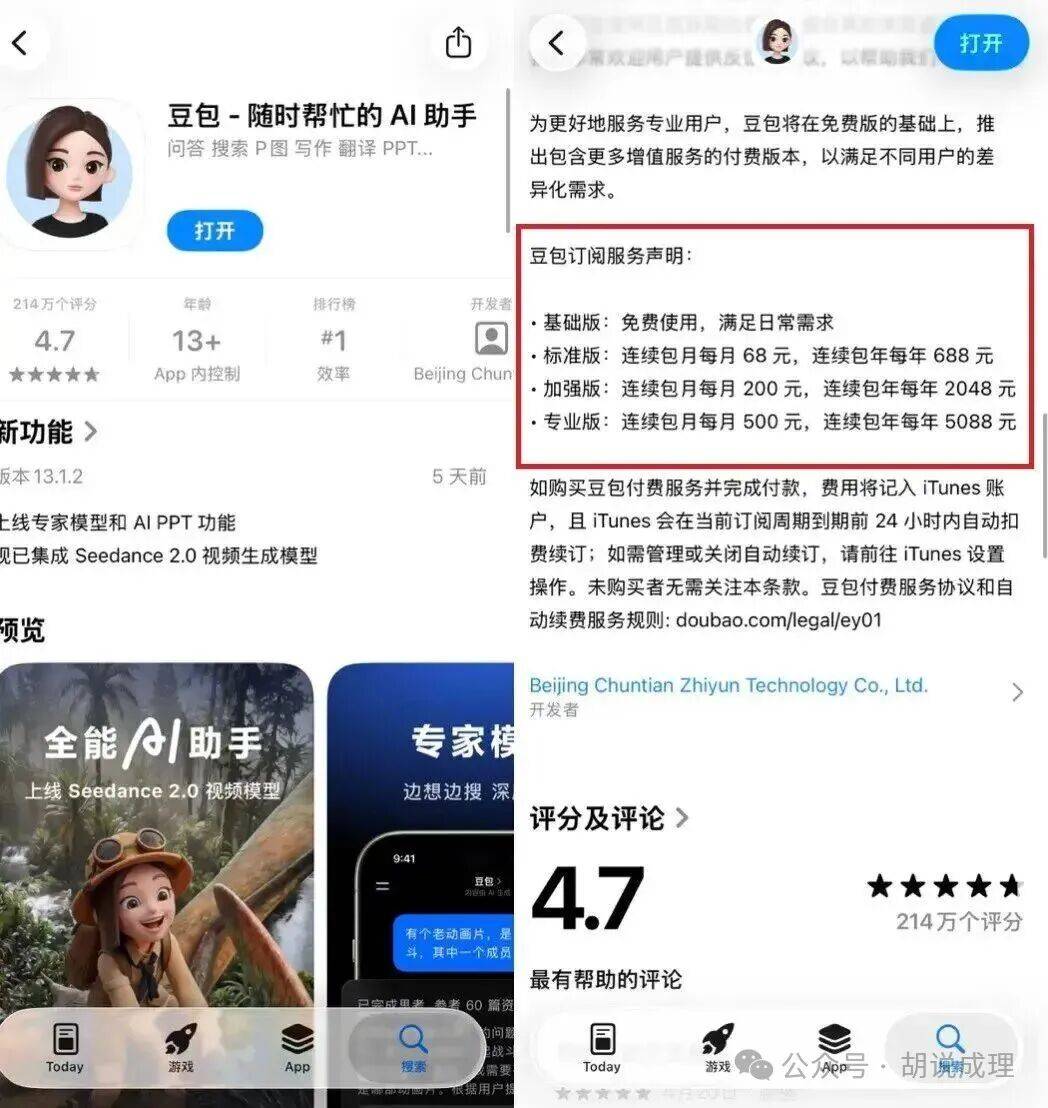
这个五一假期最大的惊吓就是,假期的最后一天,豆包发布了收费的消息。
这个消息的意义就是,国内大模型应用,单纯依靠免费换规模的阶段终结了。
再说一个判断,这个趋势将是不可避免和无法逆转的,而且很快会蔓延到全行业。人人为AI付费的时代到来了。
那这个趋势最终意味着什么?以及,它和最近发布的DeepSeek V4的核心价值,有何关联?
