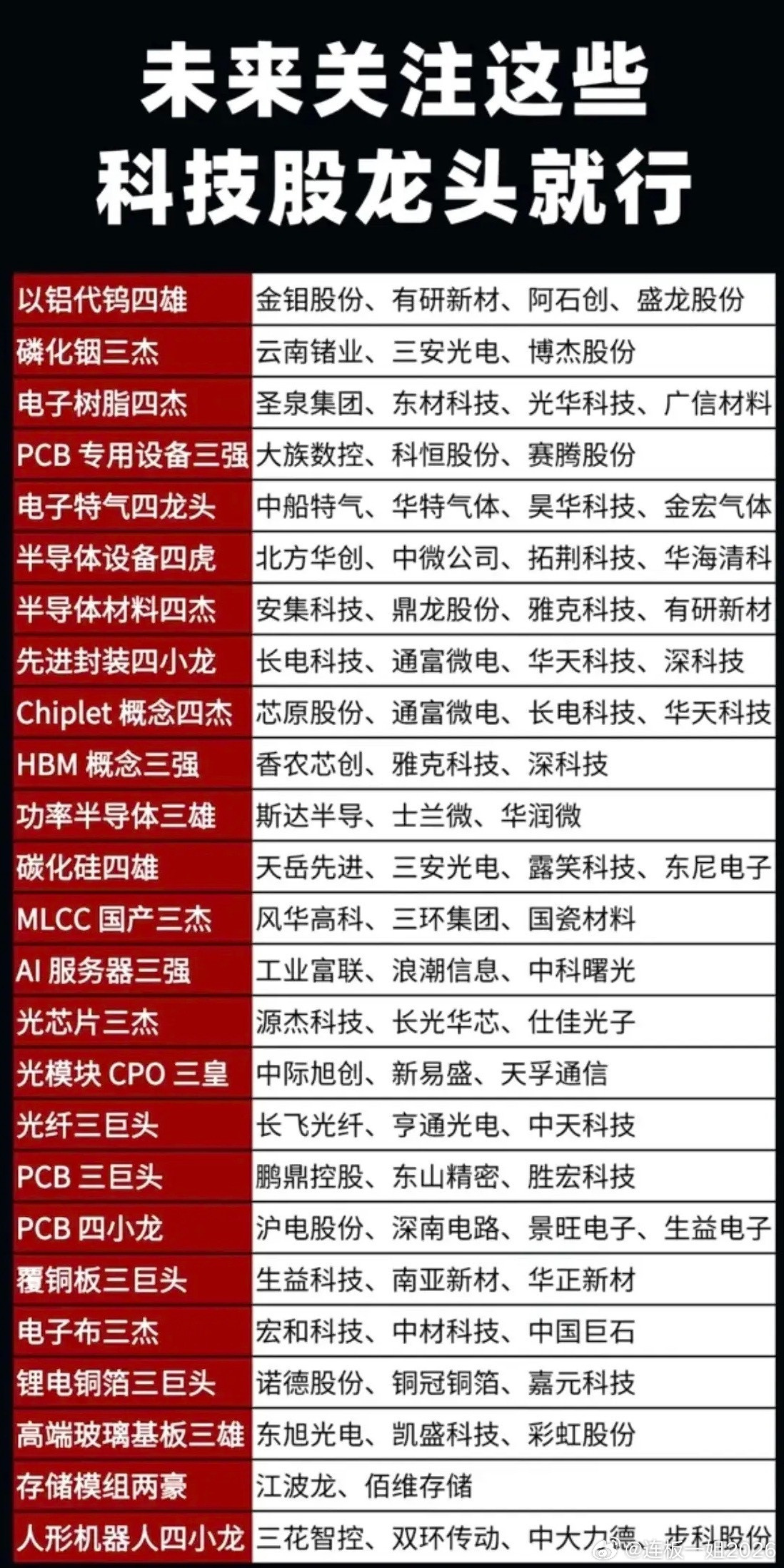
6月22日消息,据外媒Wccftech报道,在HBM产能持续紧缺倒逼存储架构革新的背景下,存储芯片大厂Sandisk(闪迪)近日公布了一项全新专利方案,试图在单一封装内融合NAND Flash的大容量存储优势与HBM(高带宽内存)的高带宽优势,破解AI算力内存墙。
根据SanDisk公布的这项“US 12,430,274 B2”专利描述显示,这一新技术是将基于CBA(CMOS键合阵列)技术构建的NAND Flash模块,通过3D堆叠方式直接置于计算芯片(GPU或AI加速器)之下,并与HBM共封装于同一中介层(interposer)之上,但放置在计算芯片与NAND Flash堆叠的周边,试图构建一种全新的内存-存储层级架构。
需要强调的是,Sandisk这项新的技术方案并非要用NAND Flash取代HBM,而是构建一个协同工作的多层存储体系:HBM负责处理需要即时响应的高速、低延迟内存操作;而NAND Flash则专注于高容量、读写密集型的工作负载和大规模数据集存储。通过在计算芯片与NAND Flash之间建立更宽的连接通道,该设计旨在降低数据传输延迟、节省功耗,并降低整体系统成本。

当前,AI训练与推理高度依赖HBM提供高带宽数据吞吐,但是HBM正面临多重现实瓶颈:产能扩充速度跟不上需求、单堆栈容量仅32GB至64GB、成本居高不下,且与主芯片并列的设计仍存在物理延迟。与此同时,NAND Flash虽具备成本低、容量大(单堆栈可扩展至4TB)的优势,但传统上它远离计算芯片,数据传输速度仍与DRAM存在代差。
为融合二者优势,Sandisk此前已提出HBF(高带宽闪存)方案,其架构类似于HBM,通过硅通孔(TSV)垂直堆叠多层NAND Flash,目标是将单堆栈容量提升至4TB。而Sandisk此次公布的新专利,则是其HBF路线图上的进一步延伸,提出了更具整合性的实施方案。
尽管这一构想描绘了未来AI计算存储架构的可能性,但业界普遍认为,它目前仍是一项长期的技术规划,距离商业化尚远。要实现处理器与多层NAND Flash的紧密堆叠,功耗控制、散热(特别是将NAND Flash置于高功耗GPU之下)、封装复杂度以及良率都是巨大的工程挑战。
编辑:芯智讯-浪客剑