从左往右,生成完就定了。
但现在有个不太一样的思路开始在研究圈里流行起来,那就是扩散语言模型(Diffusion LMs)。扩散模型在图像生成领域已经证明了自己的可行性,但是问题是把这套东西用到文本上一直很麻烦——训练难、评估难、更别提怎么集成到现有的LLM工作流里了。

dLLM是一个开源的Python库,它把扩散语言模型的训练、微调、推理、评估这一整套流程都统一了起来,而且号称任何的自回归LLM都能通过dLLM转成扩散模型,还不需要什么特殊的算力。
扩散模型用在语言上有什么不同做过图像扩散模型的应该能理解这个思路。
传统自回归是顺序生成,扩散模型的玩法不一样:先从噪声或者masked tokens开始,然后一步步把整个序列细化出来。它不是一个token一个token往后走,而是对整个输出做全局优化。
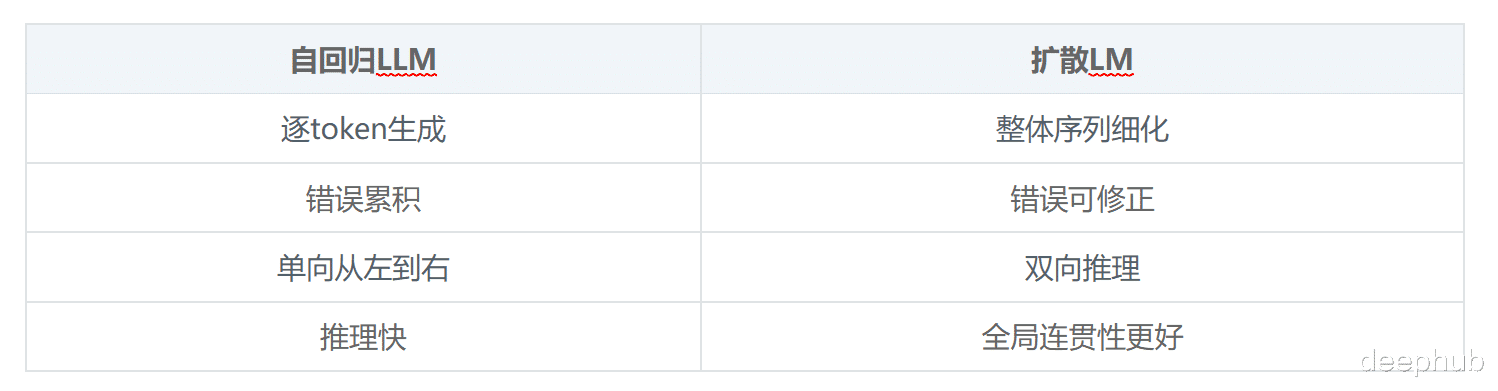
扩散模型在几个场景下表现特别好:需要复杂推理的任务、文本编辑重写、结构化生成,还有需要多轮迭代优化的场景。
dLLM提供了什么dLLM不是某个具体模型它是个框架,包括了下面的功能:
统一的训练流程
底层用的是Hugging Face的Trainer,所以常见的那些东西都支持:LoRA微调、DeepSpeed、FSDP、多节点Slurm集群、4-bit量化。
训练扩散模型和训练transformer没什么区别用的都是同一套工具链。
统一的评估体系
评估部分基于lm-evaluation-harness搭建,好处是不同benchmark用同一套接口,不需要针对每个模型写推理代码,结果也能复现。
把AR模型转成扩散模型
这是dLLM最核心的功能,LLaMA系列模型、instruction-tuned的LLM,甚至BERT这种encoder,都能拿来微调成扩散模型。而且支持的方法包括:Masked Diffusion(MDLM)、Block Diffusion(BD3LM)和Edit Flows。
支持的模型和训练方式dLLM自带了几个参考实现:LLaDA/LLaDA-MoE、Dream、BERT-Chat、Edit Flow模型。训练示例覆盖预训练、监督微调(SFT)、评估这几个阶段。
# Create environmentconda create -n dllm python=3.10 -yconda activate dllm# Install PyTorch (CUDA 12.4 example)conda install cuda=12.4 -c nvidiapip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 \ --index-url https://download.pytorch.org/whl/cu124# Install dLLMpip install -e .
如果要跑评估:
git submodule update --init --recursivepip install -e "lm-evaluation-harness[ifeval,math]"
训练代码实际长什么样最简单的训练脚本:
import transformersimport dllmmodel = dllm.utils.get_model(model_args)tokenizer = dllm.utils.get_tokenizer(model_args)trainer = dllm.core.trainers.MDLMTrainer( model=model, tokenizer=tokenizer, train_dataset=train_data, eval_dataset=eval_data, args=training_args, data_collator=transformers.DataCollatorForSeq2Seq( tokenizer, padding=True, return_tensors="pt", ),)trainer.train()
就这些,不用写自定义loss,不用手动搞扩散循环,也不是那种只能在论文里跑的代码。
还可以使用LoRA + 4-bit量化微调
accelerate launch \ --config_file scripts/accelerate_configs/zero2.yaml \ examples/llada/sft.py \ --num_train_epochs 4 \ --load_in_4bit True \ --lora True
推理怎么做扩散推理是分步骤迭代的和自回归的greedy decoding完全是不同的概念,dLLM用统一的sampler把这层抽象掉了:
import dllmmodel = dllm.utils.get_model(model_args).eval()tokenizer = dllm.utils.get_tokenizer(model_args)sampler = dllm.core.samplers.MDLMSampler( model=model, tokenizer=tokenizer)inputs = tokenizer.apply_chat_template( [{"role": "user", "content": "Explain diffusion models simply."}], add_generation_prompt=True, tokenize=True,)outputs = sampler.sample(inputs)
sampler会处理mask schedule、refinement steps、decoding、output cleanup这些细节。
Edit Flows:拿扩散做文本编辑Edit Flows算是dLLM里比较有意思的一个方向。模型不是从零生成文本,而是学会对现有文本做操作:插入token、删除token、替换token。这种方式特别适合代码重构、文档编辑、可控的文本改写这类任务,而dLLM提供了从头训练Edit Flow模型的完整教程。
评估评估扩散模型确实有点麻烦,dLLM用标准化的脚本解决这个问题。
在MMLU-Pro上跑个评估的示例如下:
accelerate launch --num_processes 4 \ dllm/pipelines/llada/eval.py \ --tasks "mmlu_pro" \ --model "llada" \ --apply_chat_template \ --num_fewshot 0
总结扩散语言模型之前一直停留在研究阶段,dLLM把它变成了能实际用起来的工程工具。现有的LLM可以直接复用,微调需要的算力也不夸张,模型之间的对比有了统一标准,想做实验也不用把整套东西重新搞一遍。
自回归LLM能占主导地位,很大原因是它足够实用。扩散模型要是想在语言领域站稳脚,就要做到训练简单、评估方便、容易集成,dLLM在这个方向上走了不小一步。
对于在做next-gen语言模型的人来说,这个框架确实值得研究一下。
https://avoid.overfit.cn/post/5dc5d844044d404d868bf9512bca2f9b
作者:Sonu Yadav