——导语
01豆包收费,这事意味着什么?肯定有很多人对豆包收费感到不满。因为大家觉得,这次又是一次经典的先靠免费收割用户,形成使用习惯后,再用收费来割韭菜的操作。
经典互联网时代的操作,大家都很熟悉了。
不能说这种看法全无道理,但这里,我虽然不是替豆包辩解,但我也不认为豆包应该被批评。
因为这件事的底层逻辑就是,免费模式的大旗,豆包不愿意扛了,也没有必要扛了。
注意,不愿意扛,和扛不住,是两个概念。
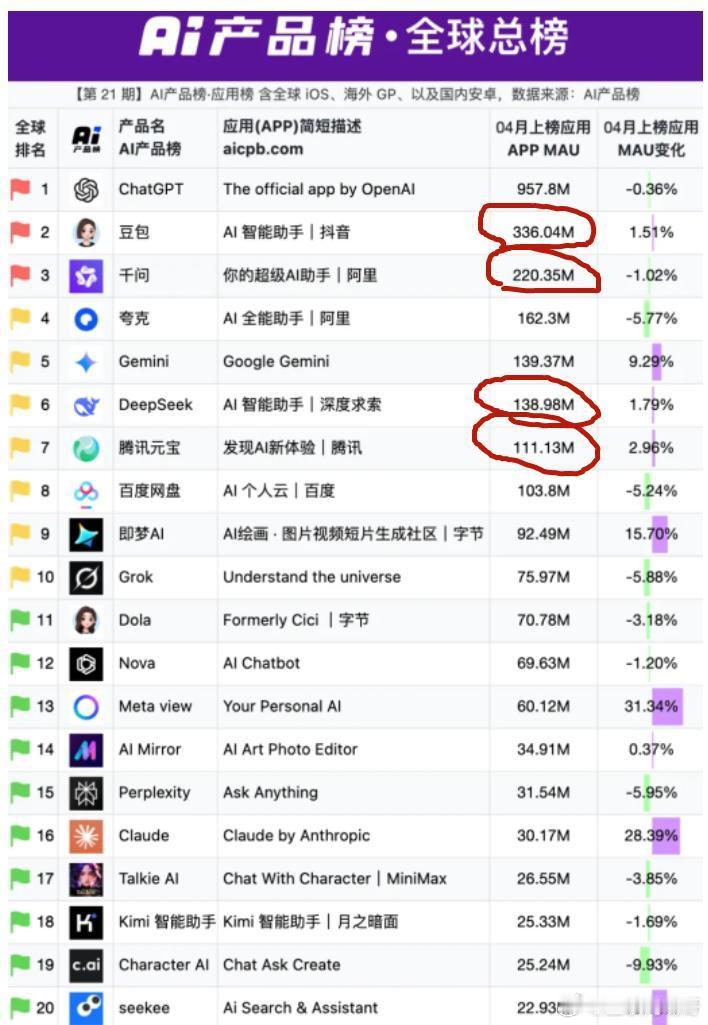
截至2026年第一季度,豆包的月活用户为3.45亿,这是第三方数据。

这个数字很漂亮。但背后冰冷的事实就是,如按2026年3月的这个统计口径,豆包日均Token使用量突破120万亿,相比其2024年5月首次推出时,增长超过1000倍。
据测算,如果豆包继续免费,一年的成本在37-45亿元之间。请注意,这个测算是基于3月份的用户数据,而现在已经是5月了。
也许你会问,相对于2025年字节650亿人民币左右的净利润,三四十亿的成本就是个零头,字节完全扛得住啊,为啥要收费?
但问题是,人家豆包的帐不是这么算的:
第一笔账,三四十亿,只是表面成本。
严格说,这里面只包含了模型研发迭代的成本和用户的消耗。而且,这只是一个今年3月的静态数字。
现在有两个趋势很明显。一个是,用户使用AI的深度越来越深,很多人把AI已经嵌入了自己的工作流、生活场景。另一个是,个体使用AI的时长不断提升。
加之,现在大模型竞争压力、迭代压力越来越大,研发费用的投入只会越来越大。
所以,“三四十亿”这个数字,在6个月内飚过100亿,是眼前就能看到的。
到时候还免费吗?
第二笔账,是你看不到的背后成本。
大家都承认豆包反应很快、输出很流畅,覆盖生活需求完全没问题。但有没有想到,为了提供这些能力,字节做的基础设施建设,可是非常耗费金钱的。公开的数据显示,字节2025年全年资本支出约1500亿人民币,其中大部分投向来AI基础设施;2026年的预算更激进:资本支出预算约1600亿人民币,其中850亿人民币专门用于AI芯片采购。
这才是免费模式给字节压力越来越大的底层原因。
第三笔账:字节不是第一个吃螃蟹的。
在此之前,不管是海外的ChatGPT、Gemini、Claude等模型都实现了订阅,国内的头部模型如Kimi(49元/月)、智谱(49元/月)也都开始了收费。
字节有必要做一个"不合群"的免费者吗?没必要。而且,既然它想收,就一定收得上来。那么,干嘛不收呢?
顺便做个预测,目前头部大模型企业,特别是巨头,比如千问、百度、元宝,只要在牌桌上的,只要提供全民免费服务的,陆续都会开启收费模式。这绝对不是我故作惊人语。
豆包收费咋和DeepSeek V4扯上关系了呢?
很简单,DeepSeek V4代表着这样一种路线——它没法单枪匹马阻止AI收费时代的到来,但它可以降低或延迟我们为AI付费的“痛”。
一个大家喜欢讨论的问题是,为什么在这次模型性能不算惊艳的情况下,很多人仍说DeepSeek V4是国运级产品?
我认为,这主要是它带来了AI的成本革命,并且在这条路上走的更远了。
V4上线才两天,直接两轮连环降价。先全系输入缓存命中价格砍到首发价的十分之一,再给Pro版本打了个2.5折。结果就是,V4-Flash的百万Token缓存命中输入,硬生生压到人民币两分钱。

它终于让大规模跑Agent这件事,从"用不起"变成了"随便跑"。
但便宜,不等于是廉价。降本,靠的其实是DeepSeek的技术领先。V4-Pro处理百万Token的推理算力,只有上一代的27%。最核心的MoE架构,总参数1.6万亿,每推理一次只激活1.6万亿参数里的3%(约490亿参数),单次算力需求砍掉了97%。
我举个例子,大模型就像一个有一万盏灯泡的体育场。以往,哪怕场里只有你一个人,为了给你照亮,它可能就要亮起几百盏甚至几千盏灯。
DeepSeek做的就是智能化的灯光管理。如果照亮你只需要3盏灯,那剩下9997盏就不会亮起。它追求的是满足你的需求的前提下,用极致的智能来实现成本的最优。
我们算个细账。目前,在同等百万Token基准下对比:Claude Opus 4.7仅输入就高达5美元,输出另算25美元;而DeepSeek V4-Flash叠加缓存命中后的价格低至0.02元/百万Token——按汇率不那么严格的换算,这个差距意味着:在缓存命中时,V4-Flash的成本可以压到Claude Opus 4.7的两千分之一。
这意味着什么?意味着即使AI全面收费时代到来,你仍然可以用一个相对合理的成本使用AI。而使用AI,是未来每个个人的基本竞争力,也是国家的竞争力。
还有一点极为重要的是,DeepSeek V4是在国产硬件上跑起来的。
告诉大家一个行情信息,由于供不应求,英伟达H100一年期GPU租赁合同价格,已经从2025年10月的每GPU每小时1.70美元的低点飙升至2026年3月的每GPU每小时2.35美元,涨幅近40%。
但与此同时,V4首发即适配华为昇腾超节点全系产品,昇腾950超节点计划也在2026年Q4批量上市,实现8192卡规模组网,FP8精度下算力达到8 EFLOPS,训练性能较上一代提升17倍,推理性能提升26.5倍。
换言之,DeepSeek不仅用技术在降本,也在生态上通过部署国产硬件在降本。能够做到这两头一起用力极致压缩成本的,目前DeepSeek是绝对的领先。
未来的AI就是数字时代的基础设施。而基础设施只有足够大、足够多,才能产生社会效益,而大的前提,又是必须做到足够便宜。所以,给V4一个国运级的评价,一点都不为过。
03AI的人人付费时代终将到来,但可能没有你想的那么可怕最近有一种悲观的论调,认为将来人们会分为"用得起收费AI"和"用不起收费AI"两个群体,它们之间的竞争力会越拉越远。
这个结论放到两个个体的对比上或许成立,但放大到社会层面,我认为不太可能。
当互联网开始普及时,早期网民最大的开支确实是网费;移动互联网时代,早期的流量费也是让人心惊肉跳。
但今天还有人会为每个月百来块的网费或者几十块的流量套餐叫苦吗?不会,因为网络建设的早期成本已经摊薄殆尽,用户规模反而大了几十倍、几百倍,所以运营商有足够的降价空间和利润空间。
我认为,未来我们甚至会忘记互联网这个概念,只有云侧和端侧。
你未来所使用的一切数字服务,本质都是AI服务,都是Token经济,你使用的每一项功能,每一个操作,每一个行为,都是AI在调度、在服务、在网线上流淌、在端侧运行。

在那个时代到来时,基础的、免费的AI服务的水准,会比现在的付费高级会员高很多,但价格基本会降到今天电话费、宽带费的标准。而你真正需要付费的可能是一些极高水准的AI能力,是那些深入嵌套在你的工作流、生活场景里的刚需性通用人工智能顶级能力。
这一切都会在未来的十年到二十年里陆续到来。这不是一个幻觉——人们已经总结出了一些规律,如清华大学团队发表在Nature Machine Intelligence上的研究就提出了"模型密度定律”——大模型的智能密度每100天提升一倍。
这意味着什么?同等能力的模型,在3.3个月后仅需要一半的参数就能实现。
简单说,它将和硬件侧的摩尔定律一起,为我们画出一条AI性能持续提升但成本持续下降的可预期曲线。
实证数据已经摆在那里——GPT-3.5级别的模型API价格,在20个月内下降了266.7倍,但它依然有人在用。未来人们用AI会越来越务实,不是追求顶级模型的顶级版本,而是自然适配按需使用。
所以,我的总结是,付费时代没什么好怕的。如果真正要怕什么,那可怕的是——付费了却得不到应有的进步——那才是真割韭菜。
结语豆包用自己的行为证明了,大模型的C端付费时代已经开启。
DeepSeek则用V4证明了,我们可以用国产的硬件,提供极具竞争力的AI能力。
DeepSeek官方发布V4的文章最后引了一句《荀子》的话,"不诱于誉,不恐于诽,率道而行,端然正己。"
它的意思是,不被赞誉收买,不被非议吓退,沿着自己认定的路走,端正地做好自己。
这句话,放在今天这个时间点,再读一遍,份量完全不同。它就是中国AI产业该走的那条路。